Summary: Kernel methods in machine learning solve complex data problems using smart functions like the kernel trick. These methods boost model performance without heavy computations. They are widely used in image processing, finance, and bioinformatics. Learn how they work and how to apply them in real-world projects through Pickl.AI’s data science courses.
Introduction
Machine learning often struggles when the data isn’t in a straight line—literally! That’s where things get twisty, and normal tricks don’t work. This is where kernel methods in machine learning come in like superheroes. They help us handle complex, curvy data without even needing to draw those curves ourselves.
Think of them as magic glasses that help machines “see” patterns better. In this blog, I’ll walk you through these methods, how they work, and why they matter—all in simple words. If you’ve ever been curious about smart tech stuff, you’re in the right place. Let’s dive in!
Key Takeaways
- Kernel methods help machine learning models handle non-linear data by transforming it into higher dimensions.
- The kernel trick enables efficient computation without explicitly mapping the data to a new space.
- Common kernel functions include Linear, Polynomial, RBF, and Sigmoid, each serving different data patterns.
- Kernel methods are powerful in image recognition, text classification, bioinformatics, and financial modeling.
- Despite their strengths, they can be slow on large datasets and require careful parameter tuning for best results.
What Are Kernel Methods in Machine Learning?
Kernel methods are a smart technique used in machine learning to deal with complex data. When data is not easy to separate using a straight line, kernel methods help by transforming it in a way that makes it easier to work with, without actually doing the heavy lifting in the background.
A Simple Idea Behind Kernel Methods
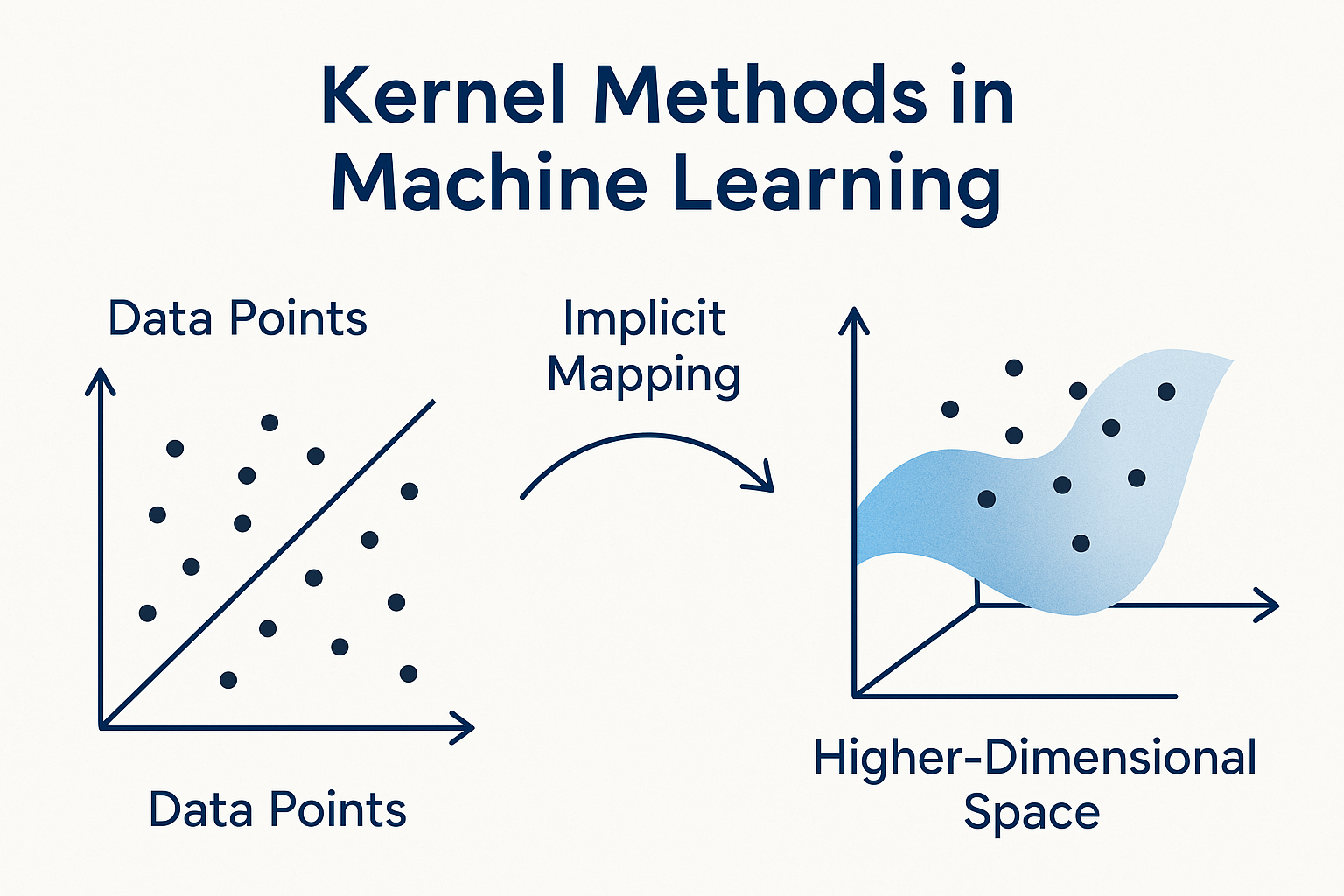
Imagine you have dots on a paper and want to separate them into two groups using a straight line. If they’re all mixed up, it’s hard to do. Kernel methods solve this by “lifting” the data into a new space where it becomes easier to separate. Think of it like changing your viewpoint to solve a puzzle.
Helping Algorithms Like SVM
Support Vector Machines (SVM) are popular machine learning tools that work well with kernel methods. The kernel method helps SVM draw better boundaries between groups, even when the data is not clearly separated.
Working in High-Dimensional Spaces (Without Really Going There)
Kernel methods perform a trick called implicit mapping. This means they act like they are moving data into a higher dimension, but don’t actually do it. This makes them fast and powerful—like solving a 3D puzzle while staying in 2D.
What Is the Kernel Trick?
The kernel trick is a smart shortcut used in machine learning. It helps computers solve problems that are not simple or straight-line (linear) by turning them into problems that look simple without actually doing the hard work of changing the data.
Imagine you’re trying to separate two different groups of dots on paper. If they’re all jumbled and can’t be split with a straight line, the idea is to lift them into 3D space, where separating them becomes easier. The kernel trick lets you do this “lifting” without actually moving the dots or changing the space. It’s like getting the result of a 3D solution while still working in 2D.
Why Do We Need It?
Some problems in machine learning can’t be solved by drawing a straight line between two groups. These problems need to be solved in a curved or twisted way. Usually, that would mean changing the data into a more complex space, which takes time and computer power.
The kernel trick lets us skip that heavy work. It gives us the same answer as if we had changed the space without doing all the background math. This saves time and speeds up the process.
A Simple Example

Let’s say you have points in the shape of a circle. A straight line can’t split the inside and outside points. But if you imagine lifting the points into a 3D space, a flat sheet (like a plane) can separate them easily.
The kernel trick lets you do this “lift” through a formula, without actually moving the points. One popular formula is the Radial Basis Function (RBF) kernel, which works well with circular data like this.
Exploring Different Kernel Functions
Kernel functions help transform data so machines can learn from it more easily. They let us work with complex patterns without heavy computations. Below are some common kernel functions explained in simple terms.
Linear Kernel
The linear kernel is the simplest of all. It works by measuring the distance between data points using a straight-line approach. You use it when your data can be separated with a straight line. It is fast and works well with data that has a clear, linear relationship.
Polynomial Kernel
The polynomial kernel adds more complexity by introducing a curved relationship between data points. It raises the input values to a power, which helps capture more detailed patterns. You choose this kernel when your data shows more curvature and the relationships are not just straight lines. It creates a smoother, flexible boundary that adapts to the data’s shape.
Radial Basis Function (RBF) Kernel
The Radial Basis Function (RBF) kernel, also known as the Gaussian kernel, uses a bell-shaped curve to measure the similarity between data points. This kernel is very popular because it can handle complex, non-linear patterns. Use the RBF kernel when your data clusters in circular shapes or when you expect the relationships to change gradually.
Sigmoid Kernel
The sigmoid kernel works similarly to activation functions in neural networks. It creates an S-shaped curve to transform the data. This kernel is useful for a decision boundary that behaves like a smooth switch. It might work well when the data has a binary-like or switching pattern.
Choosing the Right Kernel
In practice, the choice depends on your data and the problem. Start with the linear kernel for simplicity. Move to the polynomial or RBF kernel if your data shows non-linear patterns. Try the sigmoid kernel when you suspect a switching behavior. Experimenting with different kernels helps you find the best fit for your machine learning model.
Real-World Uses of Kernel Methods in Machine Learning
Kernel methods are not just complex math—they play an important role in solving real-world problems across many fields. Let’s look at how they are used in everyday applications.
Recognising Faces and Classifying Images
Kernel methods help computers understand images. For example, in facial recognition, they can tell one face from another even if the lighting or angle changes. In image classification, they help sort pictures into categories like “cat,” “dog,” or “car” by identifying patterns and shapes.
Understanding Text and Emotions
In the world of language, kernel methods power text classification. They help email apps detect spam or sort messages. They also support sentiment analysis, which means reading reviews or social media posts to determine whether the emotion behind them is positive, negative, or neutral.
Studying Proteins and Genes
In bioinformatics, scientists use kernel methods to study protein structures and genetic data. By identifying patterns in biological data, they help in disease research and drug development.
Predicting Financial Trends
Kernel methods are also used in financial modeling. They help analyse time-series data, like stock prices or sales trends, and can predict future movements by learning from past patterns.
Benefits of Using Kernel Methods
Using kernel functions, we can make models smarter and more flexible, without too much heavy lifting. Here are some key advantages of using kernel methods:
- Handle Complex Data Easily: Kernel methods are great at solving problems where data isn’t in a straight line or simple shape. They can detect patterns in twisted or curved data that basic models may miss.
- No Need for Manual Feature Transformation: Turning data into a form that a model can understand takes a lot of effort. With kernel methods, this happens automatically through a mathematical trick (the kernel trick), so you don’t need to create new features manually.
- Work Well in High Dimensions: Some problems have many features (like hundreds or thousands). Kernel methods can easily handle this, making them perfect for image, text, or genetic data.
- Support Non-Linear Decision Boundaries: Unlike simple models that draw straight lines, kernel methods can create curved boundaries, helping them make better predictions.
- Improve Accuracy: With the right kernel, models become more accurate and reliable, especially with tricky datasets.
Limitations of Using Kernel Methods
While kernel methods are powerful tools in machine learning, they also have drawbacks. Understanding these limitations is important, especially when working with large or complex datasets. Below are some key reasons why kernel methods might not always be the best choice:
- Slow on Large Datasets: Kernel methods can be very slow when dealing with a lot of data. This is because the algorithm needs to compare every data point with every other one, which takes time and memory.
- Hard to Choose the Right Kernel: Picking the proper kernel function is not easy. If you choose the wrong one, your model may not work well. It often takes multiple tries and tuning to find the best fit.
- Difficult to Understand: Kernel methods do a lot of calculations behind the scenes, which makes it hard to explain how the model is making decisions. This lack of clarity can be problematic, especially in fields where trust and transparency are essential.
- Sensitive to Parameters: These methods often require fine-tuning of parameters. A small change can make the model behave very differently, which can be tricky for beginners.
Closing Thoughts
Kernel methods in machine learning offer a smart solution to complex, non-linear data problems. By using the kernel trick, these methods make it easier for algorithms to draw accurate decision boundaries without heavy computations. Whether it’s image recognition, text analysis, or financial modeling, kernel methods help uncover deeper insights from data.
If you’re fascinated by such concepts and want to dive deeper into the world of data science, consider joining Pickl.AI’s data science courses. With hands-on projects and expert mentoring, you’ll gain practical knowledge to apply powerful techniques like kernel methods in real-world scenarios.
Frequently Asked Questions
What are kernel methods in machine learning?
Kernel methods transform data into higher dimensions using mathematical functions. This helps machine learning models, especially Support Vector Machines (SVM), handle complex, non-linear data patterns without explicitly performing the transformation. Kernel methods improve prediction accuracy for real-world problems like image, text, and bioinformatics analysis.
Why is the kernel trick important in machine learning?
The kernel trick allows algorithms to perform complex transformations on data implicitly, avoiding the computational cost of actual mapping. It enables models to find better decision boundaries in non-linear datasets, making them powerful for image classification, sentiment analysis, and pattern recognition in financial data.
Which kernel function is best for non-linear data?
The Radial Basis Function (RBF) kernel is best for non-linear data. It measures similarity using a bell-shaped curve, making it ideal for capturing complex patterns in datasets. Due to its flexibility, RBF is widely used in real-world applications like face recognition, fraud detection, and gene classification.
Authors
-

Written by:
Versha RawatReviewed by: