Summary: Machine learning enables computers to learn from data and make smart decisions without explicit programming. This blog explores its types, real-life applications, challenges, and potential. It also highlights how learning ML through platforms like Pickl.AI can empower you to enter the growing field of data science.
Introduction
Imagine teaching a child to recognize animals. You show them pictures of cats and dogs, tell them which is which, and they start to identify them on their own.
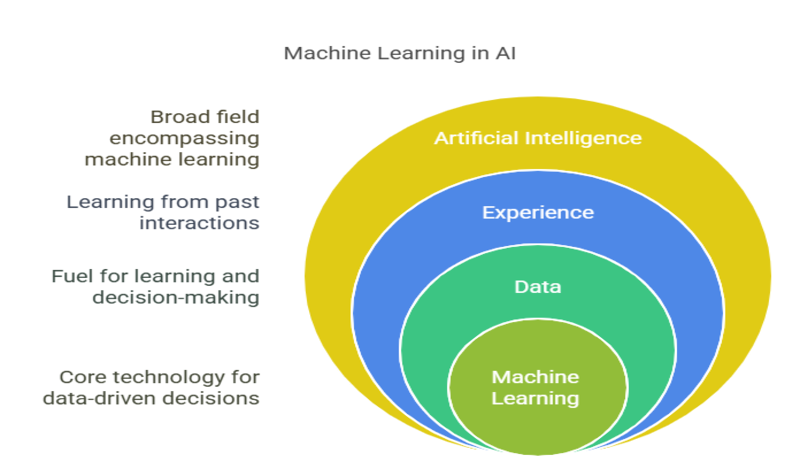
Now imagine doing this with a computer. That’s the core idea behind Machine Learning (ML) — teaching machines to learn from data and make decisions without being directly programmed for every task.
Machine learning is a part of Artificial Intelligence (AI) that allows computers to learn from experience. Instead of programming every action, we give them data, and they learn from it.
And the world is taking notice. In 2024, the global machine learning market was valued at USD 35.32 billion. By 2025, it’s expected to reach USD 47.99 billion, and it could skyrocket to USD 309.68 billion by 2032, growing at an impressive 30.5% per year. This shows just how quickly ML is becoming a major force across industries.
Let’s explore how machine learning works, the different types it comes in, where it’s already making a difference, and what challenges it still needs to overcome.
Key Takeaways
- Machine learning is a core part of AI that lets machines learn and make data-based decisions.
- ML has three main types: supervised, unsupervised, and reinforcement learning.
- Real-world uses include spam filtering, fraud detection, and self-driving cars.
- ML faces challenges like bias, transparency issues, and job displacement.
- Learning ML through platforms like Pickl.AI opens up data science career opportunities.
How Machines Learn Like Humans
Think about how you learn to recognize faces, drive a car, or cook a recipe. You learn by trying, failing, and improving. Machine learning works the same way. We feed computers much information, like text, images, or numbers. The machine then looks for patterns and uses them to make future predictions or decisions.
The more data it gets, the better it becomes — just like how you get better at a game the more you play.
Types of Machine Learning
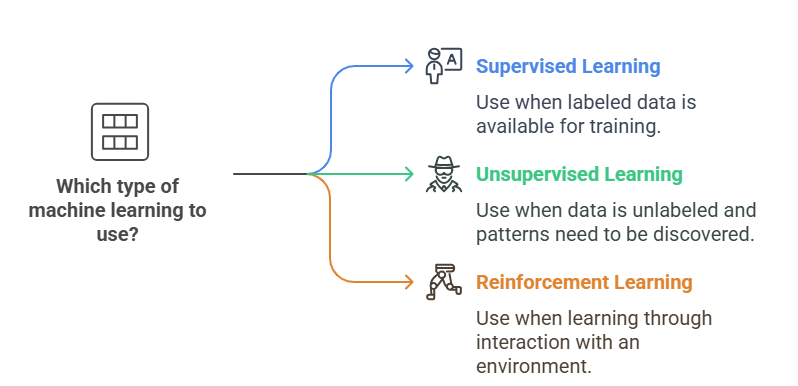
Machine learning isn’t one-size-fits-all. There are three main types, each with its own approach and purpose:
Supervised Learning
Think of supervised learning like having a teacher. The machine gets data that includes the input and the correct answer (called a label). The goal is to learn the pattern so it can guess the right answer for new data.
Examples:
- Spam Filtering: The computer learns to filter future emails based on emails marked “spam” or “not spam.”
- Image Recognition: It learns from labeled pictures (e.g., “cat” or “dog”) to recognize objects in new photos.
Popular Algorithms:
- Linear Regression: Predicts numbers, like house prices based on size.
- Decision Trees: Like a flowchart that helps decide, for example, whether to approve a loan.
- Support Vector Machines (SVMs): Draws a clear boundary between categories, useful in tasks like handwriting recognition.
Unsupervised Learning
Imagine you’re given a box of random objects and told to sort them however you like. That’s unsupervised learning. The machine gets data but no answers — it must find hidden patterns or groups.
Examples:
- Customer Segmentation: Grouping shoppers with similar buying habits to tailor marketing.
- Anomaly Detection: Spotting strange patterns in bank transactions that might mean fraud.
Popular Algorithms:
- K-Means Clustering: Groups similar data points together, like customers who buy pet products.
- Principal Component Analysis (PCA): Simplifies complex data to make it easier to understand or process, like compressing images.
- Hierarchical Clustering: Builds a tree-like structure of groups. It’s like organizing animals into groups and then subgroups—mammals, dogs, and breeds.
Reinforcement Learning
This type is like training a pet with treats. The machine interacts with an environment, makes decisions, and gets rewards or penalties. Over time, it learns what actions lead to the best results.
Examples:
- Self-Driving Cars: The car learns how to drive safely by reacting to real traffic situations and learning from outcomes.
- Game Playing: Algorithms play games like Chess or Go and learn strategies by competing against themselves.
Popular Algorithm:
- Q-Learning: The machine tests different actions, sees what works, and remembers what leads to good results. For example, a robot vacuum learns which paths clean the floor best.
- Deep Q-Networks (DQN): Combines Q-Learning with deep learning to solve more complex problems, like learning how to play video games better than humans.
- SARSA (State-Action-Reward-State-Action): Similar to Q-Learning, but it considers the next action it will take. It’s like learning not just from what happened, but also from what will happen next.
Machine Learning in Everyday Life
You may not realize it, but machine learning is already all around you. Here are some ways it’s making life easier and smarter:
- Movie & Music Recommendations: Netflix, Spotify, and YouTube suggest content based on what you’ve watched or listened to before.
- Email Spam Filters: Keeps junk mail out of your inbox by learning from millions of spam emails.
- Fraud Detection: Banks detect unusual transactions using ML to protect your account.
- Medical Diagnosis: Helps doctors detect diseases by analyzing X-rays, CT scans, and patient data.
- Self-Driving Cars: Combine multiple ML types to navigate traffic, recognize signs, and avoid accidents.
Opportunities Ahead
Machine learning is still growing, and its potential is enormous. Here are some exciting ways it could shape the future:
Personalised Learning in Education
Imagine a classroom where lessons adjust in real-time to how each student learns best. ML can make this happen, helping every student succeed.
Faster Scientific Discoveries
Researchers can analyze huge amounts of data quickly to discover new drugs or materials. Machine Learning speeds up this process and opens doors to discoveries we once thought impossible.
Smarter Cities
ML can help manage traffic, reduce energy use, and improve safety, leading to more efficient and livable cities.
Challenges of Machine Learning
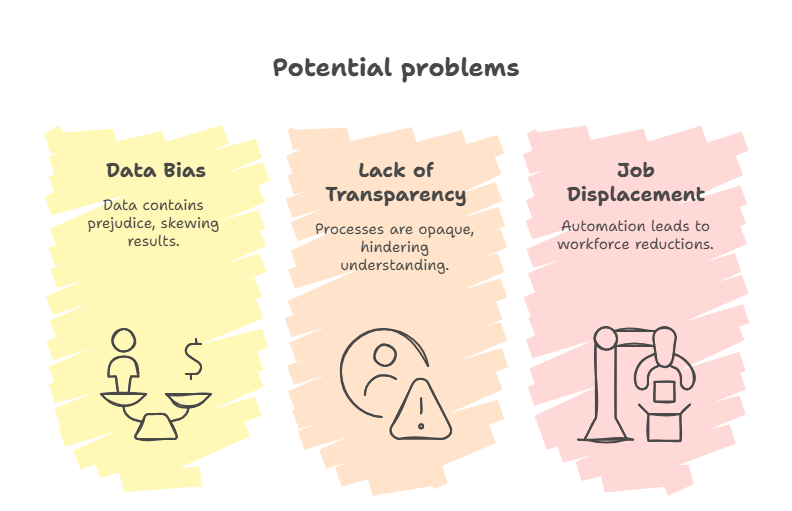
While machine learning offers many advantages, it also presents important challenges that we need to address to ensure its responsible and fair use. These issues affect not only the technology itself but also people’s lives, businesses, and society.
- Bias in Data: If the data used to train a model is biased or incomplete, the machine can learn and repeat those biases. This may lead to unfair outcomes, especially in hiring, lending, or law enforcement.
- Lack of Transparency: Many Machine Learning models work like a “black box,” where even experts can’t fully explain how a decision was made. This lack of clarity can be risky in critical healthcare or criminal justice sectors.
- Job Displacement: As automation increases, some jobs may be replaced by machines. This creates a need for retraining and helping people adapt to new roles in a changing workforce.
Building a Responsible Future with Machine Learning
Machine Learning is powerful, but with power comes responsibility. Here’s how we can shape its future positively:
Learn the Basics
You don’t need to be a tech expert. Start with simple articles, videos, or online courses. Understanding the basics helps you stay informed and ask the right questions.
Promote Ethical AI
Support companies and laws that promote fairness, transparency, and accountability in AI. Demand systems that work for everyone, not just a few.
Keep Learning
ML is always evolving. Stay curious. Your knowledge, whether from reading an article or taking an online class, can help shape how AI is used in society.
Closing Thoughts
So, what is machine learning? It’s not magic and is not reserved for lab scientists. It’s a tool — an innovative way for machines to learn from data and help us solve real problems.
From spotting fraud and diagnosing illnesses to personalizing your movie choices, machine learning is already shaping your world. As it continues to evolve, it’s up to all of us to guide its development with care, curiosity, and responsibility.
Understanding machine learning doesn’t have to be hard. By breaking it down, we can all appreciate its value and make better decisions in a world where AI is becoming a part of everyday life.
As ML continues to evolve, so do the career opportunities in this field. To become part of this revolution, you can learn through expert-led data science courses by Pickl.AI. Whether you’re a beginner or looking to upgrade your skills, Pickl.AI provides the knowledge and tools to succeed in machine learning and beyond.
Frequently Asked Questions
What is machine learning and why is it important?
Machine learning is a branch of AI where machines learn from data and improve over time without being explicitly programmed. It’s important because it powers innovations like self-driving cars, medical diagnoses, and personalized recommendations, transforming how industries operate and make decisions.
How is machine learning used in real life?
Machine learning is used in everyday tools like Netflix for movie suggestions, banks for fraud detection, and healthcare for disease prediction. It improves user experience, boosts efficiency, and automates complex tasks across finance, retail, transportation, and more sectors.
Can I learn machine learning without coding experience?
Yes, you can start learning machine learning even without coding knowledge. Platforms like Pickl.AI offer beginner-friendly courses that teach ML concepts step by step, helping you build a strong foundation before diving into programming or advanced algorithms.
Authors
-

Written by:
Versha RawatReviewed by:



