
Summary: XGBoost is a highly efficient and scalable Machine Learning algorithm. It combines gradient boosting with features like regularisation, parallel processing, and missing data handling. Widely used across industries and competitions, it excels in predictive modelling, offering unmatched accuracy, speed, and flexibility for structured and complex datasets.
Introduction
Boosting is a powerful Machine Learning ensemble technique that combines multiple weak learners, typically decision trees, to form a strong predictive model. Gradient boosting enhances accuracy and reduces bias by iteratively correcting errors made by previous models. Its flexibility and performance make it a cornerstone in predictive modelling.
XGBoost, or eXtreme Gradient Boosting, is a highly efficient, scalable, and accurate implementation of gradient boosting. Its “eXtreme” label reflects its superior speed, optimisation, and features like parallel processing and regularisation. This blog explores XGBoost’s unique characteristics, practical applications, and how it revolutionises Machine Learning workflows.
Key Takeaways
- It handles large datasets with multi-threading and distributed computing.
- It reduces overfitting using L1 and L2 penalties.
- XGBoost natively manages missing values efficiently.
- It supports custom objective functions and metrics for diverse applications.
- XGBoost excels in finance, healthcare, marketing, and fraud detection.
Key Features of XGBoost

XGBoost (eXtreme Gradient Boosting) has earned its reputation as a powerful and efficient Machine Learning algorithm. Its unique features make it a top choice for tackling complex problems with huge datasets. Here are some key capabilities that set XGBoost apart.
Scalability
XGBoost excels at handling large datasets and performing well in distributed computing environments. It supports multi-threading, allowing it to process massive data volumes quickly and efficiently. This scalability ensures that the algorithm remains reliable whether you’re working on a single machine or a large-scale distributed system, making it suitable for real-world big data applications.
Regularisation Techniques
One of XGBoost’s standout features is its ability to control overfitting using L1 (Lasso) and L2 (Ridge) regularization techniques. By incorporating these penalties directly into its objective function, XGBoost reduces the likelihood of overly complex models that fail to generalise on unseen data, leading to better, more robust predictions.
Parallelisation
XGBoost optimises training speed through parallel tree construction. Unlike traditional boosting algorithms, XGBoost splits data across multiple cores, allowing trees to grow simultaneously. This parallel processing significantly reduces computational time, making the algorithm faster while retaining accuracy.
Sparsity Awareness
XGBoost is inherently designed to handle missing values in datasets. It identifies the optimal path for missing data during tree construction, ensuring the algorithm remains efficient and accurate. This feature eliminates the need for preprocessing steps like imputation, saving time in data preparation.
Customisation
XGBoost offers unparalleled flexibility by allowing users to define custom objective functions and evaluation metrics. This adaptability enables the algorithm to cater to specific problem requirements, making it a versatile tool for various Machine Learning tasks.
These features collectively make XGBoost a robust, high-performance tool for modern Data Science challenges.
How XGBoost Works
XGBoost (eXtreme Gradient Boosting) is a powerful Machine Learning algorithm that builds upon the principles of gradient boosting. It enhances the efficiency, accuracy, and speed of traditional gradient-boosting techniques with innovative improvements. Let’s explore the mathematical foundation, unique enhancements, and tree-pruning strategies that make XGBoost a standout algorithm.
Gradient Boosting Mechanism
XGBoost operates by iteratively building decision trees, each focusing on correcting errors made by its predecessors. It minimises a loss function by calculating gradients (the first derivative of the loss) to guide improvements. In each iteration, a new tree is added, and predictions from all trees are combined to form a stronger model.
Mathematically, XGBoost optimises the following objective:
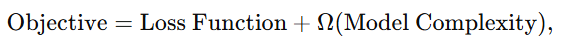
Where Ω\OmegaΩ includes regularisation terms to prevent overfitting, the algorithm fits residual errors in each step and applies shrinkage through a learning rate to ensure steady improvement.
XGBoost’s Unique Enhancements
XGBoost introduces a weighted quantile sketch technique for tree construction. Unlike traditional methods that use simple split-point selection, this technique efficiently handles weighted datasets, ensuring more precise splits for complex data distributions.
XGBoost also incorporates scale_pos_weight, a parameter that adjusts the impact of positive and negative samples in the loss function. This feature makes it ideal for datasets with class imbalances, such as fraud detection or rare event prediction.
Tree Pruning Strategy
XGBoost uses a “maximum depth” parameter to limit tree complexity and avoid overfitting. Additionally, it applies a “minimum loss reduction” criterion (γ) for pruning. A node is only split if the resulting reduction in loss exceeds γ. This ensures that only meaningful splits are retained, optimising model efficiency and interpretability.
These techniques collectively make XGBoost faster, more robust, and highly accurate.
Advantages of XGBoost

XGBoost has emerged as one of the most popular Machine Learning algorithms due to its remarkable efficiency, accuracy, and versatility. Its design and implementation make it a go-to choice for beginners and seasoned Data Scientists. Let’s explore the key advantages of XGBoost in detail.
Speed and Efficiency in Handling Big Data
XGBoost is built with performance in mind. It employs techniques such as parallel processing and hardware optimisation to reduce computation time significantly. Its ability to handle distributed systems allows it to process massive datasets seamlessly. This speed and scalability make it particularly effective for real-world applications where timely predictions are critical.
Better Accuracy Compared to Traditional Algorithms
One of XGBoost’s defining strengths is its capacity to achieve higher accuracy than traditional Machine Learning algorithms. Its use of advanced gradient boosting techniques and features like regularisation leads to robust models that generalise well. As a result, XGBoost often outperforms algorithms like Random Forest or traditional linear models in competitions and practical applications.
Flexibility with Hyperparameters and Objectives
XGBoost offers a wide range of hyperparameters, enabling users to fine-tune the algorithm to suit specific datasets and goals. It supports multiple objective functions, including classification, regression, and ranking tasks, allowing customisation for unique problem statements. This flexibility is a key reason why it’s favoured across diverse domains.
Community Support and Active Development
With a thriving community and strong backing from developers, XGBoost continues to evolve. Regular updates, detailed documentation, and widespread tutorials ensure that users have ample resources to troubleshoot and innovate. The active development ensures it stays competitive with emerging algorithms.
These advantages solidify XGBoost’s reputation as a Machine Learning powerhouse, making it an essential tool for data-driven decision-making.
Applications of XGBoost
XGBoost has established itself as a powerful tool across industries and competitions due to its efficiency, scalability, and accuracy. Its ability to handle large datasets, missing values, and complex relationships makes it ideal for real-world applications and competitive Machine Learning challenges.
Finance
It is widely used in the financial sector for risk assessment, credit scoring, and stock price prediction. Its robustness in handling imbalanced datasets makes it ideal for detecting fraudulent transactions and minimising false positives.
Healthcare
It excels in predictive modelling for disease diagnosis, patient readmission prediction, and optimising treatment plans in healthcare. Its capability to process heterogeneous data (e.g., lab results and patient history) ensures reliable predictions in critical scenarios.
Marketing
Marketers leverage XGBoost to enhance customer segmentation, predict churn, and optimise ad targeting. Its feature-important metrics help businesses identify the key factors influencing customer behaviour and driving personalised marketing strategies.
Fraud Detection
XGBoost’s high accuracy and fast computation make it a favorite for fraud detection in industries like banking and e-commerce. It efficiently identifies patterns of fraudulent activities, even in high-dimensional data.
Competitions
XGBoost dominates Kaggle competitions, consistently ranking among the top-performing models. Its efficiency and flexibility enable competitors to fine-tune models for various datasets and objectives. The algorithm’s ability to uncover intricate patterns and relationships ensures its popularity in Data Science challenges.
Comparison with Other Algorithms
Machine Learning practitioners often compare XGBoost with popular algorithms like Random Forest, LightGBM, and CatBoost. Each algorithm has strengths and weaknesses, making them suitable for different scenarios. Understanding their differences helps in selecting the right tool for specific use cases.
XGBoost vs. Random Forest
XGBoost and Random Forest (RF) fundamentally differ in their predictive modelling approach. Random Forest builds multiple decision trees independently using bootstrapped datasets and aggregates their outputs through bagging (averaging or voting). This ensemble approach reduces variance and prevents overfitting, making RF ideal for small datasets or situations with noisy data.
XGBoost, on the other hand, employs boosting, where trees are built sequentially, with each tree correcting errors from the previous one. This iterative process improves accuracy but makes XGBoost more computationally intensive.
While RF is easier to implement and tune, XGBoost often performs better in structured data problems by leveraging regularisation, efficient handling of missing values, and advanced optimisation techniques.
Use XGBoost for tasks requiring high accuracy and interpretability. Opt for Random Forest when you prioritise simplicity or have limited computational resources.
XGBoost vs. LightGBM
XGBoost and LightGBM are gradient boosting frameworks but differ in tree construction and performance trade-offs. LightGBM uses a leaf-wise tree growth strategy, splitting the leaf with the highest loss reduction, often leading to deeper trees and faster convergence. XGBoost employs level-wise growth, ensuring balanced trees less prone to overfitting.
Regarding speed and memory efficiency, LightGBM outperforms XGBoost due to optimisations like histogram-based binning and GPU acceleration. However, XGBoost remains more robust for small datasets or cases with diverse data types. LightGBM may struggle with overfitting in smaller datasets, requiring careful tuning of parameters like min_child_samples.
Choose LightGBM when working with massive datasets requiring faster training. Use XGBoost for applications demanding fine-grained control over the modelling process.
XGBoost vs. CatBoost
XGBoost and CatBoost differ primarily in their treatment of categorical data. CatBoost natively handles categorical features without requiring one-hot encoding, using a technique called ordered boosting. This approach prevents data leakage and reduces memory usage, giving CatBoost an edge in datasets with numerous categorical variables.
CatBoost also boasts faster training with default parameters than XGBoost, thanks to its gradient-based leaf estimation and automatic hyperparameter tuning. However, XGBoost excels in flexibility and community support, offering a broader range of customisation options.
Use CatBoost for datasets with rich categorical features or when seeking out-of-the-box efficiency. Opt for Gradient Boosting for more complex, highly tuned models requiring detailed parameter optimisation.
Understanding these distinctions enables informed algorithm selection, ensuring optimal performance tailored to the specific needs of your project.
Practical Implementation of XGBoost
Implementing XGBoost in a real-world project involves installing the library, understanding its key parameters, and effectively training and evaluating the model. This section provides practical insights and tips for each step.
Installation and Setup
Installing XGBoost is straightforward. You can use either pip or conda, depending on your package management preference:
- Using pip

- Using conda

Ensure you have the latest version of Python and a functional environment for seamless installation. Once installed, verify it by importing the library:

Key Parameters
XGBoost offers a wide array of hyperparameters, allowing you to fine-tune the model for optimal performance. Here are some key parameters:
- learning_rate: Determines the step size for each iteration. Lower values (e.g., 0.01) provide better accuracy but require more iterations.
- max_depth: Controls the maximum depth of the decision tree. Higher values increase complexity but risk overfitting.
- n_estimators: Specifies the number of boosting rounds. Increasing this value may improve accuracy but can lead to longer training times.
- subsample: Fraction of samples used for training each tree. Values less than 1.0 prevent overfitting.
- colsample_bytree: Fraction of features used for constructing each tree. Useful for high-dimensional data.
Adjusting these parameters based on the dataset and problem type is essential for achieving optimal results.
Training and Evaluation
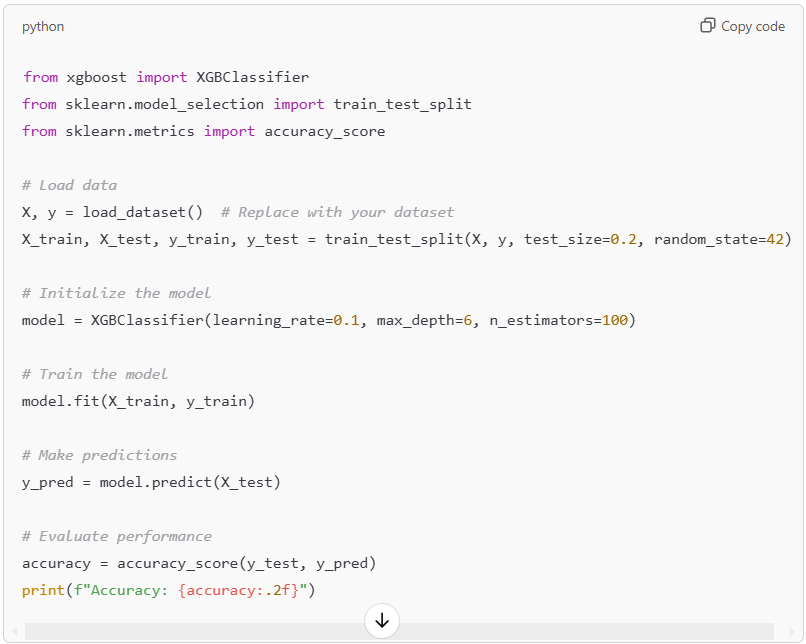
Here’s a basic implementation of XGBoost using Python and scikit-learn:
Tips for Hyperparameter Tuning
Here are the tips for hyperparameter tuning. Following these tips, you can implement and optimise XGBoost for any Machine Learning project.
- Start with Default Values: Begin with default settings and evaluate performance.
- Use Grid Search or Randomised Search: These techniques automate hyperparameter tuning.
- Monitor Overfitting: Use techniques like early stopping and cross-validation to avoid overfitting.
- Adjust Incrementally: Change one parameter at a time to observe its impact.
Following these steps, you can implement and optimise XGBoost for any Machine Learning project.
Challenges and Limitations
While XGBoost is a powerful and widely adopted Machine Learning algorithm, it has challenges. Understanding its limitations is essential to using it effectively in your projects and avoiding common pitfalls. Below are the key challenges associated with Extreme Gradient Boosting.
Computational Cost for Extremely Large Datasets
XGBoost, though optimised for speed and efficiency, can become computationally expensive when handling massive datasets. The algorithm requires substantial memory and processing power, especially when building deep trees or fine-tuning hyperparameters. This can challenge practitioners with limited computational resources, such as standard CPUs or memory-constrained environments.
Overfitting with Improper Tuning
XGBoost’s flexibility with hyperparameters is a double-edged sword. If hyperparameters like learning rate, max depth, or n_estimators are not appropriately set, the model risks overfitting, leading to poor generalisation of unseen data. Regularisation techniques such as L1 and L2 help mitigate this risk, but careful tuning and validation are essential to balance model complexity and performance.
Competition from Newer Gradient Boosting Techniques
Although XGBoost has been a leader in Machine Learning competitions, newer algorithms like LightGBM and CatBoost offer similar capabilities with better speed and efficiency in specific scenarios.
LightGBM, for example, boasts faster training on large datasets, while CatBoost excels in handling categorical data with minimal preprocessing. Users must weigh these options based on their specific requirements.
Future of XGBoost
XGBoost has revolutionised Machine Learning with its efficiency and accuracy. XGBoost continues to adapt as the field evolves, incorporating new features and integrations that ensure its relevance. Let’s explore what lies ahead for this powerful algorithm.
Upcoming Features and Enhancements
The XGBoost team consistently focuses on improving usability and performance. Upcoming features include better support for distributed training, enhanced GPU acceleration and optimised sparse data handling.
These improvements further reduce training time while maintaining model accuracy, making XGBoost even more appealing for large-scale applications. The development roadmap also emphasises enhanced support for high-dimensional datasets, catering to the growing complexity of modern data.
Advancing AI and Machine Learning
XGBoost is pivotal in advancing Machine Learning by enabling faster experimentation and delivering state-of-the-art results in various domains. It simplifies the process of training complex models while promoting reproducibility and scalability. By efficiently addressing overfitting and computational challenges, XGBoost contributes to the broader adoption of AI across industries like healthcare, finance, and autonomous systems.
Integration with Deep Learning Frameworks
Efforts are underway to enable seamless integration of XGBoost with deep learning frameworks such as TensorFlow and PyTorch. These integrations allow hybrid models that combine the strengths of gradient boosting and neural networks, opening up possibilities for tackling diverse, multi-modal datasets with unmatched accuracy.
In Closing
XGBoost revolutionises Machine Learning with its scalability, accuracy, and versatility. Its innovative features, such as regularisation, parallel processing, and robust handling of imbalanced and missing data, make it ideal for diverse applications. Whether used in industry or competition, Extreme Gradient Boosting consistently outperforms traditional algorithms, cementing its position as a cornerstone in predictive modelling.
Frequently Asked Questions
What makes XGBoost Faster than Traditional Algorithms?
XGBoost accelerates training speed by using parallel processing, hardware optimisation, and efficient tree pruning. It effectively processes large datasets, making it a preferred choice for real-world applications.
How does XGBoost Handle Missing Data?
XGBoost’s sparsity-aware design automatically identifies the best path for missing values during tree construction, eliminating preprocessing steps like imputation.
Why is XGBoost Ideal for Imbalanced Datasets?
XGBoost adjusts to imbalanced datasets with parameters like scale_pos_weight, balancing class weights in the loss function. This ensures better predictions for rare events.
Authors
-

Written by:
Julie BowieReviewed by:



