
Summary: Federated Learning allows decentralised model training while keeping data on local devices, enhancing privacy and efficiency. Examples include Google’s predictive text and healthcare applications. It offers a significant improvement over traditional methods, though challenges remain.
Introduction
Machine Learning has evolved significantly, from basic algorithms to advanced models that drive today’s AI innovations. A key advancement is Federated Learning, which enhances privacy and efficiency by training models across decentralised devices. This method, known as federated Machine Learning, allows data to remain on local devices while models are updated collaboratively.
The significance of Federated Learning lies in its ability to maintain data privacy and reduce communication costs. This article aims to explore Federated Learning, provide examples of its applications, and highlight its impact on Machine Learning practices.
What is Federated Learning?
It is a decentralised approach to Machine Learning that allows multiple parties to collaboratively train a model without sharing their data. Unlike traditional Machine Learning, where data is centralised in one location for training, Federated Learning keeps data on local devices or servers.
The model is trained across these decentralised nodes; only the updates or gradients are shared with a central server. This approach enhances privacy and security, as sensitive data never leaves its original location.
Comparison with Traditional Machine Learning Approaches
In traditional Machine Learning, all data is aggregated and stored in a central repository where it is used to train models. This centralised method poses significant privacy risks, especially when dealing with sensitive information. Additionally, substantial computational resources and bandwidth are required for data transfer and processing.
On the other hand, Federated Learning addresses these issues by keeping data local and only sending model updates to a central server. This decentralised approach minimises data movement and reduces the risk of exposure.
It also enables models to be trained on diverse data sources, potentially leading to better generalisation and performance. While traditional Machine Learning often involves data silos and security concerns, Federated Learning offers a more privacy-preserving solution that can operate effectively across various environments.
Key Principles of Federated Learning
By embracing these principles, Federated Learning represents a significant advancement in Machine Learning, offering a more secure, efficient, and privacy-conscious approach to model training.
Data Privacy
One of the core principles of Federated Learning is preserving data privacy. By ensuring that data remains on local devices and only model updates are shared, It reduces the risk of exposing or misusing sensitive information.
Decentralised Training
It operates on a decentralised architecture. Multiple local nodes train the model instead of a single central server processing all the data. Each node trains the model on its data and then sends the model updates (not the data itself) to a central server, aggregating these updates to improve the global model.
Model Aggregation
The central server aggregates the updates received from various nodes to form an improved global model. This aggregation process typically involves averaging the updates or applying more complex techniques to ensure that the model accurately reflects the collective knowledge from all participating nodes.
Communication Efficiency
Since Federated Learning involves transmitting only model updates rather than raw data, it reduces the amount of data that needs to be transferred. This efficiency helps mitigate network bandwidth issues and ensures faster model convergence.
Scalability
Federated Learning is inherently scalable because it leverages the computational power of multiple devices. As more nodes join the network, the system can handle larger datasets and more complex models without overwhelming any single device or server.
Types of Federated Learning
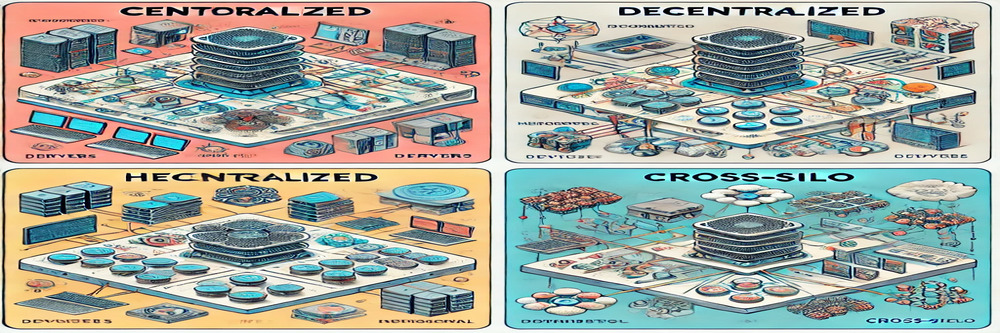
It can be categorised into various types based on structures and communication strategies. Each type has unique characteristics, advantages, and challenges that suit different applications. This section explores the four main types of Federated Learning: centralised, decentralised, hierarchical, and cross-silo Federated Learning.
Centralised Federated Learning
Centralised Federated Learning is the most widely recognised type, where a central server plays a crucial role in coordinating the learning process. The individual devices or nodes (clients) train their local models on their respective datasets and send the model updates (not raw data) to the central server.
The server aggregates these updates to build a global model, which is then sent back to all clients for further refinement.
How It Works
- Model Training: Each client trains a model locally on its private data.
- Model Aggregation: The central server collects and aggregates updates from each client (typically using averaging algorithms).
- Global Model Distribution: The aggregated global model is sent back to clients for the next round of local training.
- Repeat Process: The process continues until the global model converges or meets the desired performance criteria.
Advantages
- Efficient coordination: A single server can oversee the entire process.
- High model accuracy: Aggregating updates from multiple clients often results in a robust global model.
- Easy implementation: Centralised architectures are simpler to set up than decentralised alternatives.
Disadvantages
- Centralised risks: If the central server fails or is compromised, the entire system can be disrupted.
- Communication bottlenecks: As the number of clients increases, transmitting updates to and from the central server can become inefficient.
- Privacy vulnerability: Even though raw data is not shared, the central server could still become a target for attacks, potentially leaking sensitive model updates or client information.
Decentralised Federated Learning
Decentralised Federated Learning eliminates the need for a central server by allowing clients to communicate directly with each other. In this model, clients share their locally trained models with neighbouring clients or form networks where updates are exchanged peer-to-peer. The system then aggregates these updates through decentralised consensus algorithms.
How It Works
- Local Training: Each client trains its model locally on its private dataset.
- Peer-to-Peer Sharing: Clients share their model updates with other nearby clients or within a network.
- Decentralised Consensus: Algorithms such as gossip protocols or blockchain-like systems ensure the updates correctly aggregated across all clients.
- Model Validation: Clients validate the updates received from peers before integrating them into their models, ensuring data consistency and model reliability.
Advantages
- Enhanced privacy: With no central server, there’s less risk of a single point of failure or attack.
- Resilience: The system can continue functioning even if some clients drop out or experience network issues.
- Scalability: The absence of a central server allows the system to scale across many clients without bottlenecks.
Disadvantages
- Complexity: Decentralised systems are more complex to implement and manage.
- Slower convergence: Without a central authority to aggregate updates, models might take longer to converge.
- Higher communication costs: Direct peer-to-peer communication can lead to increased network traffic.
Hierarchical Federated Learning
Hierarchical Federated Learning introduces a multi-layered architecture in which several local clients grouped into clusters, each with its server.
These cluster servers play a role similar to that of the central server in centralised but operate within smaller groups of clients. The cluster servers then communicate with a central server to form the final global model.
How It Works
- Local Model Training: Each client within a cluster trains its model locally on its data.
- Cluster-Level Aggregation: Client model updates are sent to the cluster server, which aggregates the updates within that cluster.
- Global Aggregation: The central server collects aggregated updates from each cluster and forms an international model.
- Model Refinement: The global model is sent back to cluster servers, which distribute it to clients for further fine-tuning based on local data.
Advantages
- Improved scalability: The hierarchical structure allows large networks of clients to efficiently managed.
- Reduced communication overhead: Only cluster servers communicate with the central server, reducing network traffic.
- Flexibility: The system can adapted to different networks or organisations.
Disadvantages
- Increased complexity: Setting up a hierarchical system requires more coordination and management.
- Potential privacy risks: While client data stays local, cluster servers might introduce points of vulnerability.
- Delayed convergence: The multi-layered structure can lead to slower convergence times, as updates need to pass through multiple aggregation layers.
Cross-Silo Federated Learning
Cross-silo Federated Learning focuses on large institutions or organisations that wish to collaborate without sharing their private data. Unlike typical Federated Learning, which involves many individual devices, cross-silo Federated Learning operates between a few trusted parties, such as hospitals, banks, or corporations.
The organisations collaborate to train a global model while keeping their data within their respective silos.
How It Works
- Institution-Level Training: Each organisation trains its model on local institutional data.
- Collaborative Aggregation: Model updates shared directly or through a central server among the collaborating institutions.
- Global Model Development: Updates from all participating silos aggregated into a worldwide model.
- Periodic Synchronisation: Institutions periodically synchronise their model updates, allowing them to refine and enhance the global model over time and ensure continuous learning.
Advantages
- Trust and privacy: Organisations with strict data privacy regulations can collaborate without sharing sensitive data.
- High-quality models: The global model benefits from diverse datasets, improving its generalisation capabilities.
- Suited for specific sectors: This approach is instrumental in industries such as healthcare and finance, where data sharing restricted.
Disadvantages
- Limited scalability: Since this model is typically use with a few institutions, it may not scale as quickly as other types of Federated Learning.
- Trust issues: Organisations must trust the other parties to follow proper procedures for secure model updates and aggregation.
- Increased communication costs: Frequent synchronisation and secure communication between institutions can lead to higher bandwidth and computational expenses, making the process less efficient.
Examples of Federated Learning in Practice
It has gained significant traction across industries where data privacy, security, and distributed data sources are critical. Below are a few real-world examples of how Federated Learning applied across different sectors:
Healthcare
Hospitals and research institutions use Federated Learning to train Machine Learning models on patient data without compromising patient privacy. For example, It enables medical image analysis to detect diseases like cancer or predict outcomes while keeping patient records confidential.
Finance
Banks and financial institutions apply to detect fraud, improve credit scoring, and offer personalised services. Without sharing customer transaction data, institutions collaboratively build stronger models for fraud detection across networks.
Mobile Devices
Companies like Google use Federated Learning in smartphones for personalised services, such as improving predictive text or voice recognition, without accessing personal data on the device. This allows for enhanced user experience while maintaining data privacy.
Smart Cities
It optimises traffic management systems and public transportation routes in smart cities. Multiple sensors and data points across the city contribute to a model without centralising sensitive urban data.
Challenges and Limitations

It offers numerous benefits, particularly in maintaining data privacy and enabling decentralised Machine Learning. However, it also comes with several challenges and limitations that hinder its widespread adoption. Below are some key challenges that developers and organisations face when implementing Federated Learning models:
Data Privacy and Security Risks
While Federated Learning reduces the need to transfer data, it can still be vulnerable to attacks. Malicious actors can potentially reverse-engineer the model to gain insights into individual data points.
Communication Overhead
Transmitting model updates from distributed devices to a central server requires significant bandwidth and computing power. This communication process can slow down the learning and training, especially in resource-constrained environments.
Data Heterogeneity
Federated Learning systems operate on decentralised data, often from different sources. Data distribution and quality variation across devices can lead to skewed models, reducing their accuracy.
Model Performance and Convergence
Achieving model convergence in Federated Learning is more complex than in centralised systems. Due to distributed training, it may take longer to train models, and the resulting models may not perform as well due to inconsistencies in the data.
Regulatory and Compliance Issues
Some industries, such as healthcare and finance, face stringent regulations regarding data handling. Must ensure compliance with these laws, which can complicate implementation.
Future Directions and Trends
It is a rapidly evolving area in Machine Learning with significant potential to revolutionise data privacy and collaborative learning. New research areas and trends promise to enhance capabilities as technology advances. Here, we explore the future directions and trends shaping this field.
Emerging Research Areas and Advancements in Federated Learning
Researchers focused on addressing key challenges like communication efficiency, model accuracy, and data security. New algorithms developed to reduce the communication overhead between devices while maintaining model performance.
Furthermore, privacy-preserving techniques, such as differential privacy and secure multi-party computation, are gaining attention to enhance data protection in Federated Learning environments. Researchers are also improving model personalisation, allowing devices to tailor global models to local data while benefiting from the collective learning process.
Potential Impact on Various Industries
This is poised to make a significant impact across various sectors. In healthcare, it can enable medical institutions to collaboratively train models on patient data without compromising privacy, leading to better diagnostics and treatments.
In finance, Federated Learning can enhance fraud detection by allowing institutions to share insights without exposing sensitive financial data. Smart cities can also benefit from Federated Learning by improving urban planning, traffic management, and energy distribution, all while keeping citizen data private and secure.
Integration with Other Technologies
Federated Learning is increasingly being integrat with complementary technologies. Edge computing is a natural fit, enabling data processing closer to where data is generate, reducing latency and improving real-time decision-making.
Additionally, blockchain is being explore to ensure transparency and trust in federated networks by providing secure, decentralised data sharing and management. Combining these technologies will likely lead to more robust and efficient systems soon.
Conclusion
Federated Learning represents a significant shift in Machine Learning. It focuses on decentralised model training to enhance privacy and efficiency. It addresses key challenges of traditional methods by keeping data local and only sharing model updates.
Its applications across sectors like healthcare and finance highlight its potential, though challenges remain. Future advancements in Federated Learning promise to overcome these hurdles, integrating with technologies like edge computing and blockchain for improved performance and security.
Frequently Asked Questions
What is Federated Learning?
Federated Learning is a decentralised Machine Learning approach where multiple parties collaboratively train a model without sharing raw data. Instead, only model updates shared, preserving data privacy and reducing communication costs.
How Does Federated Learning Differ from traditional Machine Learning?
Unlike traditional Machine Learning, which centralises data for model training, Federated Learning keeps data on local devices and only shares model updates. This approach enhances privacy and reduces the risk of data exposure.
Can You Provide a Federated Learning Example?
A common example is Google’s use of Federated Learning to improve smartphone predictive text. The model trained locally on users’ devices, enhancing text prediction while maintaining data privacy.
Authors
-

Written by:
Smith AlexReviewed by:



