Summary: Recurrent Neural Networks (RNNs) are specialised neural networks designed for processing sequential data by maintaining memory of previous inputs. They excel in natural language processing, speech recognition, and time series forecasting applications. Advanced variants like LSTMs and GRUs address challenges like vanishing gradients and long-term dependencies.
Introduction
Neural networks have revolutionised data processing by mimicking the human brain’s ability to recognise patterns. Their applications extend across various domains, especially with the growing importance of sequence data in fields like natural language processing and time series forecasting.
Recurrent Neural Networks (RNNs) stand out in this context, as they excel at processing sequential data by incorporating memory. As the global neural network market expands—from $14.35 billion in 2020 to an expected $152.61 billion by 2030, with a CAGR of 26.7%—understanding RNNs is crucial.
This blog aims to introduce RNNs, explore their applications, and highlight their significance in fields like network security in cloud computing.
Key Takeaways
- RNNs maintain memory through recurrent connections.
- They excel in tasks involving sequential data.
- Applications include NLP, speech recognition, and forecasting.
- Advanced variants like LSTMs and GRUs improve performance.
- Effective training strategies mitigate challenges like vanishing gradients.
What Are Recurrent Neural Networks?
Recurrent Neural Networks (RNNs) are a class of artificial neural networks designed to handle sequential data. Unlike traditional neural networks, which assume that each input is independent of the others, RNNs are built to consider data’s temporal or sequential nature.
This makes them ideal for tasks like language modelling, speech recognition, and time series prediction, where context from previous inputs is essential to making accurate predictions.
RNNs vs. Traditional Feedforward Neural Networks
Traditional feedforward neural networks (FNNs) process inputs in isolation. Each input is passed through layers of neurons, and the output is generated without considering any prior inputs. The network is static; once trained, it operates independently of the data sequence.
In contrast, RNNs maintain a form of memory through recurrent connections. This allows them to “remember” information from previous time steps, making them capable of processing sequences.
Each RNN unit, or neuron, receives the current input and the previous output (or hidden state), creating a feedback loop. This unique feature enables RNNs to capture the temporal dependencies that are often crucial in sequence-related tasks.
An RNN consists of three main components: the input, hidden, and output layers.
- Input Layer: This layer receives the input sequence, passing each element at each time step.
- Hidden Layer: The hidden layer is where the network’s “memory” resides. It updates its internal state at each time step based on the current input and the previous hidden state. This recurrent connection allows information to flow backwards and forward across the network, capturing sequential dependencies.
- Output Layer: The output layer generates the prediction or output based on the hidden state at the current time step.
Overall, the key feature of an RNN is its ability to use feedback loops within its architecture, enabling it to process and predict based on entire sequences, not just individual data points.
Key Concepts in RNNs
Recurrent Neural Networks (RNNs) have revolutionised how we handle sequential data. They incorporate unique mechanisms that allow them to process and understand sequences in a way that traditional neural networks cannot. To grasp how RNNs work, one must understand key concepts: memory, recurrent connections, and how they process time-dependent data.
The Concept of Memory in RNNs
Memory is a core feature of RNNs that distinguishes them from traditional neural networks. In standard feedforward networks, each input is processed independently without knowledge of previous inputs.
However, RNNs maintain an internal state, or “memory,” that carries information across time steps. This memory enables the network to remember earlier parts of the sequence and use that information to predict later parts.
The memory is updated at each step based on the current input and the previous hidden state, allowing RNNs to capture temporal dependencies and relationships in the data.
Recurrent Connections and Feedback Loops
RNNs are characterised by their recurrent connections, where the output from a previous step is fed back into the network as input for the current step. This feedback loop enables RNNs to maintain context and make informed decisions based on past and current inputs.
The presence of recurrent connections creates a dynamic flow of information, where each step is connected to the next. This makes RNNs suitable for tasks that involve sequential patterns, such as speech recognition or language modelling.
Processing Sequences and Time-Dependent Data
RNNs excel at processing time-dependent data by analysing sequences of inputs stepwise. As each new input enters the network, the hidden state is updated, which captures the relevant features of the sequence up to that point.
This sequential processing enables RNNs to recognise patterns in time-series data, such as trends in stock prices or temporal relationships in text. Unlike static models, RNNs can learn how past inputs affect future outcomes, making them powerful tools for sequence prediction tasks.
How Recurrent Neural Networks Work?
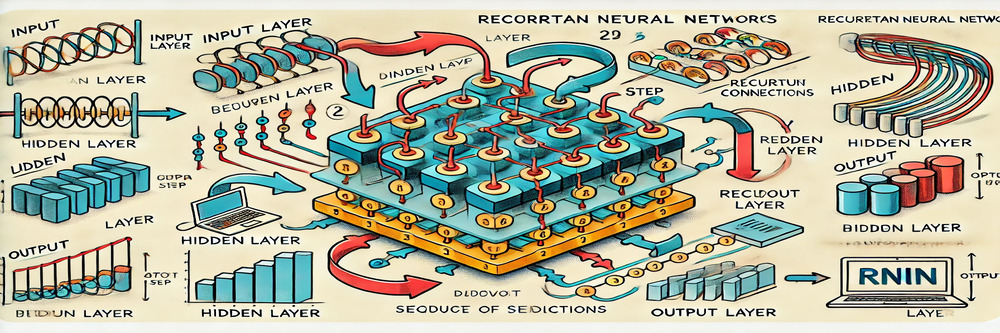
Recurrent Neural Networks (RNNs) are designed to process sequential data by maintaining a memory of previous inputs. This is achieved through their unique structure, where outputs from previous time steps are fed back into the network as part of the input for the current step.
This allows RNNs to capture temporal dependencies and patterns in the data.
Forward Pass in RNNs
The forward pass in an RNN refers to how data flows through the network at each time step. In a typical RNN, the input data ![]() at each time step t is processed by the network, producing an output
at each time step t is processed by the network, producing an output ![]() and updating the hidden state
and updating the hidden state ![]() . The hidden state acts as the network’s memory, storing information from previous time steps that is used in the current step.
. The hidden state acts as the network’s memory, storing information from previous time steps that is used in the current step.
At each step, the input data ![]() is combined with the previous hidden state
is combined with the previous hidden state ![]() to produce the new hidden state
to produce the new hidden state ![]() . This hidden state is then used to generate the output
. This hidden state is then used to generate the output ![]() for the current time step. Calculating the hidden state and the output is repeated for each time step in the sequence.
for the current time step. Calculating the hidden state and the output is repeated for each time step in the sequence.
Understanding the Hidden States and Output
The hidden state ![]() in an RNN plays a critical role in capturing the temporal dependencies in the data. It carries information from previous time steps, which is necessary for understanding the context of the current input.
in an RNN plays a critical role in capturing the temporal dependencies in the data. It carries information from previous time steps, which is necessary for understanding the context of the current input.
Mathematically, the hidden state is updated at each time step based on the current input and the previous hidden state. The output ![]() is typically derived from the hidden state, representing the RNN’s prediction or decision for the given input at time step t.
is typically derived from the hidden state, representing the RNN’s prediction or decision for the given input at time step t.
The relationship between the hidden state, input, and output can be understood through the following equations:
Mathematical Formulation of RNNs
In an RNN, the hidden state and output are computed using the following equations:
Hidden State Update:
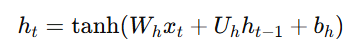
Alt Text: Hidden state update equation.
Here:
 is the hidden state at time step t.
is the hidden state at time step t. is the input at time step ttt.
is the input at time step ttt. and
and  are weight matrices that define how the current input and the previous hidden state are combined.
are weight matrices that define how the current input and the previous hidden state are combined. is the bias term.
is the bias term.- tanh is a common activation function applied to the weighted sum of inputs.
Output Calculation:
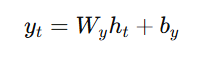
Alt Text: Output calculation equation.
 is the output at time step t.
is the output at time step t. is the weight matrix for the output layer.
is the weight matrix for the output layer. is the bias term for the output.
is the bias term for the output.
Challenges with Traditional RNNs
Recurrent Neural Networks (RNNs) are powerful for sequence-based tasks but face significant challenges. Two major problems that impact their performance are the Vanishing and Exploding Gradient Problem and the Difficulty in Learning Long-Term Dependencies.
Vanishing and Exploding Gradient Problem
The vanishing gradient problem occurs when gradients (used to update weights during training) become too small as they propagate backwards through time. As a result, the model struggles to learn, especially with long sequences.
In contrast, the exploding gradient problem happens when gradients become too large, leading to unstable training. Both issues hinder RNNs from effectively adjusting weights and learning from data.
Difficulty in Learning Long-Term Dependencies
Traditional RNNs have difficulty remembering information from distant time steps. While they excel at processing short-term dependencies, they struggle to capture long-term patterns due to how information is passed through the network.
As sequences grow longer, critical information can be lost in earlier time steps. This makes it challenging for RNNs to work with tasks like language translation or time-series forecasting, where long-term dependencies are essential for accurate predictions.
These challenges have motivated the development of more advanced RNN architectures, such as Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs), which aim to mitigate these limitations.
Advanced Variants of RNNs
Recurrent Neural Networks (RNNs) are powerful for modelling sequential data, but traditional RNNs struggle with capturing long-term dependencies due to problems like vanishing gradients. Over time, more sophisticated architectures have emerged to address these limitations.
Two of the most prominent variants are Long-Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs). These networks enhance the ability of RNNs to learn from sequences that span longer periods, making them suitable for complex tasks like language modelling and time-series forecasting.
Long Short-Term Memory (LSTM) Networks
LSTM networks are specifically designed to overcome the vanishing gradient problem, which makes it difficult for traditional RNNs to learn long-term dependencies. LSTMs introduce a memory cell that can store information for long durations. They use a gating mechanism to control the flow of information, including:
- Forget gate: Decides what information to discard from the cell state.
- Input gate: Determines what new information should be stored.
- Output gate: Controls the output based on the cell state.
This gating mechanism allows LSTMs to retain important information across time steps, improving their performance on speech recognition and machine translation tasks.
Gated Recurrent Units (GRUs)
GRUs are a simpler and more computationally efficient variant of LSTMs. They combine the forget and input gates into a single update gate, simplifying the model structure while maintaining the capability to capture long-range dependencies.
GRUs also use a reset gate, which helps the model decide how much of the previous memory to forget. GRUs have been shown to perform similarly to LSTMs on many tasks, but they are faster to train and require less computational power.
Applications of Recurrent Neural Networks
Recurrent Neural Networks (RNNs) have proven to be a powerful tool for handling sequential data, making them highly effective for tasks that involve time-dependent patterns. From text generation to speech recognition, RNNs applied across various domains, transforming industries and driving innovations. Here are some notable applications of RNNs.
Natural Language Processing (NLP)
RNNs excel in NLP tasks due to their ability to process text sequences. Text generation is one prominent application in which RNNs can predict the next word or character in a sentence, creating coherent and contextually relevant text. This ability powers chatbots, automatic content generation, and creative writing tools.
In sentiment analysis, RNNs analyse the sequence of words in a sentence to determine the positive, negative, or neutral sentiment. This application widely used in social media monitoring, customer feedback analysis, and brand reputation management.
Time Series Forecasting
In time series forecasting, RNNs predict future values based on past data. This is particularly useful in business areas like stock market prediction, weather forecasting, and demand forecasting. By leveraging the temporal dependencies in data, RNNs can capture trends and seasonal patterns, making them essential for accurate predictions.
Speech Recognition
RNNs have significantly advanced speech recognition technologies. These networks process audio signals as sequences, learning patterns in speech to convert spoken words into text. This technology powers virtual assistants like Siri, Alexa, and Google Assistant, enabling more accurate and responsive user interactions.
Music Generation
In the creative field, RNNs used to generate music compositions. By training on sequences of musical notes or sounds, RNNs can create original pieces of music that mimic specific genres or styles. This application is popular in both entertainment and algorithmic music composition.
Video Processing
RNNs also applied to video processing, where they analyse sequences of frames in video data. They can used for object tracking, action recognition, and even video captioning, making them vital in surveillance, autonomous driving, and entertainment.
These diverse applications showcase the versatility and power of RNNs across various industries.
Practical Considerations
Training Recurrent Neural Networks (RNNs) effectively requires attention to several key factors. RNNs are powerful models, but they also come with challenges, especially in optimisation, computational complexity, and choosing the right tools for implementation. This section highlights strategies for training RNNs, managing their performance, and exploring useful libraries for building RNN-based models.
Effective Training Strategies
Addressing issues like vanishing and exploding gradients is crucial to training RNNs effectively. A common approach is gradient clipping, which prevents gradients from becoming too large and destabilising the model.
Additionally, using advanced RNN architectures such as Long Short-Term Memory (LSTM) or Gated Recurrent Units (GRUs) can help mitigate these issues, as they are design to capture long-term dependencies more efficiently than traditional RNNs.
Choosing the right optimiser is also essential. Optimisers like Adam and RMSProp often preferred due to their adaptive learning rates, which help improve convergence during training. Regularisation techniques like dropout can also implemented to avoid overfitting, especially when dealing with large datasets.
Computational Complexity and Performance
RNNs known for their high computational complexity, mainly when dealing with long sequences. This complexity arises because each step in an RNN relies on the previous one, leading to sequential computation.
One effective approach to improve performance is to use parallel processing or batch training, which speeds up computation by simultaneously processing multiple inputs. Additionally, hardware accelerators like GPUs or TPUs can significantly reduce training time.
Tools and Libraries for Implementing RNNs
Several frameworks make it easier to implement RNNs. TensorFlow and PyTorch are the most commonly use libraries for deep learning, offering robust support for RNNs and other neural network architectures.
Both frameworks provide pre-built modules for LSTM and GRU layers, making model development faster and more efficient. PyTorch’s dynamic computation graph particularly suited for RNNs, as it allows for more flexible and intuitive debugging, while TensorFlow’s static graph offers optimised performance for large-scale deployments.
Future of Recurrent Neural Networks

Recurrent Neural Networks (RNNs) have seen significant application growth, especially in fields like natural language processing (NLP) and time-series forecasting. However, as technology evolves, so does the need to improve and innovate upon the existing architectures.
The future of RNNs lies in overcoming their current limitations while integrating new research trends that can enhance their performance and adaptability.
Current Research Trends: Attention Mechanisms and Transformers
A key area of innovation is the integration of attention mechanisms. These mechanisms allow models to focus on specific parts of the input sequence rather than processing data in a fixed order. This leads to improved accuracy and efficiency when handling long sequences. Attention mechanisms are beneficial in translation, summarisation, and even image captioning.
In parallel, transformers have emerged as a dominant architecture in many NLP tasks. Unlike traditional RNNs, transformers do not rely on sequential data processing. Instead, they leverage self-attention to process the entire sequence simultaneously, significantly improving parallelisation and speed.
This architecture has surpassed RNN-based models in performance on large-scale language models (e.g., GPT, BERT) and other complex tasks. We may witness even more powerful architectures as researchers explore hybrid models, combining RNNs with attention or transformer layers.
Challenges and Potential Improvements
Despite advancements, RNNs face challenges, mainly when dealing with long-range dependencies. The vanishing and exploding gradient problems persist, making it difficult for RNNs to retain information over long sequences. Current models like LSTMs and GRUs partially address these issues, but further refinement needed.
Researchers focus on improving RNN architectures by making them more efficient, robust, and scalable. Techniques like dynamic computation graphs, better optimisation algorithms, and hybrid models that combine RNNs with other advanced architectures (like transformers) may be key to overcoming traditional RNNs’ limitations.
As computing power continues to grow, more complex and sophisticated RNN-based systems will likely emerge, pushing the boundaries of what’s possible in deep learning.
In Closing
Recurrent Neural Networks (RNNs) have transformed sequential data processing, proving essential in fields like natural language processing and time series forecasting. Their unique architecture allows them to maintain memory, capturing temporal dependencies crucial for accurate predictions. As advancements continue, RNNs will further enhance their applications across various industries.
Frequently Asked Questions
What are Recurrent Neural Networks?
Recurrent Neural Networks (RNNs) are a type of neural network designed to process sequential data by maintaining memory of previous inputs, enabling them to capture temporal dependencies.
How do RNNs Differ from Traditional Neural Networks?
Unlike traditional feedforward neural networks that process inputs independently, RNNs utilise recurrent connections to remember past information, making them suitable for tasks involving sequences.
What are the Common Applications of RNNs?
RNNs are widely used in natural language processing, speech recognition, time series forecasting, music generation, and video processing due to their ability to handle sequential data effectively.
Authors
-

Written by:
Aashi VermaReviewed by: