
Summary: Boosting in Machine Learning improves predictive accuracy by sequentially training weak models. Algorithms like AdaBoost, XGBoost, and LightGBM power real-world finance, healthcare, and NLP applications. Despite computational costs, Boosting remains vital for handling complex data and optimising AI models for high-performance decision-making.
Introduction
Boosting in Machine Learning is a powerful ensemble technique. It works iteratively, focusing on misclassified instances and reducing errors with each step.
This blog explores how Boosting works and its popular algorithms. You will also learn about its advantages and real-world applications. By the end, you will understand why Boosting is essential for optimising Machine Learning models and how to implement it effectively.
Whether you’re a beginner or an expert, this guide will help you leverage Boosting for better predictive results.
Key Takeaways
- Boosting improves prediction accuracy by sequentially training weak models to correct previous errors.
- Popular Boosting algorithms include AdaBoost, Gradient Boosting, XGBoost, LightGBM, and CatBoost.
- Boosting is widely used in finance, healthcare, NLP, and fraud detection applications.
- While Boosting enhances performance, it requires careful tuning to avoid overfitting.
- Implementing Boosting in Python is easy with Scikit-learn and XGBoost, ensuring efficient model optimisation.
What is Boosting?
Boosting is a Machine Learning technique that helps improve the accuracy of predictions. It combines multiple simple weak learner models to create a strong model. Boosting takes these weak models and trains them in a sequence where each new model focuses on correcting the mistakes made by the previous ones.
Think of it like a group of students solving a complex problem together. If one student makes a mistake, the next student learns from that mistake and improves the answer. Over time, their combined effort leads to a much better solution.
How Boosting Works
Boosting is a smart way to improve Machine Learning models by combining many simple models, called weak learners, to create a strong and accurate model. Instead of training all models simultaneously, Boosting works step by step, learning from past mistakes to improve over time.
Iterative Process of Boosting
Boosting trains models one after another in multiple rounds. The process starts with a simple model that makes predictions. In the next round, another model focuses on correcting the mistakes made by the first model.
This cycle continues, with each new model learning from the errors of the previous ones. Over time, the combined models work together to make better and more accurate predictions.
Think of it like a student learning math. If they keep making mistakes on a specific topic, their teacher will pay extra attention to those mistakes. Slowly, with practice, they get better and stop repeating errors. Boosting works similarly—each model improves by focusing on past mistakes.
Role of Weak Learners and How They Improve
Weak learners are simple models that alone may not be very effective. However, when many weak learners are combined, they create a strong system. Boosting ensures that each new weak learner pays extra attention to the mistakes of the previous ones, leading to a decisive final model.
Popular Boosting Algorithms

Over time, several Boosting algorithms have been developed to make predictions more accurate. Let’s explore some of the most popular ones.
AdaBoost (Adaptive Boosting)
AdaBoost was one of the first Boosting algorithms and is simple yet effective. It works by training multiple weak models (often decision trees with one split, known as stumps). Each model focuses on the mistakes made by the previous one, giving more weight to difficult-to-classify points.
As a result, the final prediction is a strong combination of all models. AdaBoost is widely used in face recognition and fraud detection.
Gradient Boosting (GBM)
Gradient Boosting builds models step by step, just like AdaBoost. However, instead of giving more weight to misclassified points, it corrects mistakes by learning from the difference between actual and predicted values. This method reduces errors more effectively and is commonly used in risk prediction and ranking systems like search engines.
XGBoost (Extreme Gradient Boosting)
XGBoost is a more advanced version of Gradient Boosting. It is faster and more efficient because it uses clever techniques like parallel processing and memory optimisation. Due to its high accuracy, XGBoost is widely used in data science competitions and practical applications like customer churn prediction and sales forecasting.
LightGBM (Light Gradient Boosting Machine)
LightGBM is designed for speed and performance. It processes large datasets quickly by using a unique method called leaf-wise growth, which selects the best branches of a decision tree instead of growing evenly. LightGBM is perfect for applications where fast results are needed, such as real-time recommendation systems.
CatBoost (Categorical Boosting)
CatBoost handles categorical data, like names, colours, or product types, without requiring extra processing. It is known for being simple to use while delivering high accuracy. It is commonly used in e-commerce, finance, and medicine to make better predictions.
Advantages and Limitations of Boosting
Without a doubt, Boosting is a powerful Machine Learning technique. However, like any method, Boosting has both advantages and limitations. Understanding these can help decide when to use it.
Key Benefits of Boosting Models
- Higher Accuracy: Boosting improves prediction accuracy by learning from past mistakes and correcting them. It continuously adjusts the model to reduce errors.
- Works Well with Weak Models: Even simple models that don’t perform well alone can become strong when combined through Boosting.
- Handles Complex Data: Boosting works well with large and complicated datasets, making it useful for real-world problems like fraud detection and medical diagnosis.
- Reduces Overfitting (Sometimes): Some Boosting techniques, like XGBoost, include features that help prevent overfitting, meaning the model won’t just memorise the data but will make valuable predictions.
Challenges and Potential Drawbacks
- Computationally Expensive: Boosting requires a lot of computing power and time, especially for large datasets.
- Sensitive to Noisy Data: If the data has many errors or random variations, Boosting may focus too much on them and reduce overall performance.
- Risk of Overfitting: While Boosting can reduce overfitting, it can make the model too complex and less generalisable if not appropriately handled.
- Difficult to Interpret: Boosting models are not as easy to understand as simpler models, making it harder to explain decisions in business or healthcare applications.
Use Cases of Boosting in Machine Learning
Boosting helps computers make better decisions by learning from past mistakes. It is widely used in different fields to improve predictions and accuracy. Here are some real-world applications where Boosting plays a key role:
- Finance: Banks use Boosting to detect fraud by spotting unusual transactions. It also helps in predicting loan defaults by analysing customer history.
- Healthcare: Doctors use Boosting to predict diseases early by studying patient data. It also helps in diagnosing conditions like cancer more accurately.
- Natural Language Processing (NLP): Chatbots and virtual assistants use Boosting to understand human language better and provide smarter responses.
Comparison of Boosting with Other Ensemble Techniques
Machine Learning uses different methods to improve model accuracy. Ensemble techniques combine multiple models to make better predictions. Boosting, Bagging, and Stacking are three popular methods. Each works differently, and understanding their differences helps choose the right approach.
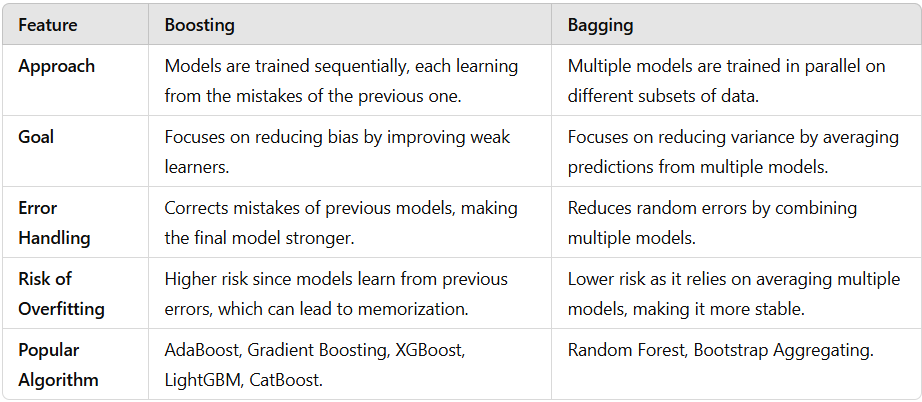
Boosting vs. Bagging
Boosting and Bagging combine multiple models, but they do it differently.
- Boosting focuses on correcting mistakes. It trains models one after another. Each new model learns from the errors of the previous one. This makes Boosting strong in handling complex problems but also increases the risk of overfitting (memorising data instead of learning patterns).
- Bagging focuses on reducing errors through randomness. It trains multiple models at the same time (parallelly) on different sets of data. Then, it averages their results to make a final decision. This reduces mistakes and makes the model more stable. Random Forest is a popular Bagging method.
In simple terms, Boosting is like a teacher correcting a student’s mistakes after each test, while Bagging is like a group of students solving the same problem and choosing the most common answer.
Here is the table showing the difference between Boosting and Bagging for your better understanding:
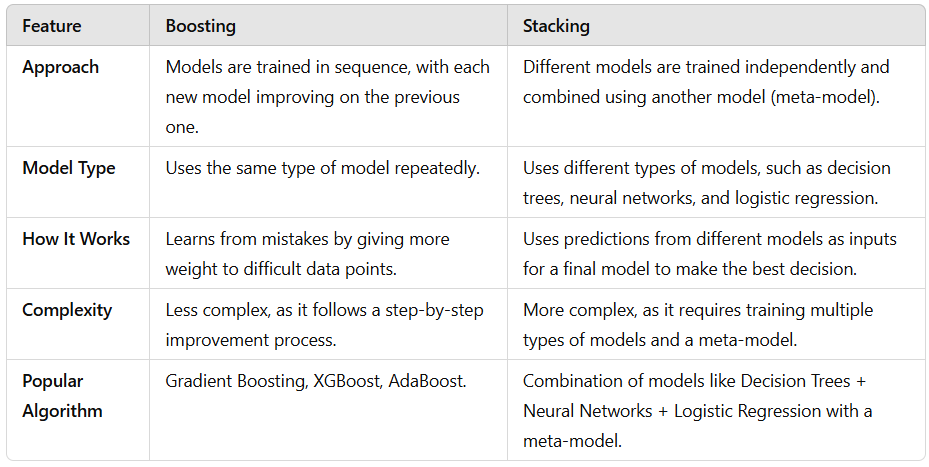
Boosting vs. Stacking
Boosting and Stacking also take different approaches to improving predictions.
- Boosting builds models step by step, learning from past mistakes. Each new model improves the last one, making the final prediction stronger.
- Stacking combines different types of models. Instead of using the same model multiple times, Stacking mixes different ones, such as decision trees, neural networks, and logistic regression. Then, another model (called a meta-model) learns from their outputs to make the best final prediction.
Think of Boosting as a student improving by learning from previous tests, while Stacking is like getting advice from different experts to make the best decision.
Here is the table showing the difference between Boosting and Stacking for your better understanding:
Implementing Boosting in Python
Python makes it easy to implement Boosting using popular libraries like Scikit-learn and XGBoost. This section will walk through simple code examples and explain key parameters to help you get started.
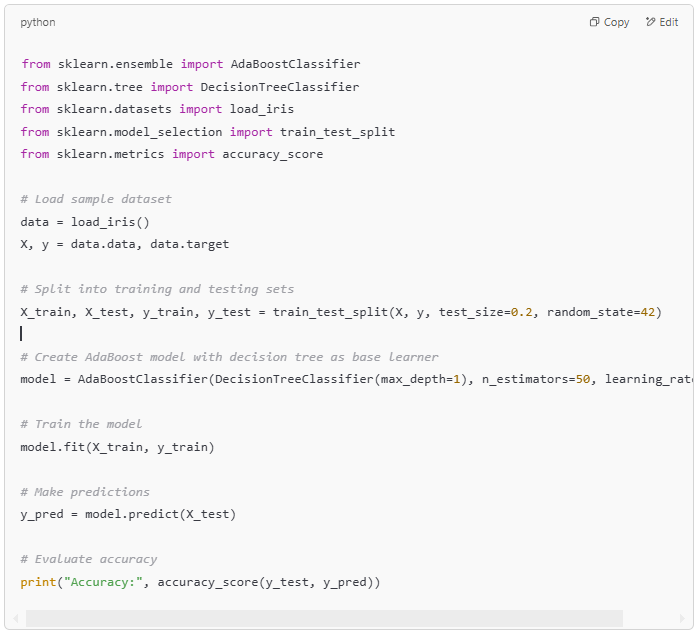
Using AdaBoost with Scikit-Learn
Scikit-learn provides an easy way to use AdaBoost. Here’s how you can implement it:
Key Parameters in AdaBoost
- n_estimators: Number of weak models to combine. A higher value improves accuracy but increases computation time.
- learning_rate: Controls the contribution of each weak model. Lower values slow down learning but can improve performance.
- base_estimator: The weak learner model (e.g., DecisionTreeClassifier).
Using XGBoost for Better Performance
XGBoost is widely used for its efficiency and accuracy. Here’s how you can use it in Python:
Key Parameters in XGBoost
- n_estimators: Number of Boosting rounds. More rounds improve accuracy but increase training time.
- max_depth: Controls tree depth. Deeper trees can capture complex patterns but may overfit.
- learning_rate: Determines how much each tree contributes to the model. A lower rate requires more rounds.
Tuning Strategies for Boosting Models
Fine-tuning Boosting models is essential for achieving high accuracy and preventing overfitting. Here are some effective strategies:
- Grid Search & Random Search: Instead of manually selecting the best parameters, use GridSearchCV from Scikit-learn to test different combinations systematically. Random search quickly explores a wide range of values, making it useful when dealing with large datasets.
- Early Stopping: Boosting models can train for too many iterations, leading to overfitting. Early stopping halts training when performance stops improving on a validation set, ensuring a well-generalised model.
- Feature Selection: Not all features contribute to the model’s accuracy. Removing irrelevant or redundant features can improve speed and prevent overfitting while maintaining high performance.
- Cross-Validation: Splitting data into multiple subsets allows the model to be trained and tested on different portions, ensuring robustness and reliability.
By applying these strategies, you can optimise Boosting models for various machine-learning applications.
Closing Words
Boosting in Machine Learning is a powerful technique that enhances prediction accuracy by combining weak models with a strong learner. It iteratively corrects errors, improving overall performance.
Popular algorithms like AdaBoost, Gradient Boosting, XGBoost, LightGBM, and CatBoost make boosting widely applicable across industries, from finance to healthcare. While boosting offers high accuracy and handles complex data well, it requires careful tuning to avoid overfitting and computational costs.
Those interested can learn Machine Learning by enrolling in free data science courses from Pickl.AI. By mastering boosting, you can optimise models for real-world applications, making it an essential tool for AI practitioners.
Frequently Asked Questions
What is Boosting in Machine Learning?
Boosting is an ensemble learning technique that improves prediction accuracy by combining multiple weak models. It sequentially trains models, where each new model corrects the errors of the previous ones. This iterative learning process enhances performance, making Boosting a powerful tool in Machine Learning applications.
How Does Boosting Differ from Bagging?
Boosting improves model accuracy by sequentially training weak models, where each focuses on previous mistakes. In contrast, Bagging trains multiple models in parallel on different data subsets and averages their outputs. Boosting works well for complex problems, while Bagging reduces variance and prevents overfitting in Machine Learning.
What are the Advantages of Using Boosting in Machine Learning?
Boosting enhances model accuracy, handles complex data efficiently, and improves weak learners. It is widely used in fraud detection, healthcare, and NLP. However, it can be computationally expensive and prone to overfitting if not tuned properly. Despite these challenges, Boosting remains a crucial technique in modern Machine Learning.
Authors
-

Written by:
Neha SinghReviewed by:



