
Summary: Variance in statistics measures how data points deviate from the mean, indicating data spread. It’s essential for identifying trends, patterns, and outliers. While sensitive to extreme values, variance is crucial in fields like finance, sports, and weather forecasting and is often interpreted through standard deviation for easier understanding.
Introduction
Statistics is fundamental for analysing and interpreting data, helping us make informed decisions in various fields. Among its core concepts is variance, a measure of how data points differ from the mean. Understanding variance in statistics is vital for uncovering patterns, identifying trends, and assessing consistency in datasets.
This blog aims to explain variance, explain its calculation, and highlight real-world applications. By the end, you’ll grasp how variance helps quantify data variability and why it’s an essential concept in statistical analysis, enabling better insights and more accurate predictions in diverse scenarios.
Key Takeaways
- Variance quantifies data spread by measuring how far values differ from the mean.
- Low variance indicates stability, while high variance signals more fluctuation.
- Variance helps identify patterns, outliers, and predict future trends.
- It’s sensitive to extreme values, which can distort results.
- Standard deviation is often used to interpret variance in practical terms.
What is Variance in Statistics?
Variance is a crucial statistical concept that quantifies the spread of data points in a dataset. It measures how far individual data points deviate from the mean, providing insight into the variability within the data.
In simple terms, variance captures the degree of “spread-outness” in a dataset—whether the values are clustered closely around the mean or widely dispersed.
What Does Variance Measure?
Variance focuses on the differences between each data point and the mean of the dataset. By squaring and averaging these differences, variance highlights how consistently the data behaves.
A low variance indicates that most data points are close to the mean, suggesting stability or uniformity. Conversely, a high variance implies that the data points are more spread out, reflecting greater variability.
Understanding variance is crucial because it helps analysts identify patterns, trends, and anomalies in data. It also serves as the foundation for other statistical measures, such as standard deviation, which provides a more interpretable measure of spread.
Why Is Variance Important?
Variance plays a pivotal role in data interpretation. By measuring variability, it allows researchers and analysts to:
- Compare datasets: Variance highlights differences in data distribution, aiding in comparisons.
- Identify outliers: Large deviations in variance can indicate outliers or irregularities.
- Make predictions: Variance supports models in forecasting and risk assessment.
Everyday Examples of Variance
Variance has practical applications in daily life. In finance, it measures stock price volatility, helping investors manage risks.
- In sports, it compares player performances, identifying consistency and standout moments.
- In weather forecasting, variance helps analyse temperature fluctuations over time.
These examples show how variance reveals insights into the consistency or unpredictability of different systems.
Formula for Variance
Understanding the formula for variance is crucial for analysing data spread in statistical studies. Variance quantifies how much individual data points deviate from the mean, providing a foundation for deeper insights into data patterns.
Whether you’re dealing with an entire population or a sample, the variance formula helps you accurately calculate this variability measure. Let’s break down the mathematical expressions for both population and sample variance.
Population Variance Formula
For a population, the formula is:
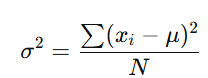
Alt Text: Population variance formula.
Here’s what each term represents:
- xi: Individual data points in the population.
- μ: The mean of the population.
- N: The total number of data points in the population.
You subtract the population mean (μ) from each data point (xi), square the differences and divide the total by N.
Sample Variance Formula
For a sample, the formula is:
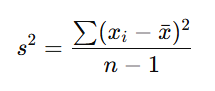
Alt Text: Sample variance formula.
Here’s what each term means:
- xi: Individual data points in the sample.
- xˉ: The mean of the sample.
- n−1: The degrees of freedom (one less than the sample size).
In this formula, you follow the same steps but divide by n−1 instead of N. This adjustment accounts for the smaller sample size and ensures an unbiased estimate of the population variance.
These formulas are essential for understanding data variability and are fundamental in statistical analysis.
Steps to Calculate Variance
Variance is a fundamental concept in statistics that measures how spread out a set of data points is from the mean. Calculating variance helps you understand a data set’s degree of variability or dispersion.
By breaking it into simple steps, anyone can calculate variance and interpret what it reveals about the data. Below is a clear, step-by-step guide to compute variance, complete with an example to make the process easy to follow.
Find the Mean of the Data Set
The first step in calculating variance is determining the mean (average) of the data set. To find the mean, add all the data points and divide the sum by the total number of data points.
For example, consider the data set: 5, 8, 12, 15, and 18.
- Add the values: 5+8+12+15+18=58.
- Divide by the number of data points (n=5n):
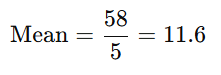
The mean of this data set is 11.6.
Subtract the Mean from Each Data Point and Square the Result
Next, subtract the mean from each data point to find the deviation of each value from the mean. Then, square each deviation to remove negative signs and emphasise larger deviations.
Using the example data set:
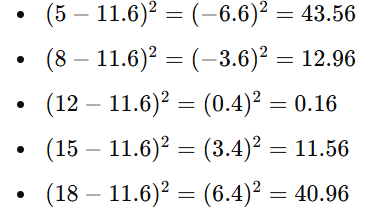
Alt Text: Example data set.
The squared deviations are: 43.56, 12.96, 0.16, 11.56, and 40.96.
Find the Average of the Squared Differences
To calculate the variance, find the average of the squared deviations. For a population, divide the total of the squared differences by N (the number of data points). For a sample, divide by n−1 to account for the degrees of freedom.
In this example, since it’s a sample:
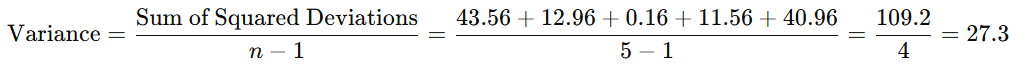
Alt Text: Finding the average of the squared differences.
The sample variance for this data set is 27.3.
By following these steps, you can easily calculate the variance for any data set and better understand its variability.
Variance vs. Other Measures of Spread
Understanding variance becomes more insightful when compared with other measures of data spread. While variance is a cornerstone of statistical analysis, tools like standard deviation, range, and interquartile range (IQR) provide valuable perspectives on data variability.
Each measure has its unique strengths and serves specific purposes in analysing datasets. This section explores how variance compares to these methods and how it complements them.
Variance vs. Standard Deviation
Variance and standard deviation are closely related. The standard deviation is simply the square root of the variance, making it a more intuitive measure since it uses the same units as the original data. For example, if the variance of a dataset measuring heights is 9 cm², the standard deviation is 3 cm. This unit consistency often makes the standard deviation easier to interpret.
However, variance offers a clearer mathematical foundation for advanced analyses, such as regression and hypothesis testing. It also holds greater significance in theoretical work where squared deviations are essential.
Standard deviation, on the other hand, is more practical when you need a quick understanding of data spread in real-world applications. Together, they provide a comprehensive picture of variability.
Variance vs. Range
The range is the simplest measure of spread, calculated as the difference between the largest and smallest values in a dataset. While easy to compute, it lacks the nuance that variance offers.
Range considers only two data points, ignoring the behaviour of the remaining values in the dataset. For instance, a dataset with a range of 20 might still have a minimal variance if most data points cluster near the mean.
Variance, by contrast, accounts for all data points, capturing the degree of spread around the mean. While the range is useful for quickly identifying the extent of variability, variance provides a deeper understanding of how data points are distributed across that range.
Variance vs. Interquartile Range (IQR)
The interquartile range (IQR) measures the spread of the middle 50% of data, calculated as the difference between the third quartile (Q3) and the first quartile (Q1). IQR is particularly useful in identifying the central spread of data while minimising the influence of outliers.
Variance, on the other hand, incorporates all data points, including extreme values. This makes variance more sensitive to outliers than IQR. While IQR is excellent for robust analysis in skewed or non-normal datasets, variance excels in scenarios where a complete representation of variability is required.
How Variance Complements These Measures
Variance complements these measures by providing a detailed, mathematical representation of data spread. It works alongside standard deviation to offer precise and interpretable insights. While range gives a quick snapshot and IQR focuses on central data, variance fills the gap by capturing the overall spread.
Together, these tools empower analysts to approach data variability from multiple angles. Using variance with other measures can build a robust understanding of your dataset, ensuring more accurate interpretations and decisions.
Applications of Variance in Real Life
Variance plays a pivotal role in various fields by measuring the variability or spread of data points. Understanding how much data deviates from the mean can provide valuable insights into trends, predictability, and stability. Here’s how variance is applied in real-world scenarios.
Variance in Finance
In finance, variance is crucial in assessing stock price volatility. Investors use variance to determine the risk associated with an asset. A high variance indicates that a stock’s price fluctuates widely, suggesting greater risk, while a low variance signals more stability.
For example, a company’s stock might show a high variance in its daily price changes, making it a riskier investment compared to one with a lower variance. Investors can make informed decisions on portfolio diversification and risk management by analysing stock price variance.
Variance in Quality Control
Maintaining consistency is vital for producing high-quality products. Variance helps companies assess the consistency of production processes. Manufacturers can detect deviations from the standard by calculating the variance in product dimensions, weight, or other specifications.
If the variance is too high, it may indicate a flaw in the production process or the machinery used, prompting corrective action. This ensures that products meet quality standards and minimise defects, ultimately improving customer satisfaction.
Variance in Sports Statistics
Sports analysts use variance to evaluate performance consistency across athletes or teams. In sports like basketball or soccer, calculating variance in a player’s scores or a team’s performance across several games helps identify whether they perform consistently or erratically.
A player with a low variance in points scored typically performs steadily, while one with a high variance may be inconsistent, either excelling or underperforming on different occasions. Coaches and analysts use variance to plan strategies and identify more reliable players in critical situations.
Variance in Weather Forecasting
Weather forecasting relies on variance to assess the unpredictability of weather patterns. Meteorologists analyse historical weather data to calculate the temperature, rainfall, or wind speed variance over specific periods. This helps them forecast how much weather conditions might deviate from expected norms.
A high variance indicates less predictability, while a low variance suggests more stable weather conditions. Understanding variance aids in better preparation for extreme weather events or climate changes.
Through these varied applications, variance provides insights into data stability, risk, and predictability, making it an essential tool in real-life decision-making processes.
Limitations of Variance
Variance is a useful measure of data dispersion, but several limitations can affect its interpretation and usefulness in certain situations. Understanding these drawbacks is crucial for making informed decisions when analysing data.
Sensitivity to Extreme Values (Outliers)
One of the variance’s most significant limitations is its sensitivity to outliers or extreme values. Since variance involves squaring the differences between each data point and the mean, any data point far from the mean can disproportionately increase the overall variance. Even a single outlier can drastically inflate the variance, making the data appear more spread out than it is.
For example, in a dataset of incomes where most values are clustered around a certain amount, one extremely high income could significantly increase the variance, leading to misleading conclusions about the data’s distribution.
Units of Variance Being Squared
Another limitation of variance is that its units are squared. If you work with a dataset where values are measured in meters, the variance will be in square meters.
This can make it difficult to directly interpret or compare the variance in practical terms, as the result is not on the same scale as the original data. This squaring can lead to confusion when explaining variance to non-experts or making comparisons across different datasets with different units of measurement.
The Need for Further Interpretation Using Standard Deviation
While variance provides a numerical value for the data spread, it is often hard to interpret because of the squared units. To make the variance more interpretable, statisticians usually take the square root of the variance to obtain the standard deviation.
Standard deviation is expressed in the same units as the data, making it more intuitive to understand. Without this further interpretation, the variance alone might not offer much insight into the practical spread of the data.
In Closing
Variance in statistics measures data spread, showing how much individual points differ from the mean. It’s a vital tool in data analysis, helping researchers identify trends, patterns, and inconsistencies. Though it has limitations, like sensitivity to outliers, variance provides critical insights across various fields such as finance, sports, and weather.
Frequently Asked Questions
What is Variance in Statistics, and why is it Important?
Variance measures how data points differ from the mean. It’s important because it quantifies variability, helping analysts identify trends, assess risk, and make informed decisions in finance, quality control, and weather forecasting.
How is Variance Calculated in Statistics?
Variance is calculated by finding the data set’s mean, subtracting the mean from each data point, squaring the differences, and averaging the squared deviations. For a sample, divide by (n-1) to account for degrees of freedom.
What’s the Difference Between Variance and Standard Deviation?
Variance measures the spread of data points by squaring deviations from the mean. Standard deviation is the square root of variance, making it more interpretable since it’s in the same units as the original data.
Authors
-

Written by:
Karan ThaparReviewed by:



