
Summary: Cross-validation in Machine Learning is vital for evaluating model performance and ensuring generalisation to unseen data. Controlling datasets into training and testing subsets helps mitigate overfitting and provides a more accurate performance estimate. Various methods, like K-Fold and Stratified K-Fold, cater to different Data Scenarios.
Introduction
In this article, we will explore the concept of cross-validation in Machine Learning, a crucial technique for assessing model performance and generalisation. The global Machine Learning market was valued at $15.44 billion in 2021 and is projected to grow to $209.91 billion by 2029. There is estimated to be a remarkable compound annual growth rate (CAGR) of 38.8%.
Thus, achieving accurate and reliable models is more critical than ever. This blog highlights the importance of cross-validation in ensuring model robustness and avoiding overfitting. We will cover its various types, benefits, challenges, real-world applications, and practical implementation examples to enhance your understanding of the process.
Key Takeaways
- Cross-validation improves model reliability by using multiple training-test splits.
- It helps detect overfitting and underfitting issues effectively.
- Different types of cross-validation cater to various dataset characteristics.
- The technique maximises data utilisation, especially in limited datasets.
- Cross-validation can be computationally intensive but is crucial for accurate model assessment.
What is Cross-Validation?
Cross-validation is a Machine Learning technique used to assess a model’s performance by partitioning the dataset into subsets. The model is trained on some of these subsets and tested on the remaining data, ensuring that each data point is used for training and validation at least once.
This method provides a more reliable estimate of model performance than simply splitting the data into a single training and test set.
Why is Cross Validation Used?
One primary reason cross-validation is used is to reduce overfitting. When a model is trained on a single training set and evaluated on a separate test set, there’s a risk that the model may memorise the training data (overfitting) and perform poorly on unseen data.
Cross-validation mitigates this using multiple training-test splits, ensuring the model generalises well across various data subsets.
Cross-validation also helps ensure reliable model performance by providing a comprehensive evaluation. Multiple test sets help capture the data’s variability, leading to a more accurate estimate of how the model will perform in real-world scenarios. This process helps Data Scientists choose the best model and adjust parameters, increasing confidence in its predictive power.
Types of Cross-Validation
Several cross-validation methods exist, each suited to different problems and datasets. In this section, we will explore the most commonly used types of cross-validation: K-Fold, Leave-One-Out, Stratified K-Fold, Group K-Fold, and Time Series Cross-Validation.
K-Fold Cross Validation
K-Fold cross-validation is one of the most widely used methods for model validation. This approach divides the dataset into K equally sized subsets or “folds”. For each iteration, one fold is used as the test set, while the remaining K-1 folds are used as the training set.
This process is repeated K times, each with a different fold serving as the test set. Finally, each K iteration’s performance scores are averaged to produce a single performance metric, such as accuracy or mean squared error.
The main advantage of K-Fold cross-validation is its ability to reduce bias and variance in model evaluation. Since each data point is used for training and testing, the method provides a more reliable estimate of model performance than a simple train-test split.
However, K-Fold cross-validation can be computationally expensive, especially when the value of K is large or when working with big datasets. It also assumes that the data is randomly and uniformly distributed, which may not always be the case in some applications.
Leave-One-Out Cross Validation (LOO)
Leave-One-Out Cross Validation (LOO) is an extreme case of K-Fold cross-validation where K is set to the number of data points in the dataset. In each iteration, a single data point is held out as the test set, while the rest of the data is used for training.
This process is repeated for every data point in the dataset, so the model will be trained and tested N times if there are N data points.
LOO is especially useful when the dataset is small, as it maximises available data usage. It can provide a very low-bias estimate of model performance. However, LOO can be computationally prohibitive for large datasets because it requires training the model N times.
Additionally, the small size of each training set may lead to high variance in the performance metrics.
Stratified K-Fold Cross Validation
Stratified K-Fold Cross Validation is a variant of K-Fold cross-validation that ensures each fold has approximately the same percentage of samples for each class as the entire dataset. This is particularly important in classification problems where the class distribution may be imbalanced, meaning some classes are overrepresented while others are underrepresented.
In standard K-Fold cross-validation, the data is randomly split into K subsets, which may lead to some folds containing disproportionate numbers of classes. Stratified K-Fold ensures that each fold mirrors the overall class distribution, thus providing a more reliable evaluation of the model’s performance.
Stratified K-Fold is crucial in classification tasks with imbalanced datasets, where some classes have fewer instances than others. It prevents the model from being biased toward the majority class, ensuring that the evaluation metric reflects how well the model performs across all classes.
Group K-Fold Cross Validation
Group K-Fold Cross Validation is a variant of K-Fold used when data points are grouped and should not be split across different folds.
For example, when data points are related by some grouping factor (e.g., patients within the same family or measurements from the same subject), keeping all the data from a single group together in the training or test set is essential.
Group K-Fold divides the dataset based on predefined groups rather than random sampling. During each fold, each group is entirely assigned to either the training or test set, ensuring that no data leakage occurs from one group to another.
Group K-Fold is commonly applied in medical or social science research where data points are correlated within groups. This method ensures that related data points are kept together to maintain the integrity of the validation process.
Time Series Cross Validation
Time Series Cross Validation is explicitly designed for datasets with temporal dependencies, where the order of data matters. In time series analysis, splitting data randomly, as in traditional cross-validation, is not appropriate because it ignores the time-dependent nature of the data.
In this method, the dataset is divided into training and test sets in a way that respects the temporal order. Typically, this involves expanding the training set with each fold and testing the model on the subsequent period.
For example, if you have data from 10 years, the first fold might train the model on data from years 1 to 5 and test it on year 6, then train it on data from years 1 to 6 and test on year 7, and so on.
Time Series Cross Validation is crucial for forecasting and predicting trends over time, where future values depend on past data. By ensuring that future data points are not used for training the model, this method prevents data leakage and better simulates real-world conditions where the model is applied to future, unseen data.
Each cross-validation technique is key in evaluating Machine Learning models under different scenarios. Choosing the right method depends on the dataset, problem, and the available computational resources.
How Cross-Validation Works?
Cross-validation is a powerful technique for evaluating the effectiveness of Machine Learning models. It provides a more accurate estimate of a model’s performance by using different subsets of the dataset for training and testing.
This helps assess how well the model generalises to unseen data. Below is a breakdown of cross-validation, the metrics used to evaluate model performance, and the importance of hyperparameter tuning.
Step-by-Step Process of Performing Cross-Validation
Cross-validation follows a systematic approach to divide and test the dataset. By splitting the data into multiple parts and ensuring each part serves as training and testing data, the method helps prevent overfitting and ensures the model’s reliability. Here’s how it’s done:
- Divide the Dataset: The dataset is split into K equal parts, also known as folds. Each fold is a test set once for K-Fold cross-validation, while the remaining K-1 folds are used to train the model.
- Train and Test: The model is trained on the K-1 training folds and evaluated on the remaining fold. This process is repeated K times, with each fold used as the test set exactly once.
- Average the Results: After K iterations, the performance metrics are averaged to estimate the model’s effectiveness.
Metrics Used to Evaluate Model Performance
Cross-validation provides key insights into a model’s accuracy, precision, recall, and other important metrics. These metrics help determine how well the model performs and identify potential bias or variance issues. Let’s look at the most commonly used metrics:
- Accuracy: Measures the percentage of correct predictions made by the model. It’s the most basic metric but may not always be sufficient, especially in imbalanced datasets.
- Precision: This measure focuses on how many of the predicted positive cases were actually positive, helping to assess false positives.
- Recall: Assesses how many of the actual positive cases the model correctly identified, highlighting false negatives.
- F1-Score: The harmonic mean of precision and recall, providing a balanced metric, especially when dealing with imbalanced classes.
Importance of Hyperparameter Tuning
Hyperparameter tuning refers to adjusting parameters to optimise a model’s performance. Cross-validation plays a crucial role in this process by allowing you to evaluate the effects of different hyperparameter combinations in a controlled way.
Without cross-validation, hyperparameters might be tuned to perform well on a specific subset of data, leading to overfitting. Cross-validation ensures that the chosen hyperparameters improve the model’s performance across all subsets, making it more generalisable and robust.
Advantages of Cross-Validation
Cross-validation offers several key advantages, making it an essential technique for building robust Machine Learning models. Ensuring a more reliable evaluation process helps Data Scientists and Machine Learning engineers assess model performance more accurately, preventing issues like overfitting or underfitting.
More Reliable Estimate of Model Performance
One of the main benefits of cross-validation is that it provides a more reliable estimate of a model’s performance. Instead of relying on a single training and test set, cross-validation involves multiple rounds of training and testing.
This leads to a more generalised performance metric, reducing the likelihood of evaluating a model based on a biased or unrepresentative dataset.
Helps in Detecting Overfitting and Underfitting
Cross-validation is crucial for identifying both overfitting and underfitting in models. Overfitting occurs when a model is too complex and fits the noise in the training data, leading to poor generalisation of unseen data.
Conversely, underfitting happens when a model is too simple to capture the underlying patterns. By testing the model on different subsets of data, cross-validation allows you to monitor performance across various configurations and detect these issues early, ensuring a well-balanced model.
Utilises the Entire Dataset for Both Training and Testing
Cross-validation efficiently uses the entire dataset for both training and testing purposes. In traditional train-test splits, some data is left out of the training process.
Conversely, cross-validation allows each data point to contribute to the training and testing phases. This maximises the data utilisation, especially in scenarios with limited datasets, making the most of every available sample.
Increased Robustness of the Model
Finally, cross-validation increases the model’s robustness by reducing the variance in performance metrics. Since the model tested across different data folds, it gains resilience to fluctuations in data, improving its ability to generalise well on unseen data. This leads to a more stable and reliable model in real-world applications.
Challenges of Cross-Validation
Cross-validation is a powerful technique for evaluating Machine Learning models, but it comes with specific challenges. Understanding these challenges can help you make informed decisions about when and how to apply cross-validation effectively.
Computational Cost (Especially for Large Datasets)
One of the significant drawbacks of cross-validation is its high computational cost. Since the process involves splitting the dataset into multiple folds and training the model numerous times, it can be particularly resource-intensive for large datasets.
For instance, with K-Fold cross-validation, if your dataset has 1 million samples and you choose K=10, the model must be trained 10 times. This can lead to significant delays in model evaluation, especially when dealing with complex models that require long training times.
In practice, this means more CPU/GPU power and longer wait times, which can be challenging in time-sensitive environments.
Time Complexity (More Training Cycles Required)
Cross-validation increases the time complexity of model evaluation. The model is trained only once in traditional single-train/test splits, but cross-validation requires multiple training cycles.
For example, K-Fold cross-validation with 10 folds will necessitate training the model 10 times. If each training cycle is computationally expensive, the time needed for cross-validation can be prohibitively long.
This is particularly evident in deep learning tasks, where training models take hours or even days. This time burden can limit the speed with which models iterated and optimised.
Handling Imbalanced or Small Datasets
Another challenge arises when applying cross-validation to imbalanced or small datasets. Certain classes may be underrepresented in imbalanced datasets, leading to biased model evaluation.
For example, cross-validation might overfit the model to the majority class in a binary classification problem where 90% of the data belongs to one class. This can result in misleading performance metrics.
The problem is even more pronounced in small datasets—splitting the data into multiple folds may result in too small folds to train a reliable model. In such cases, stratified K-Fold or bootstrapping can help mitigate these issues and provide a more accurate model evaluation.
Real-World Applications of Cross-Validation
Cross-validation is widely used in Machine Learning tasks to ensure that models perform reliably on unseen data. Using cross-validation techniques, Data Scientists can select the best models and fine-tune them for optimal performance. Below are some key applications of cross-validation in real-world scenarios.
Classification Tasks
In classification tasks, such as predicting whether an email is spam or classifying images, cross-validation helps assess the model’s ability to generalise across different subsets of data.
For example, in a medical diagnosis scenario, cross-validation can validate a model’s accuracy in predicting whether a patient has a particular condition, ensuring the model works consistently across multiple datasets.
Regression Tasks
Cross-validation also plays a crucial role in regression problems, where the goal is to predict continuous values. For instance, in predicting house prices, cross-validation ensures that the model can generalise to various market conditions. It helps in evaluating the model’s performance in forecasting prices based on features like location, size, and amenities.
Impact on Model Selection and Evaluation
Cross-validation provides a more reliable estimate of a model’s performance by evaluating it on multiple test sets. This enables better model selection, ensures the chosen algorithm performs well across different data splits and helps identify any overfitting or underfitting issues.
Cross Validation in Practice
Cross-validation is an essential technique for evaluating the performance of Machine Learning models, ensuring that they generalise well to new, unseen data. Implementing cross-validation in popular Machine Learning libraries like Scikit-learn and TensorFlow is straightforward and can significantly improve model reliability. Below, we’ll explore how to apply cross-validation in these libraries with practical code examples.
Implementing Cross-Validation with Scikit-learn
Scikit-learn, a widely used Python library for Machine Learning, offers built-in support for cross-validation. The cross_val_score() function simplifies the process by automating data splitting into folds and evaluating the model’s performance.
Example Code for K-Fold Cross Validation
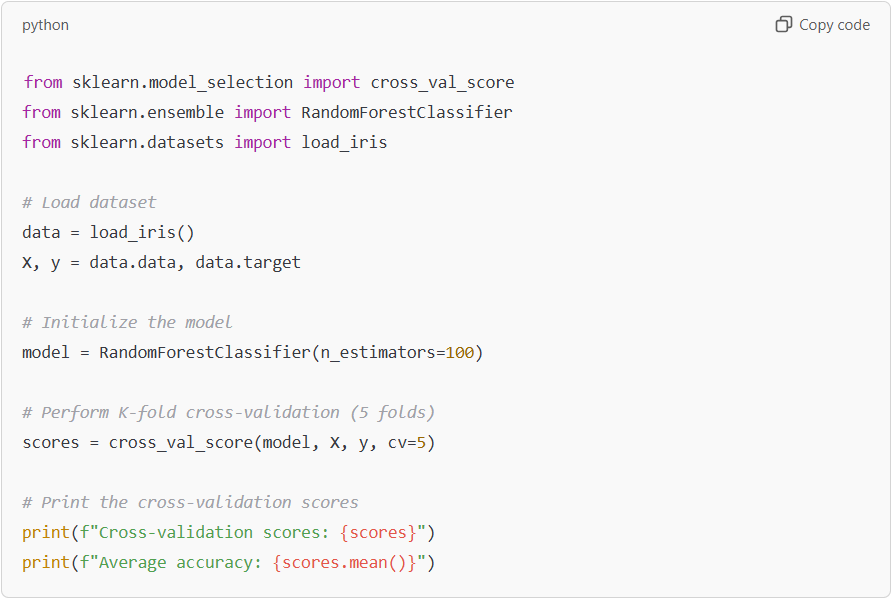
In this example, we use the Iris dataset and apply 5-fold cross-validation. The function cross_val_score() returns an array of accuracy scores, and the mean score indicates the overall model performance across different subsets of the data.
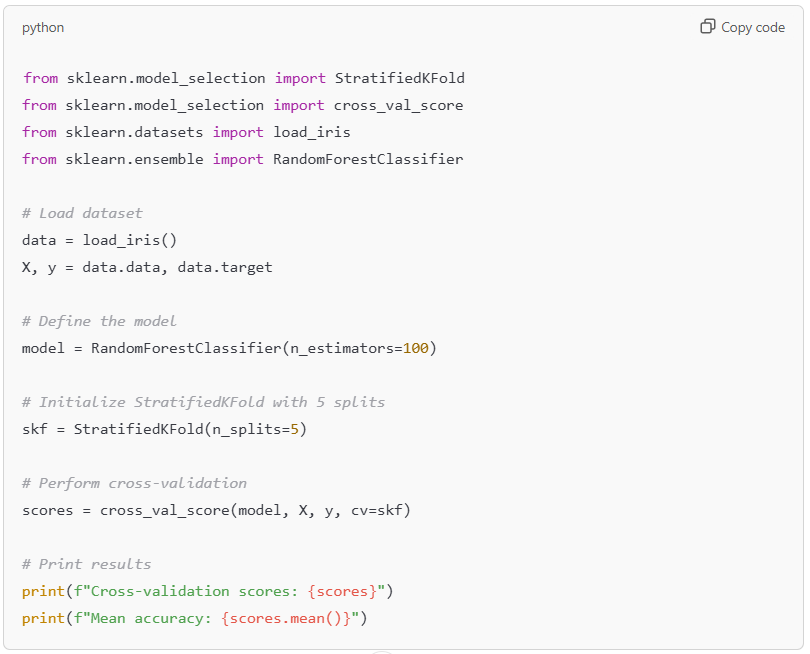
Stratified K-Fold Cross Validation
Stratified K-folds preferred for classification tasks, especially with imbalanced datasets as they ensure that each fold has a similar distribution of class labels.
Example Code for Stratified K-Fold Cross Validation
Cross-Validation in TensorFlow
In TensorFlow, cross-validation is not as directly integrated as in Scikit-learn. However, you can manually implement it by dividing the dataset into training and validation sets, training the model multiple times, and evaluating it across different folds.
Example Code for Cross-Validation in TensorFlow

These examples show how easy it is to implement cross-validation using Scikit-learn and TensorFlow. In Scikit-learn, the process is more automated, while in TensorFlow, you have more flexibility but need to handle the folds manually. Either way, cross-validation is a powerful tool for building robust and reliable Machine Learning models.
In The End
Cross-validation in Machine Learning is an essential technique that enhances model evaluation by partitioning datasets into training and testing subsets. This method helps mitigate overfitting, ensuring models generalise well to unseen data.
By employing various cross-validation techniques, such as K-Fold and Stratified K-Fold, practitioners can achieve reliable performance estimates, ultimately leading to more robust Machine Learning solutions.
Frequently Asked Questions
What is Cross-Validation in Machine Learning?
Cross-validation assesses a model’s performance by splitting the dataset into subsets for training and testing. This approach ensures that each data point utilised for both purposes, providing a more accurate estimate of the model’s generalisation ability.
Why is Cross-Validation Important?
Cross-validation reduces the risk of overfitting by allowing models to evaluated on multiple training-test splits. This comprehensive evaluation helps ensure that models perform reliably on new, unseen data, increasing their robustness in real-world applications.
What are the Different Types of Cross-Validation?
Common types of cross-validation include K-Fold, Leave-One-Out, Stratified K-Fold, Group K-Fold, and Time Series Cross Validation. Each method is suited for different datasets and problems, ensuring optimal model evaluation based on specific use cases.
Authors
-

Written by:
Karan ThaparReviewed by:



