
Summary: Deep Boltzmann Machine (DBMs) enhance Boltzmann Machines with multiple hidden layers, allowing them to model complex data distributions. They are used in feature learning, dimensionality reduction, and advanced applications like image recognition.
Introduction
Deep Learning revolutionises understanding and processing complex data, employing neural networks with multiple layers to extract intricate features. At the core of this technology lies the Boltzmann Machine, a probabilistic model that learns to represent data distributions.
The Deep Boltzmann Machine (DBM), an advanced variant, extends this concept by stacking multiple layers of hidden units, enhancing its capacity for deep learning tasks.
This blog explores the fundamentals of Deep Boltzmann Machines (DBMs), their architectural nuances, and their impact on various applications. Understanding DBMs unlocks new potential in feature learning and data representation.
What are Boltzmann Machines?
Boltzmann Machines are a type of probabilistic graphical model used in machine learning and statistical mechanics. They consist of an interconnected network of units or nodes. Each node represents a variable in the model, and the connections between nodes are weighted to signify relationships.
The core concept behind Boltzmann Machines is to model complex probability distributions over the data by learning the joint probability of the variables in the network. These models operate by minimising an energy function, which helps find patterns and correlations in the data.
Types of Boltzmann Machines
There are two main types of Boltzmann Machines: restricted Boltzmann Machines (RBMs) and Deep Boltzmann Machines (DBMs). Although I am defining the terms here, you will read more about them later in this blog.
Restricted Boltzmann Machines (RBMs)
RBMs are a simplified version of Boltzmann Machines with limited connections. They consist of visible and hidden layers, but no connections exist between the nodes within the same layer. This restriction simplifies training and makes RBMs more computationally feasible. RBMs are widely used for feature learning and dimensionality reduction.
Deep Boltzmann Machines (DBMs)
DBMs extend RBMs by adding multiple hidden layers, forming a hierarchical structure. This multi-layer architecture enables DBMs to model more complex distributions and capture higher-level abstractions. Training DBMs involves learning the parameters of all layers simultaneously, which can be more challenging than training RBMs.
Applications of Boltzmann Machines in Machine Learning
Boltzmann Machines have various applications in machine learning. RBMs are frequently used for unsupervised learning tasks such as feature extraction and dimensionality reduction. They also serve as building blocks for more complex models like Deep Belief Networks (DBNs).
DBMs, with their deep architecture, excel in capturing high-level features in data, making them valuable for advanced tasks like object recognition and generative modelling.
Understanding Deep Boltzmann Machines (DBMs)
A Deep Boltzmann Machine (DBM) is an undirected graphical model that learns to represent the joint distribution of visible and hidden variables through multiple layers of hidden units. It comprises a stack of Restricted Boltzmann Machines (RBMs), where each layer learns to model the data features from the previous layer.
This hierarchical structure enables DBMs to understand complex and abstract representations of input data.
Difference between DBMs and RBMs
The primary difference between DBMs and Restricted Boltzmann Machines (RBMs) is their architectural complexity. RBMs consist of a single layer of visible and hidden units, making them suitable for capturing simpler patterns.
In contrast, DBMs have multiple hidden layers, allowing them to model more intricate relationships within the data. While RBMs are limited to shallow learning, DBMs leverage their deep architecture to uncover higher-level features through deeper layers of abstraction.
Architecture of DBMs
- Visible Layer: The visible layer of a DBM represents the observed data or input variables. Each unit in this layer corresponds to an observable feature of the dataset. For instance, in image data, each visible unit could represent a pixel or a group of pixels.
- Hidden Layers: DBMs contain multiple hidden layers that are fully connected but not directly connected to the visible layer. These hidden layers learn increasingly abstract data representations as the network depth increases. The lower hidden layers capture basic features, while the deeper ones identify more complex patterns and structures.
- Connections Between Layers: In a DBM, each layer of hidden units is connected to the layers immediately above and below it. However, units within the same layer do not interact with each other. These connections allow information to flow through the network, enabling the model to learn multi-level features. The connections are typically weighted, and learning involves adjusting these weights to optimise the model’s performance in representing the data distribution.
Overall, Deep Boltzmann Machines offer a powerful framework for learning deep, hierarchical representations of data. Leveraging multiple hidden layers can uncover intricate patterns and relationships that simpler models might miss, making them a valuable tool in deep learning.
How Deep Boltzmann Machines Work

Deep Boltzmann Machines (DBMs) are a type of generative stochastic neural network that extend the capabilities of Boltzmann Machines by incorporating multiple hidden layers. This structure allows DBMs to model complex probability distributions over high-dimensional data. Here’s a look into how DBMs function, their energy function, training methods, and learning objectives.
Energy Function and Probability Distribution
The core of a Deep Boltzmann Machine lies in its energy function, which quantifies the likelihood of a particular configuration of visible and hidden units. For a DBM, the energy function E(v,h) is defined for a visible vector v and a hidden vector h.
The goal is to learn the weights that minimise the observed data’s energy while maximising the data’s probability under the model.
In DBMs, the energy function is given by:
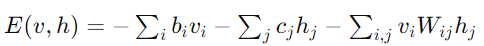
Where bi and cj are biases for the visible and hidden units, respectively, and Wij represents the weights between visible unit i and hidden unit j. This function helps in defining the joint probability distribution of the visible and hidden variables, which is expressed through the Boltzmann distribution:
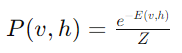
Where Z is the partition function that normalises the distribution.
Training Deep Boltzmann Machines
Training DBMs involves learning the parameters (weights and biases) best fitting the data. This process is complex due to the high dimensionality and the need for approximations. Two critical techniques for training DBMs are Contrastive Divergence and Gibbs Sampling.
Contrastive Divergence
Contrastive Divergence (CD) is a widely used method for training Boltzmann Machines, including DBMs. CD’s essence is to approximate the gradient of the log-likelihood function. It works by initialising the model parameters with training data and then updating them based on the difference between the data’s expected distribution and the model’s distribution.
During training, CD performs the following steps:
- Initialise: Start with a visible data vector and compute the corresponding hidden activations.
- Update: Perform a series of Gibbs Sampling steps to generate samples from the model distribution.
- Calculate Gradients: Compute the gradients of the log-likelihood concerning the weights and biases.
- Update Parameters: Adjust the weights and biases using these gradients.
Gibbs Sampling
Gibbs Sampling is a Markov Chain Monte Carlo (MCMC) method used to sample from the distribution defined by the DBM’s energy function. It works by iteratively sampling each variable while keeping the others fixed. In the context of DBMs, Gibbs Sampling helps approximate the marginal probabilities of hidden units given the visible units and vice versa.
The process involves:
- Initialisation: Start with an initial state of visible and hidden units.
- Iterate: Update the state of each unit sequentially by sampling from the conditional distribution of that unit, given the current state of the others.
- Repeat: Continue this process for several iterations to converge to the desired distribution.
Learning Process and Objective
The learning objective for DBMs is to minimise the difference between the data distribution and the model distribution. This is achieved by optimising the energy function through gradient descent methods. The process involves iterating over the data to adjust the parameters so that the model becomes better at representing the observed data.
During training, DBMs aim to capture the underlying patterns and structures in the data by learning the complex relationships between variables across multiple layers. The ultimate goal is to build a model that generates high-quality samples and effectively represents the input data distribution.
Applications of DBMs

Deep Boltzmann Machines (DBMs) offer versatile applications across various machine learning and artificial intelligence domains. Their ability to model complex distributions and learn rich representations makes them valuable tools in multiple areas. Here, we explore some of the key applications of DBMs.
Feature Learning and Representation
DBMs excel at learning high-level features from raw data, making them powerful for feature learning and representation. By capturing intricate patterns and relationships within the data, DBMs can automatically extract valuable features without needing explicit manual feature engineering.
This ability to learn representations helps create robust models for various tasks, enhancing the quality and performance of machine learning applications.
Read Blogs:
Feature Engineering in Machine Learning.
Introduction to Feature Scaling in Machine Learning.
Dimensionality Reduction
In high-dimensional datasets, dimensionality reduction is crucial for simplifying data while retaining essential information. DBMs contribute significantly to this process by learning lower-dimensional representations of the data.
They achieve this by compressing complex input data into a more manageable form, facilitating more efficient processing and visualisation. This aspect of DBMs is beneficial in scenarios where data complexity needs to be reduced while preserving essential features for analysis and prediction.
Applications in Image Recognition and Natural Language Processing
DBMs help identify and categorise objects in image recognition by learning hierarchical feature representations from raw image data. Their deep architecture allows them to capture detailed visual patterns, improving accuracy in recognising objects and scenes.
In Natural Language Processing (NLP), DBMs contribute to text generation and sentiment analysis tasks. They can learn semantic structures and dependencies within text, enabling the model to understand and generate human-like text with greater context awareness.
Overall, DBMs enhance capabilities in feature learning, dimensionality reduction, and practical applications like image recognition and NLP, showcasing their significance in advancing machine learning technologies.
Benefits of Using DBMs in Deep Learning
Deep Boltzmann Machines (DBMs) offer several significant advantages in deep learning, enhancing various aspects of data modelling and representation. Leveraging DBMs’ strengths can improve performance and novel insights in complex tasks.
Effective Feature Learning
DBMs excel at learning hierarchical features from data, enabling the model to capture intricate patterns and representations without extensive manual feature engineering.
Dimensionality Reduction
By compressing high-dimensional data into lower-dimensional representations, DBMs facilitate more efficient data processing and visualisation while preserving essential information.
Generative Capabilities
DBMs can generate new samples that resemble the training data, making them useful for tasks like data augmentation and synthetic data generation.
Flexibility in Modelling Complex Data
DBMs handle various data types, including images, text, and time series, allowing for versatile applications across different domains.
Enhanced Learning from Unlabelled Data
DBMs can be trained using unsupervised learning techniques, effectively leveraging large amounts of unlabeled data and improving performance on downstream tasks.
These benefits highlight how DBMs contribute to advancing deep learning techniques, making them valuable tools for data scientists and researchers.
Common Challenges and Limitations
Deep Boltzmann Machines (DBMs) present several challenges and limitations despite their powerful capabilities in deep learning. Addressing these issues is crucial for effective implementation and research.
Computational Complexity
Training DBMs involves significant computational resources. Compared to other models, the need to perform extensive calculations during the learning phase can make DBMs slow and resource-intensive.
Training Difficulties
DBMs are notoriously difficult to train. The training process often requires careful tuning of parameters and may suffer from issues such as slow convergence and vanishing gradients.
Overfitting
Due to their complex structure, DBMs can easily overfit the training data if they are not adequately regularised. This can lead to poor generalisation of new, unseen data.
Scalability Issues
As the dataset’s size or the model’s complexity increases, DBMs may need help to scale effectively. This scalability issue can limit their practicality in real-world applications.
Interpretability
DBMs’ deep and complex nature makes them challenging to interpret. Understanding how the model arrives at specific conclusions can be difficult, which impacts their transparency and trustworthiness in decision-making.
Addressing these challenges requires ongoing research and development to enhance the efficiency and effectiveness of DBMs in various applications.
Comparison with Other Deep Learning Models
When evaluating Deep Boltzmann Machines (DBMs), it’s crucial to compare them with other popular deep learning models to understand their unique advantages and limitations. Here, we explore how DBMs stand against Deep Belief Networks (DBNs), Variational Autoencoders (VAEs), and Generative Adversarial Networks (GANs).
DBMs vs. Deep Belief Networks (DBNs)
Deep Belief Networks (DBNs) and Deep Boltzmann Machines (DBMs) share similarities in their hierarchical structure, consisting of multiple layers of stochastic hidden units. Both models are generative and use Restricted Boltzmann Machines (RBMs) as building blocks.
However, DBNs use a layer-by-layer greedy training approach, where each RBM is trained individually and then fine-tuned together. In contrast, DBMs train all layers simultaneously using a joint energy function, allowing for more complex, high-level feature extraction. Due to their deeper structure and holistic training method, DBMs offer more robust feature learning capabilities.
DBMs vs. Variational Autoencoders (VAEs)
Variational Autoencoders (VAEs) and DBMs differ significantly in their approaches to generative modelling. VAEs are based on variational inference and rely on a probabilistic encoder-decoder architecture. They aim to learn a distribution over data by minimising the divergence between the learned distribution and a prior distribution.
In contrast, DBMs focus on learning a joint probability distribution over visible and hidden variables through energy minimisation. While VAEs excel in producing smooth and continuous latent spaces suitable for generating new data, DBMs’ energy-based modelling approach offers a more intricate understanding of data distribution.
DBMs vs. Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) and Deep Boltzmann Machines (DBMs) have different data-generating mechanisms. GANs consist of two networks, a generator and a discriminator, that compete in a game-theoretic framework to produce realistic data. This adversarial process drives the generator to create data closely mimicking the real distribution.
DBMs, on the other hand, do not involve a discriminative network but focus on learning a joint distribution through energy functions. While GANs are often more effective in generating high-quality synthetic data, DBMs are better suited for understanding data’s underlying structure and features.
Bottom Line
Deep Boltzmann Machines (DBMs) are advanced probabilistic models that enhance the capability of traditional Boltzmann Machines by adding multiple hidden layers. This deep architecture allows DBMs to capture more complex patterns and high-level features in data, making them invaluable for tasks such as image recognition and feature learning.
Despite challenges in training and computational demands, DBMs offer significant advantages in understanding and modelling intricate data distributions.
Frequently Asked Questions
What is a Deep Boltzmann Machine?
A Deep Boltzmann Machine (DBM) is a probabilistic model with multiple hidden layers that learns complex data representations. It extends the concept of Boltzmann Machines by stacking layers to capture high-level features and model intricate distributions.
How does a Deep Boltzmann Machine differ from a Restricted Boltzmann Machine?
Deep Boltzmann Machines (DBMs) differ from Restricted Boltzmann Machines (RBMs) by having multiple hidden layers. This allows DBMs to model more complex data distributions, while RBMs are simpler, with only one layer of hidden units, making them less capable of capturing deep features.
What are common applications of Deep Boltzmann Machines?
Deep Boltzmann Machines excel in feature learning, dimensionality reduction, and complex data modelling. They are used in image recognition, Natural Language Processing, and other advanced tasks that benefit from their deep, hierarchical learning capabilities.
Authors
-

Written by:
Aashi VermaReviewed by:



