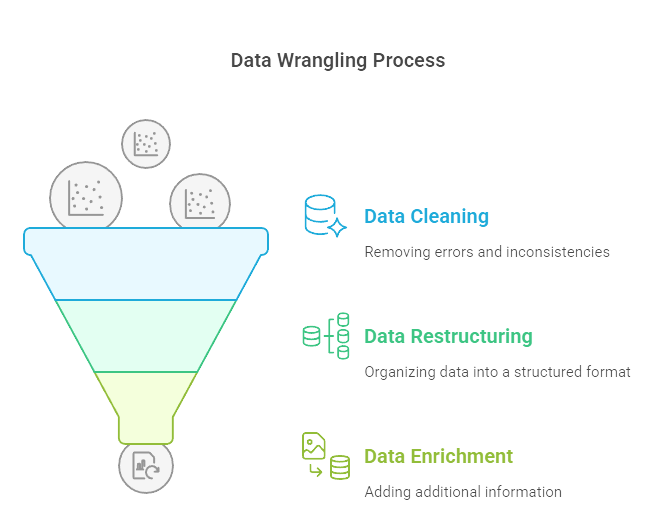
Summary: Data wrangling, or data munging, is the process of transforming raw, messy data into clean, structured formats suitable for analysis. It involves steps like cleaning, structuring, and enriching data to ensure accuracy and usability. This essential process improves data quality, enabling organizations to derive reliable insights and make informed decisions
Introduction
Data wrangling, also known as data munging, is the process of transforming and mapping raw data into a more usable format. This essential step in data analysis involves cleaning, restructuring, and enriching data to facilitate better insights and decision-making. In this document, we will explore the benefits of data wrangling, the tools commonly used in the process, practical examples, and the skills required to excel in this field.
Data Wrangling vs. Data Cleaning
Data cleaning is a subset of data wrangling, but it’s an essential one. It focuses specifically on fixing errors and inconsistencies within a dataset. It’s akin to scrubbing a dirty map to remove smudges and markings that hinder readability.
Data wrangling has a broader scope. It encompasses data cleaning activities but also includes data transformation and restructuring to suit the needs of the analysis. Think of data wrangling as the entire map-making process, where data cleaning is just one of the crucial steps involved in preparing an accurate and informative map.
Importance of Data Wrangling
Imagine trying to analyse a map with missing landmarks, inconsistent scales, and cryptic symbols. The same goes for unwrangled data. Here’s why data wrangling is crucial:
Data Quality
Ensures data is accurate, complete, and consistent, leading to reliable analysis. Inaccurate or incomplete data can lead to misleading conclusions and poor decision-making. Data wrangling helps identify and rectify errors, fill in missing values, and ensure consistency across the dataset.
Efficiency
Saves time by preparing data for seamless analysis, avoiding frustrating roadblocks later. Wrangling upfront can significantly reduce the time spent troubleshooting data quality issues during analysis. Clean and well-structured data can be easily imported into analytics tools and manipulated for further exploration.
Actionable Insights
Enables the extraction of meaningful trends and patterns for informed decision-making. Data wrangling helps uncover hidden gems within the data. By removing noise and inconsistencies, data wrangling allows analysts to focus on extracting clear and actionable insights that can guide business strategies and decision-making processes.
Data Wrangling Process
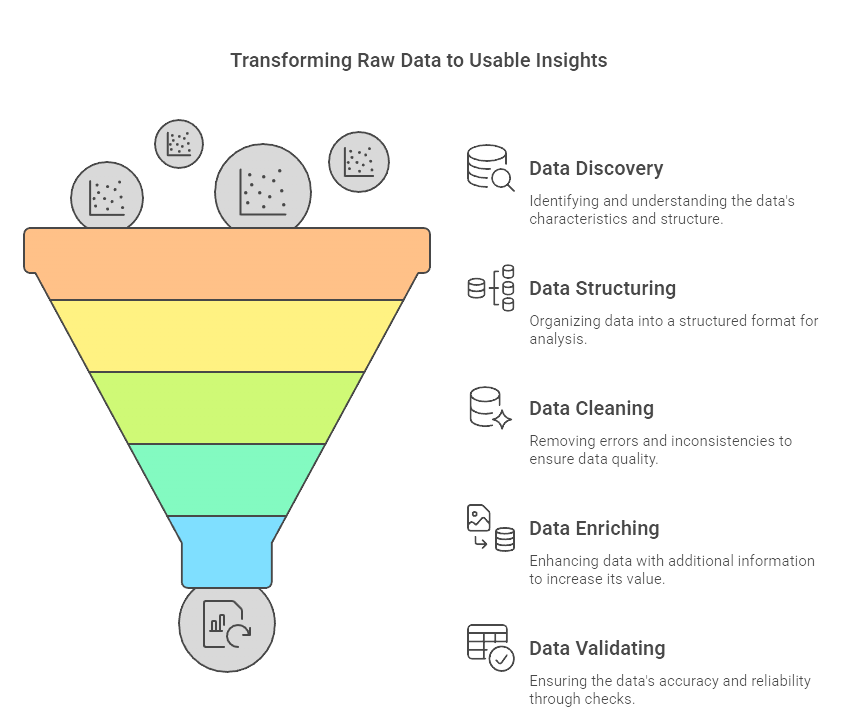
Data wrangling, also known as data munging, is the process of transforming raw, unstructured data into a clean, structured, and usable format for analysis. This iterative process is essential for ensuring high-quality data that can inform accurate insights and decision-making. Below is a detailed step-by-step guide to the data wrangling process.
Discovery
The discovery phase involves understanding and exploring the raw data collected from various sources. This step lays the foundation for subsequent processes by assessing the quality, structure, and relevance of the data.
- Key Activities:
- Identify data sources (e.g., databases, spreadsheets, APIs).
- Assess data quality by checking for missing values, inconsistencies, or outliers.
- Explore trends or patterns in the dataset.
- Define business questions or goals the data needs to address.
- Objective: Gain a comprehensive understanding of the dataset to recognize potential challenges and opportunities for analysis.
Structuring
In this step, raw data is organized into a format suitable for analysis. Structuring involves reshaping datasets, standardizing formats, and ensuring coherence across fields.
- Key Activities:
- Convert raw data into structured formats (e.g., tables or arrays).
- Handle missing values by imputing or removing them.
- Standardize data types (e.g., converting text to numerical formats).
- Merge datasets from multiple sources into a unified structure.
- Objective: Create a consistent and standardized dataset that facilitates efficient analysis.
Cleaning
Data cleaning is one of the most crucial steps in wrangling. It involves identifying and rectifying errors, inconsistencies, and anomalies within the dataset.
- Key Activities:
- Remove duplicates or irrelevant entries.
- Fix formatting issues (e.g., inconsistent date formats).
- Address outliers that could skew results.
- Ensure null values are appropriately handled (e.g., replacing them with averages or removing rows).
- Objective: Enhance the accuracy and reliability of the dataset for downstream processes.
Enriching
Enrichment involves augmenting the dataset with additional information to provide more depth and context for analysis.
- Key Activities:
- Merge external datasets to add new variables or dimensions.
- Extract relevant features from existing data.
- Use domain knowledge to incorporate meaningful insights into the dataset.
- Objective: Make the dataset more comprehensive and valuable for analysis136.
Validating
Validation ensures that the processed data meets predefined standards of quality and reliability. This step is critical for confirming that the dataset is ready for meaningful analysis.
- Key Activities:
- Cross-check fields for accuracy using validation rules.
- Verify consistency across different parts of the dataset.
- Ensure compliance with business requirements or analytical models.
- Objective: Build confidence in the integrity of the dataset before publishing it137.
Publishing
The final step involves preparing the cleaned and validated dataset for use in analytics or dissemination to stakeholders.
- Key Activities:
- Document all steps taken during wrangling (data lineage).
- Share metadata to facilitate collaboration between teams.
- Store or integrate the dataset into analytical tools for further use.
- Objective: Ensure that others can easily access and leverage the prepared data for their analyses or business decisions
Benefits of Data Wrangling
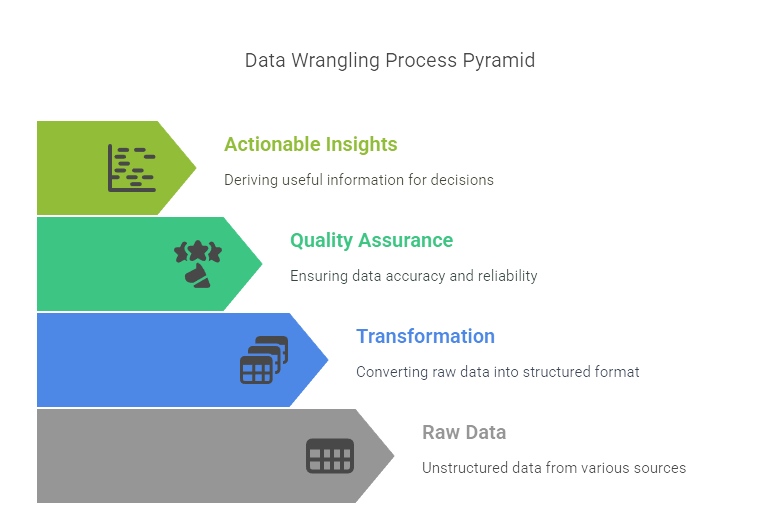
The data wrangling process is essential for transforming messy raw data into a structured format ready for analysis. Each step plays a vital role in ensuring high-quality datasets that can drive actionable insights. By following this systematic approach, organizations can maximize their ability to make informed decisions based on accurate and reliable data.
Improved Data Quality
- Error Correction: It identifies and rectifies errors, inconsistencies, and missing values in datasets, ensuring the data is accurate and reliable for analysis.
- Consistency: By organizing raw data into a structured format, it eliminates duplications and discrepancies, leading to more consistent datasets.
- Trustworthy Insights: High-quality data minimizes the risk of incorrect conclusions, enabling organizations to make informed decisions.
Enhanced Decision-Making
- Accurate Insights: Clean and structured data allows businesses to extract actionable insights needed for strategic decision-making.
- Predictive Analytics: Wrangled data serves as the foundation for advanced analytics and machine learning models, improving forecasting and trend analysis.
- Clarity in Communication: Well-organized data facilitates better understanding among teams, promoting transparency and collaboration.
Time Efficiency
- Automation: Automating the wrangling process reduces manual effort and speeds up data preparation, allowing analysts to focus on core analytical tasks.
- Faster Analysis: Streamlined workflows accelerate the time taken to analyze data and generate reports.
- Reduced Errors: Properly cleaned data minimizes errors during integration or analysis, saving time on corrections later.
Better Data Integration
- Unified Formats: Wrangling helps consolidate diverse datasets from multiple sources into a single cohesive format, enabling seamless integration.
- Holistic View: By integrating IoT, social media, and enterprise system data, organizations gain a comprehensive perspective for decision-making.
- Cross-Departmental Collaboration: Standardized data formats improve communication between departments using different systems.
Increased Productivity
- Streamlined Processes: Wrangling simplifies complex data handling tasks, freeing up resources for more strategic activities.
- Efficient Use of Resources: Analysts spend less time cleaning data and more time deriving insights that drive business growth.
- Cost Savings: Organized datasets reduce errors during model building or reporting, saving time and money in the long run
Data Wrangling Formats
Data wranglers don’t just clean data, they also reshape it for analysis. Dive into common formats like CSV, JSON, and Parquet, each with its strengths for storing and manipulating data in specific ways. It often involves transforming data into specific formats for analysis. Here are some common formats:
Comma-Separated Values (CSV)
A simple and widely used format where data is stored in plain text with each record on a new line and values separated by commas.
JSON (JavaScript Object Notation)
A human-readable format that uses key-value pairs to represent data structures, making it ideal for storing semi-structured data.
Parquet
A columnar storage format designed for efficient data analysis, particularly with large datasets. It stores data in columns rather than rows, allowing for faster retrieval of specific data points.
Data Wrangling Examples
Data wrangling isn’t just theoretical! See how it tackles real-world scenarios. We’ll explore how wranglers clean website data for e-commerce analysis, untangle social media sentiment and tame financial records for market trend insights. Let’s delve into some real-world examples of data wrangling in action:
E-commerce Analysis
Wrangling website clickstream data may involve cleaning inconsistencies in product names, handling missing data points like customer location, and transforming the data into a format suitable for analysing customer behaviour and purchasing trends.
Social Media Sentiment Analysis
Cleaning social media data might involve removing irrelevant characters like emojis and hashtags, correcting typos, and categorising text data into positive, negative, or neutral sentiment for further analysis.
Financial Data Analysis
Wrangling financial data may involve correcting typos in stock symbols, handling missing data points like closing prices, and converting dates into a consistent format for analysing market trends and investment performance.
Top Data Wrangling Skills Required
Equipping yourself with the right tools is just one piece of the puzzle. To truly wrangle data like a pro, sharpen your programming chops (Python or R are popular choices), data analysis skills, and problem-solving abilities. A meticulous eye for detail and clear communication round out the skillset for data wrangling mastery.
Programming Skills
Familiarity with Python, R, or other programming languages is essential for manipulating and transforming data.
Data Analysis Skills
Understanding statistical concepts and data analysis techniques helps you identify and address data quality issues effectively.
Problem-Solving Skills
Data wrangling often involves unexpected challenges. Strong problem-solving skills are crucial for navigating these hurdles and finding creative solutions.
Communication Skills
Being able to document the data wrangling process and communicate insights to stakeholders is essential.
Conclusion
Data wrangling, though often unseen, is the unsung hero of data science. It lays the foundation for reliable analysis, empowers data-driven decision-making, and ultimately unlocks the true potential of data.
Whether you’re a seasoned data scientist or just starting your data journey, mastering data wrangling skills will equip you to transform raw data into actionable insights and navigate the ever-evolving world of data effectively. So, grab your tools, hone your skills, and embrace the challenge of taming the wild west of data!
Frequently Asked Questions
Is Data Wrangling Difficult?
Data wrangling can be challenging, especially for large and complex datasets. However, with the right tools, skills, and a systematic approach, it can be mastered.
How Long Does Data Wrangling Take?
The time spent on data wrangling varies depending on the size and complexity of the dataset. For smaller datasets, it might take a few hours, while large-scale projects can involve weeks or even months of wrangling.
What is a Data Wrangler’s Salary?
Data wrangler salaries can vary based on experience, location, and industry. According to Indeed, the average salary for a data wrangler in the US is around $78,000 per year.
Authors
-

Written by:
Neha SinghReviewed by: