
Summary: Discover diverse GitHub data science projects, from Kaggle challenges to deep learning applications. Master GitHub for effective project management and collaboration. Gain hands-on experience with real datasets, enhancing data analysis, modelling, and career readiness skills.
Introduction
Data Science is one of the most demanding career fields today, with millions of job opportunities flooding the market. To ensure that you have a great career in the data domain, one of the major requirements is to create and maintain a Github project on Data Science.
If you want to become an efficient Data Scientist and grab that job role you’ve been looking for, you need to work on GitHub for Data Science projects. Some of the best data science projects on GitHub for beginners as well as advanced learners are listed in this blog.
This blog will also cover data science projects on Githib using a linear regression model. You will also learn how to upload data science projects and real-world data science projects on GitHub. By the end of this, I will further inform you about some of the best data science courses to boost your career in the data domain. Let’s take a look.
What is GitHub?
GitHub is a web-based platform that facilitates version control and collaboration. It allows multiple users to work on projects simultaneously, track changes, and maintain a project development history. GitHub uses Git, a version control system, to manage and store code.
This platform supports collaborative coding, enabling developers to efficiently share, review, and improve each other’s work.
Importance of GitHub in the Open-Source Community
GitHub plays a pivotal role in the open-source community. It hosts millions of open-source projects, allowing developers to contribute to and improve software collectively. This collaboration fosters innovation and accelerates technological advancement. GitHub’s transparency and accessibility make it an ideal platform for sharing knowledge and building high-quality software.
Benefits and Key Features
Using GitHub for data science projects offers numerous advantages. It enhances collaboration by allowing team members to work on the same project from different locations. GitHub’s version control capabilities ensure that all changes are tracked and reversible. This is crucial for data science projects, where experiments and iterations are standard. Additionally, GitHub repositories serve as portfolios, showcasing a data scientist’s skills and projects to potential employers.
Key Features of GitHb are:
- Repositories: Project containers store all related files and their revision history.
- Branches: Branches enable developers to work on different features or fixes simultaneously without affecting the main project.
- Commits: Commits are snapshots of project changes, providing a detailed history of modifications.
- Pull Requests: Pull requests facilitate code reviews and discussions before integrating changes into the main project, ensuring code quality and consistency.
By leveraging these features, GitHub streamlines project management and enhances collaborative efficiency in data science.
Top 10 Best Data Science Projects on GitHub for Beginners and Advanced Learners

Knowing about the best data science projects on GitHub is crucial for beginners and advanced learners. These projects provide hands-on experience, showcase real-world applications, enhance skills, and offer insights into industry practices. These projects can boost your portfolio, facilitate learning new techniques, and foster collaboration within the data science community.
Face Recognition
One of the most effective GitHub Projects on Data Science is a Face Recognition project that uses Deep Learning and a Histogram of Oriented Gradients (HOG) algorithm. The system is explicitly designed to find the faces in an image, align transformations using an ensemble of regression trees, encode faces, and make predictions. You can use the HOG algorithm for orientation gradients and the Python library to create and view HOG representations.
Kaggle Bike Sharing
Bike-sharing systems are one of the best Data Science projects on GitHub. They allow you to book and rent motorbikes or bicycles and return them. The entire system is automated and more like a Kaggle competition. It requires you to combine historical usage patterns with weather data to predict the demand for rental services.
The primary goal of the Kaggle competition is to create an Machine Learning (ML) Model that can predict the number of bikes rented. The first part requires you to focus on understanding, analysing, and processing datasets; the second part involves designing the model using an ML Library.
Identifying fraudulent Credit Card Transactions
Fraud Detection in credit card transactions is one of the best Data Science projects on GitHub for beginners. The project will make you highly proficient in identifying data patterns and anomalies.
Within this project, you can work with any dataset relevant to credit card transactions that contain fraudulent transactions of as many as 500, for instance, from 300,000 total transactions. You start with data exploration to understand the dataset structure and check the missing values in a dataset using Pandas Library.
It can be followed by data pre-processing, handling the missing values, removing unnecessary variables and creating new features using feature engineering. The next step is to train ML models considering different ML algorithms. It can be followed by evaluating the performance using metrics like recall, precision, etc.
Sentiment Analysis on Twitter Data
The field of Twitter is famous for different kinds of data, which makes it a good source for participation in learning and Data Science tasks. Accordingly, the project aims to analyse the sentiments behind the most popular channel, Twitter, using NLP.
The Data Science projects on GitHub will help you gather Twitter data using Streaming Twitter, API, MySQL, Python, and Tweepy. You can then perform sentiment analysis to identify specific emotions and opinions. Monitoring these sentiments can help individuals or organisations make better decisions and improve customer experiences.
Analysing Netflix Movies and TV Shows
One of the most enticing real-world data science projects, Github, can include a project that analyses Netflix movies and TV shows. Using Netflix user data, you need to undertake data analysis to run workflows like EDA, data visualisation, and interpretation.
The Data Science projects on Github aim to improve your skills and use libraries like Matpotlib, Seaborn and World Cloud for interpreting Netflix data. For the project, you can also use Netflix Original Films and dataset scores from the IMDb dataset available on Kaggle.
Customer Segmentation using K-Means Clustering
One of the most crucial uses of data science is customer segmentation. For this GitHub data mining project, you must use the K-clustering method. This renowned unsupervised machine learning approach splits data into K clusters based on similarities.
The purpose of the undertaking is to use the K-means clustering method to categorise clients visiting a mall based on different factors. These factors include their yearly earnings, spending habits, etc.
You must collect data, and conduct preparatory studies and information pre-processing. You must also train and test a K-means clustering model to segment clients. You can use a Mall customer segmentation dataset that contains five characteristics and information on 200 customers.
Medical Diagnosis with Deep Learning
Deep learning is a recent branch of machine learning which consists of numerous layers of artificial neural networks. Due to its tremendous analysing abilities, it is frequently used for complicated applications.
Consequently, participating in a Github data science project incorporating deep learning will be extremely helpful for your Github data analyst portfolio. This GitHub data science effort uses deep-learning convolution models to identify multiple conditions in chest X-rays. After finishing, you should understand how deep learning/machine learning is utilised in radiography.
Predicting Housing Prices with Machine Learning
One of the most popular data analyst projects on GitHub is house price prediction. The purpose of this project is to forecast house values based on a variety of parameters and investigate the relationships between them. After finishing this course, you will be able to interpret how each of these factors influences house prices.
You will use a dataset with more than 13 elements, such as ID (to count the records), zones, area (lot size in square feet), build type (kind of housing), year of construction, year of remodelling (if valid), and sale price (to be projected).
DeepCTR
DeepCTR promotes itself as an “easy-to-use, modular, and extendible package of Deep Learning-based CTR models.” It additionally provides various helpful functions and layers to generate customised models.
TensorFlow was employed to create the DeepCTR project. While TensorFlow is an excellent tool, it is not for everyone. As a consequence, the DeepCTR-Torch library was created. The most recent version includes the entire DeepCTR code for PyTorch.
StringSifter
If you are interested in cybersecurity, you will enjoy being involved with this project! StringSifter, a machine learning tool developed by FireEye, can intelligently rank strings based on their analysis of malware significance.
Strings are usually present in ordinary computer programmes to carry out certain activities, such as generating a registry key, copying information from one spot to another, and so on. StringSifter is an excellent tool for preventing cyber threats. However, it requires Python 3.6 or greater for operations and download.
Data Science Projects on GitHub Using Linear Regression Model

Linear regression is a fundamental data science technique for modelling relationships between variables. It predicts a dependent variable based on one or more independent variables. This method is widely used in finance, healthcare, and marketing to identify trends and make predictions.
Step-by-Step Guide to a Project Using Linear Regression
When embarking on a data science project on GitHub using linear regression, it’s essential to follow a structured approach to ensure the clarity and reproducibility of your work. Here’s a step-by-step guide:
Define the Problem Statement: Clearly articulate what you aim to achieve with your project. For example, in predicting housing prices, you may want to build a model that accurately predicts the sale price of houses based on features like location, size, and amenities.
Data Collection and Preparation: Gather relevant datasets containing features (independent variables) and the target (dependent) variable. Clean and preprocess the data to handle missing values, outliers, and categorical variables.
Exploratory Data Analysis (EDA): Conduct EDA to understand the distribution of variables and correlations between features and identify patterns that can inform your model selection and feature engineering.
Feature Engineering: Select or create meaningful features with predictive power for the target variable. Predicting housing prices could involve transforming variables, developing new features like price per square foot, or encoding categorical variables.
Model Building: Implement linear regression using a suitable library like scikit-learn in Python. Split the data into training and testing sets, train the model on the training data, and evaluate its performance using metrics like mean squared error (MSE) or R-squared.
Model Evaluation and Optimisation: Assess the model’s performance on the test set, tune hyperparameters (e.g., regularisation parameters) if necessary, and validate its robustness through techniques like cross-validation.
Example Project: Predicting Housing Prices
Predicting housing prices is a joint data science project on GitHub using a linear regression model. This project uses historical data to predict future prices, which can help buyers and investors make informed decisions.
Dataset Used
For this project, you can use the Boston Housing Dataset, which includes features such as the number of rooms, property age, and crime rate. This dataset is readily available in many machine learning libraries.
Code Snippets and Explanation
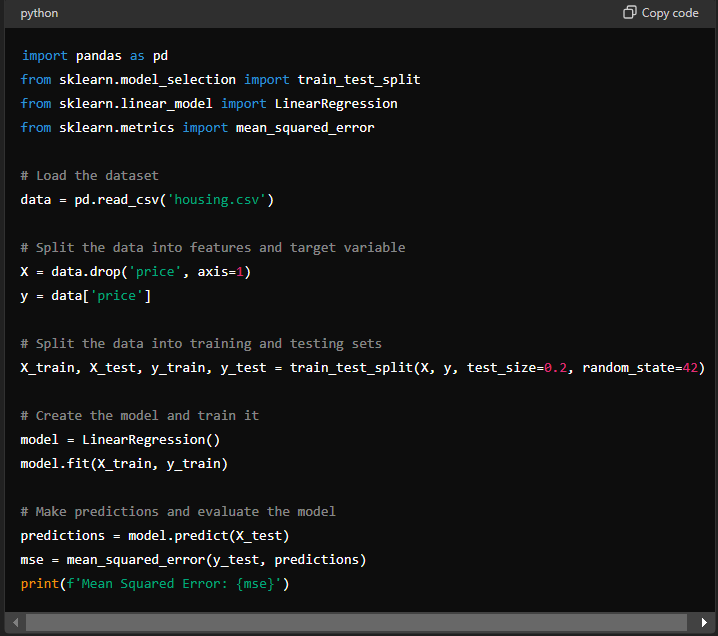
This code demonstrates the essential steps: loading data, splitting it, training the model, and evaluating performance.
Additional Resources and Similar Projects
Explore GitHub repositories such as “Awesome Data Science Projects” and “Data Science with Python” for more examples and detailed guides. These resources provide a variety of projects, including those using linear regression, to help you enhance your skills.
How to Upload a Data Science Project on GitHub
Understanding how to upload a Data Science project on GitHub is crucial for collaboration and visibility in the tech community. It showcases your skills, allows version control, and enables feedback from peers and potential employers. Mastering this skill boosts credibility and opens doors to career opportunities in data science.
Step-by-Step Guide to Creating a GitHub Repository
Mastering GitHub repositories ensures streamlined development and effective project maintenance in today’s collaborative coding landscape. Creating a GitHub repository is the first step towards sharing your data science project. Follow these steps to get started:
Sign in to GitHub: Log in to your GitHub account. If you don’t have one, sign up for free.
Create a New Repository: Click on the “+” sign in the top right corner of your GitHub profile page and select “New repository.”
Name Your Repository: Choose a descriptive name for your repository, such as “Data-Analysis-COVID19” or “Machine-Learning-Sentiment-Analysis.”
Add a Description: Write a brief description that explains your project’s purpose and goals. This will help others understand your project quickly.
Choose Public or Private: Decide whether your repository is public (visible to everyone) or private (accessible only to you and collaborators you specify).
Initialise with a README: Check the box to initialise your repository with a README file. This file will appear on the main page and is crucial for providing project details and instructions.
Create repository: Click the “Create repository” button to finalise and create your repository.
Instructions on Organising and Documenting Your Project
Understanding instructions for organising and documenting your project is crucial for clarity, efficiency, and collaboration. Clear guidelines ensure tasks are executed correctly, deadlines are met, and information is readily accessible. Instructions are:
Folder Structure: Create logical folders for different components of your project, such as “data,” “scripts,” “notebooks,” and “documentation.”
File Naming: Use descriptive names for files and folders. For instance, “data_cleaning_script.py” or “final_report.ipynb.”
Documentation: Include a detailed README file that outlines the project’s purpose, how to install dependencies, how to run the code, and any other relevant information. Use markdown formatting to structure your README effectively.
Tips for Writing a Clear README File
A README file in GitHub is a crucial document that outlines essential information about a project. It typically includes a project overview, installation instructions, usage guidelines, and other pertinent details.
This file helps developers and users understand the repository’s purpose and functionality quickly and efficiently. A well-crafted README file is crucial for attracting collaborators and users to your project:
Introduction: Start by briefly introducing your project and explaining its objectives and scope.
Installation Instructions: Provide clear steps for setting up and installing any dependencies required for your project.
Usage: Explain how to use your project, including examples of commands or scripts to run.
Contributing Guidelines: If you want others to contribute to your project, outline guidelines for contributing, such as how to submit pull requests and code style conventions.
How to Use Git for Version Control
Understanding how to use Git for version control is crucial for efficient collaboration in software development. It enables tracking changes, managing revisions, and facilitating teamwork seamlessly. Here’s how you can use Git for version control:
Initialize Git: If you haven’t already, initialise Git in your project directory using the command `git init`.
Add and Commit Changes: Use `git add .` to stage your changes and `git commit -m “Your commit message”` to commit them to your local repository.
Push Changes to GitHub: Use `git remote add origin <repository_url>` to link your local repository to your GitHub repository. Then, use `git push -u origin main` (or `git push -u origin master` for older repositories) to push your changes to GitHub.
Best Practices for Maintaining and Updating Your Project
Understanding best practices for maintaining and updating your project ensures efficiency, reliability, and longevity. It prevents costly errors, enhances performance, and adapts to evolving needs seamlessly. Some of the best practices are:
Regular Updates: Continuously update your project with new features, bug fixes, and improvements.
Versioning: Use semantic versioning (e.g., MAJOR.MINOR.PATCH) to manage releases and changes effectively.
Documentation Updates: Update your README and documentation with any changes to the project.
Respond to Issues and Pull Requests: Engage with users who submit issues or pull requests promptly and courteously.
By following these steps and best practices, you can effectively upload your data science project on GitHub, making it accessible and inviting collaboration from the global data science community. Clear organisation, thorough documentation, and active maintenance are critical to a successful GitHub repository.
Real-World Data Science Projects on GitHub

Real-world data science projects hosted on GitHub offer invaluable learning opportunities and significant career growth potential. These projects showcase the practical application of data science techniques and demonstrate how data-driven insights can address real-world challenges across various domains.
Importance of Real-World Projects for Learning and Career Growth
Engaging with real-world data science projects on GitHub provides hands-on experience beyond theoretical knowledge. It allows aspiring data scientists to apply algorithms, handle real datasets, and understand the nuances of data cleaning, preprocessing, modelling, and interpretation. This practical experience is crucial for developing proficiency in data science tools and techniques, which is highly valued by employers seeking skilled data professionals.
Examples of Impactful Real-world Data Science Projects
Understanding impactful real-world data science projects provides insights into solving complex problems, optimising processes, and making informed industry decisions. Let’s look at three real-world examples of data science projects.
Project 1: COVID-19 Data Analysis and Visualization
During the COVID-19 pandemic, numerous data scientists contributed to GitHub repositories, analysing and visualising pandemic-related data. These projects provided insights into infection rates, mortality rates, vaccination progress, and the effectiveness of public health interventions. For instance, projects included:
- Interactive dashboards.
- Predictive models for case trajectories.
- Sentiment analysis of public reactions to pandemic policies.
Project 2: Sentiment Analysis on Social Media Data
Social media platforms generate vast data daily, making sentiment analysis critical for understanding public opinion and consumer behaviour. Projects on GitHub have explored sentiment analysis techniques using natural language processing (NLP) to classify social media posts, tweets, and comments. Insights from such projects can help businesses in reputation management, product development, and customer engagement strategies.
Project 3: Recommendation Systems for E-commerce
E-commerce platforms rely heavily on recommendation systems to personalise user experiences and enhance customer satisfaction. GitHub hosts projects focusing on collaborative filtering, content-based filtering, and hybrid recommendation systems.
These projects involve data preprocessing, model training, evaluation metrics, and deployment strategies, providing comprehensive learning opportunities for aspiring data scientists interested in the intersection of data analytics and business strategy.
Insights and Takeaways from These Projects
Understanding project insights and takeaways is crucial for continuous improvement and future success. It enables refining strategies, optimising processes, and learning from successes and failures. Each of the three real-world data science projects on GitHub offers unique insights and practical takeaways:
- Hands-on Application: Gain practical experience in data preprocessing, modelling, and visualisation techniques relevant to specific domains.
- Problem-solving Skills: Develop critical thinking and problem-solving abilities by tackling complex challenges in real datasets.
- Collaboration and Contribution: Learn the importance of cooperation through open-source contributions and peer feedback on GitHub.
- Career Advancement: Showcase your skills to potential employers by sharing your GitHub repositories and demonstrating your ability to work on impactful projects.
Frequently Asked Questions
What are the best data science projects on GitHub for beginners?
The best GitHub projects for beginners include Kaggle competitions, such as bike-sharing predictions and sentiment analysis on Twitter data. These projects offer hands-on learning opportunities with real-world datasets and practical applications.
How can I upload a data science project on GitHub?
To upload a data science project on GitHub, create a new repository, add project files, and commit changes using Git commands. Include a README file for project details and use clear folder structures for organisation and visibility.
Why are real-world data science projects on GitHub important?
Real-world data science projects on GitHub enhance practical data handling, analysis, and modelling skills. They showcase expertise to potential employers and foster collaboration within the data science community, contributing to career advancement.
Conclusion
Engaging in GitHub data science projects offers invaluable opportunities for skill development and career advancement. From beginner-friendly Kaggle challenges to advanced deep learning applications, these projects provide hands-on experience with real datasets.
Data scientists can effectively showcase their expertise by mastering GitHub for version control and collaboration. Continuous involvement in real-world projects enhances technical proficiency. It demonstrates problem-solving abilities crucial in the competitive data science landscape. Leveraging GitHub ensures visibility, fosters community collaboration, and prepares aspiring data scientists for diverse challenges in the field.
Discover your path to success with Pickl.AI’s top-tier Data Science Courses in India. Whether you’re a beginner or a seasoned pro, our Job Guarantee Program ensures you thrive. Enroll for our intensive 1-year Data Science Bootcamp, or opt for our focused 6-month program.
Prepare for your dream job in just 50 days with our Job Preparation Program. Benefit from 100+ hours of expert-led lectures, placement support, and learning flexibility. Gain hands-on experience with cutting-edge Data Science tools trusted by industry leaders worldwide. Don’t miss out – kickstart your career today with Pickl.AI!
Authors
-

Written by:
Asmita KarReviewed by:



