
Summary: Eager Learning and Lazy Learning are two fundamental approaches in machine learning. Eager Learning focuses on pre-training models for quick predictions, while Lazy Learning defers generalization until prediction time, allowing flexibility and adaptability. Understanding these methods is crucial for effective model selection.
Introduction
Machine Learning has revolutionised various industries, from healthcare to finance, with its ability to uncover valuable insights from data. Among the different learning paradigms in Machine Learning, “Eager Learning” and “Lazy Learning” are prominent approaches.
In this article, we will delve into the differences and characteristics of these two methods, shedding light on their unique advantages and use cases.
Understanding Eager Learning
Eager Learning, or “Eager Supervised Learning,” is a widely used approach in Machine Learning. In this paradigm, the model is trained on a labeled dataset before making predictions on new, unseen data.
The key characteristic of Eager Learning is that the model eagerly generalises from the training data, representing the underlying patterns and relationships. This representation allows the model to classify or regress new instances efficiently.
Key Features of Eager Learning
Eager Learning is a machine learning approach that emphasises pre-training a model to optimise performance. This method involves training the model on a labeled dataset to create a robust and generalised data representation. Here are the key features of Eager Learning:
Training before Prediction: The model undergoes a comprehensive training phase on a labeled dataset. During this time, it learns and captures the underlying patterns and relationships within the data. This pre-training phase is crucial for building an effective model.
Fast Predictions: The model can quickly generate predictions for new data instances after training. The prediction process is efficient and rapid since it has already learned the data patterns.
Offline Predictions: Eager Learning models do not need access to the entire training dataset during prediction. This characteristic makes them ideal for situations where predictions must be made offline or in scenarios where training data is inaccessible at the time of prediction.
Optimised Performance: These models typically perform well on well-labeled datasets. The optimisation during the training phase enables the model to deliver accurate and reliable predictions.
Overall, Eager Learning offers efficiency and high performance by focusing on extensive training before making predictions.
Examples of Eager Learning Algorithms
Eager Learning algorithms are designed to build robust models through extensive training before making predictions. These algorithms learn from labeled datasets and efficiently apply this knowledge to new data. Here are some prominent examples of Eager Learning algorithms:
Logistic Regression: This classic algorithm is used for binary classification tasks. It learns the relationship between features and class labels during training, allowing it to predict the probability of an instance belonging to a specific class. Logistic Regression is known for its simplicity and effectiveness in various classification scenarios.
Support Vector Machines (SVM): SVM is a versatile algorithm for classification and regression tasks. It constructs a hyperplane to separate different classes during training and uses this hyperplane to predict new data, making SVM a powerful tool for tasks requiring clear class boundaries.
Decision Trees: Decision Trees work by recursively splitting the data based on feature values to form a tree-like structure. Each tree branch represents a decision rule, and the leaves indicate the final prediction. This method is intuitive and interpretable, providing a clear path from features to forecasts.
Random Forest: An ensemble learning method, Random Forest combines multiple Decision Trees to enhance prediction accuracy and minimise overfitting. Aggregating the outputs of several trees produces more reliable and robust predictions than a single decision tree.
Eager Learning algorithms excel when dealing with well-structured and well-labeled datasets. Their ability to generalise from training data allows them to quickly and accurately classify or regress new instances, making them valuable tools in various real-world applications.
Advantages of Eager Learning
Eager Learning offers several advantages, making it a preferred choice for various machine learning tasks. By pre-training models before making predictions, Eager Learning provides several benefits that enhance its efficiency and effectiveness. Here are the key advantages:
Speedy Predictions: Eager Learning models are pre-trained, allowing them to rapidly apply their learned knowledge to new data. This efficiency is particularly valuable in real-time applications where quick response times are crucial.
Offline Predictions: These models do not require access to the entire training dataset during prediction. This capability enables predictions to be made offline or in environments with limited connectivity, offering flexibility in different scenarios.
Optimised Performance: The pre-training phase allows for extensive model optimisation, enhancing performance. This makes Eager Learning well-suited for datasets with clear patterns and relationships.
Ease of Deployment: Eager Learning models are easier to deploy since they do not depend on the training data during prediction. This simplicity facilitates their integration into various applications and systems.
Interpretability: The training process provides insight into how the model makes decisions. This increased transparency can help users understand and trust the model’s predictions.
Well-Suited for Small Datasets: Eager Learning can effectively use small datasets with well-defined patterns, which is advantageous when working with limited data.
Transfer Learning: The knowledge acquired during training can be transferred to related tasks. This enables quicker adaptation and training for new, similar tasks.
Avoids Instance-Based Overhead: Unlike Lazy Learning, which involves searching for similar instances during prediction, Eager Learning bypasses this overhead, resulting in faster processing.
These advantages make Eager Learning a powerful and versatile approach in various machine learning applications.
How does Eager Learning Algorithms Work?

Eager Learning algorithms work on the principle of creating a generalised model during the training phase, which is then used for making predictions on new, unseen data. Unlike Lazy Learning algorithms that memorise the entire training dataset, Eager Learning algorithms learn from the data before making any predictions.
Here’s how Eager Learning algorithms typically work:
Data Training
Eager Learning algorithms are provided with a labeled dataset during the training phase. The algorithm examines the data, which consists of features and corresponding labels. By analysing these data points, the algorithm identifies patterns, relationships, and rules that govern the data.
This process involves understanding how different features interact and contribute to the outcomes, allowing the algorithm to learn the underlying structure of the dataset.
Model Creation
As the algorithm processes the training data, it constructs a generalised model that encapsulates the relationships between features and labels. The nature of this model depends on the specific Eager Learning algorithm used.
For instance, decision trees create a hierarchical structure of decisions, while neural networks develop complex, multi-layered representations. This model aims to capture the essential characteristics of the data, enabling it to make accurate predictions on new instances.
Parameter Optimisation
Eager Learning algorithms typically involve parameters that can be fine-tuned to improve the model’s performance. During training, the algorithm searches for the optimal combination of these parameters to enhance the model’s accuracy and generalisation ability.
Cross-validation and grid search are often employed to identify the best parameter settings. Optimising parameters ensures the model performs well on the training and unseen data.
Prediction Phase
Once the model is trained and parameters are optimised, it enters the prediction phase. The algorithm uses the learned model to predict new, unseen data outcomes in this stage.
Classification tasks involve assigning class labels based on the patterns identified during training. For regression tasks, the algorithm generates numerical values. The efficiency and accuracy of this phase depend on the training quality and the model’s effectiveness.
Also See: Classification vs. Clustering: Unfolding the Differences.
Model Evaluation
After making predictions, the model’s performance is evaluated using various metrics. These metrics vary depending on the type of problem. Accuracy, precision, recall, and F1 score might be used for classification tasks, while regression tasks often rely on metrics like mean squared error or R-squared.
This evaluation process helps assess the model’s performance and identifies areas for improvement.
Deployment
Finally, once the model is trained, optimised, and evaluated, it can be deployed for real-world applications. This means integrating the model into a production environment where it can make predictions on new data in practical scenarios. Deployment allows organisations to leverage the model’s insights and predictions to drive decision-making and automate processes.
Key Points about Eager Learning Algorithms
Eager Learning algorithms are a key approach in machine learning, characterised by their pre-training phase and rapid prediction capabilities. These algorithms build a generalised model during training, which enables them to make swift predictions on new data. Here are some key points about Eager Learning algorithms:
Training Phase: Eager Learning algorithms require a distinct and often computationally intensive training phase. This phase involves processing large datasets to build a comprehensive model, which can be resource-intensive depending on the size and complexity of the data.
Rapid Predictions: Once trained, Eager Learning algorithms excel at quickly making predictions on new data. The pre-built generalised model allows these algorithms to deliver fast and efficient predictions, leveraging the knowledge gained during training.
Popular Examples: Some well-known Eager Learning algorithms include Logistic Regression, Decision Trees, Random Forests, Support Vector Machines (SVM), and Neural Networks. Each offers unique advantages and is suited to different problems and datasets.
Suitability for Structured Data: Eager Learning algorithms perform best with well-structured datasets with clear patterns and relationships between features and labels. The effectiveness of these algorithms hinges on the clarity and organisation of the data.
Dependence on Data Quality: Eager Learning algorithms’ success relies on the training data’s quality and representativeness. Additionally, selecting the appropriate algorithm and fine-tuning its parameters is crucial for achieving optimal performance.
In summary, Eager Learning offers a valuable approach for machine learning tasks involving well-structured data, where quick and efficient predictions are crucial.
Understanding Lazy Learning
It is also known as Lazy Supervised Learning or Instance-Based Learning, a Machine Learning approach in which the model postpones generalisation until the prediction time.
Unlike Eager Learning, which eagerly generalises from the training data, Lazy Learning memorizes the entire training dataset and uses it as a knowledge source for predicting new, unseen instances.
In lazy learning, the model does not create a generalised data representation during training. Instead, it stores the training data points in memory and uses them directly when a new instance needs to be classified.
The model looks for similar cases in the training data and applies their labels to the new instance, making predictions based on the most similar examples.
Key Features of Lazy Learning
Lazy learning models offer distinct advantages in various data analysis scenarios due to their unique approach to handling data. Unlike traditional models, lazy learning does not require an extensive training phase. Instead, it relies on the memorisation of training instances, leading to several notable features:
No Pre-Training: Lazy learning models skip the conventional training phase. They store training data instances as they are without creating a generalised model. This approach means the model does not require a separate training process before making predictions.
Flexible Adaptation: These models are highly adaptable to changes in data. They can seamlessly incorporate new data instances without being completely retrained, allowing them to adjust quickly to new patterns or variations in the data.
Complex Relationship Handling: Lazy learning manages datasets with intricate and non-linear relationships. By directly applying the stored knowledge from the training data, these models can address complex patterns that might be challenging for other learning methods.
Interpretable Predictions: The decision-making process in lazy learning models is straightforward. It involves identifying and examining similar instances from the training data, which makes the predictions more transparent and easier to understand.
Examples of Lazy Learning Algorithms
Lazy Learning algorithms are powerful tools that leverage past data to make predictions without extensive training. These algorithms are particularly useful for tasks where model training needs to be flexible and adapt quickly to new data. Here are some prominent examples:
K-Nearest Neighbors (k-NN):
Description: K-NN is a widely used lazy learning algorithm for classification and regression problems. It identifies the ‘k’ closest training instances to a new data point and makes predictions based on these neighbors.
Classification: For classification tasks, k-NN predicts the class of a new instance by determining the majority class among the k nearest neighbors.
Regression: For regression tasks, it predicts the value of a new instance by averaging the values of the k closest neighbors.
Case-Based Reasoning (CBR):
Description: CBR solves new problems by referencing and reusing solutions from previously encountered, similar issues. It stores past problem-solving experiences in memory and applies them to new situations.
Function: When faced with a new problem, CBR retrieves the most relevant cases from its database, adapts the solutions if necessary, and applies them to the current situation.
Locally Weighted Learning (LWL):
Description: LWL assigns weights to training instances based on their proximity to the predicted new instance. This method emphasises nearby data points more heavily than those further away.
Prediction: During prediction, LWL calculates a weighted average of the target values from nearby instances, where weights decrease with distance, allowing the model to focus on the most relevant data.
These Lazy Learning algorithms offer flexibility and adaptability, making them suitable for various real-world problems and dynamic data environments.
Advantages of Lazy Learning
Lazy Learning models offer several advantages that make them valuable in various Machine Learning scenarios. Their unique approach enables them to handle dynamic data and complex relationships efficiently, making them a versatile choice for classification and regression tasks. Here’s a closer look at the key benefits of Lazy Learning:
Adaptability to New Data: Lazy Learning models quickly adapt to changes in data without needing retraining. This is particularly advantageous in dynamic environments where data distributions evolve.
Flexibility in Feature Space: These models capture complex and non-linear relationships between features and labels, handling intricate patterns that eager learning algorithms might struggle with.
Interpretable Predictions: Lazy learning models offer transparent predictions by relying on similar instances from the training data, making it easier for users to understand how decisions are made.
Simple Model Representation: Unlike fixed model representations, Lazy Learning models store training data directly, simplifying the learning process and reducing model complexity.
Efficiency with Large Datasets: These models are computationally efficient with large datasets without upfront training. They only perform memory searches during prediction, speeding up inference.
Incremental Learning: Lazy Learning supports incremental learning, allowing models to learn from new data while retaining previously acquired knowledge continually.
Suitable for Online Learning: In streaming data scenarios, Lazy Learning adapts to new instances as they arrive, making it ideal for online learning applications.
Handling Noisy Data: These models are robust to noisy data by focusing on similar instances, which helps mitigate the effects of outliers.
Versatility in Problem Types: Lazy Learning is effective for classification and regression tasks, offering various applications.
Imbalanced Datasets: They handle imbalanced datasets well, evaluating instances individually rather than relying on a biased fixed representation.
How Does Lazy Learning Algorithms Work?
Lazy Learning algorithms take a distinct approach to handling data compared to eager learning methods. Instead of creating a generalised model during the training phase, Lazy Learning algorithms store the training data and use it directly during the prediction phase.
This approach allows these algorithms to adapt quickly to new data and handle complex relationships effectively. Here’s a detailed look at how Lazy Learning algorithms function:
Data Memorisation
In the Data Memorisation step, Lazy Learning algorithms store the entire training dataset in memory. This means that every data point, along with its corresponding class label (for classification tasks) or value (for regression tasks), is preserved.
This storage does not involve any processing or model training at this stage. The primary goal is to keep the raw data intact for future reference.
Prediction Phase
When a new, unseen instance needs to be classified or predicted, Lazy Learning algorithms do not immediately generalize from the training data. Instead, they defer the generalisation until the prediction phase. During this phase, the algorithm compares the new instance to the stored cases in the training dataset.
Instance Similarity
Lazy Learning algorithms use various similarity measures to determine how similar the new instance is to the stored instances. Common measures include Euclidean distance, which calculates the straight-line distance between points, and cosine similarity, which measures the angle between vectors.
By employing these measures, the algorithm identifies the ‘k’ nearest neighbors—where ‘k’ is a user-defined parameter—most similar to the new instance.
Voting or Weighted Averaging
In the Voting or Weighted Averaging step, the algorithm uses the identified nearest neighbors to make predictions. The algorithm examines the class labels of the k-nearest neighbors for classification tasks and applies a voting mechanism. The class that appears most frequently among the neighbors is chosen as the predicted class for the new instance.
The algorithm calculates the average or weighted average of the target values from the k-nearest neighbors for regression tasks. In weighted averaging, the algorithm assigns higher weights to closer neighbors and lower weights to those further away, ensuring that more similar instances have a greater influence on the prediction.
Prediction Output
Finally, in the Prediction Output step, the algorithm delivers the predicted class or value based on the aggregated information from the nearest neighbors. This output directly results from the similarity comparisons and the voting or averaging processes.
Lazy Learning algorithms are well-suited for scenarios where model flexibility and adaptability are crucial. These algorithms offer a straightforward yet powerful approach to solving classification and regression problems by focusing on instance-based learning and leveraging stored data for predictions.
Key Points about Lazy Learning Algorithms
Lazy Learning algorithms offer a distinctive approach to Machine Learning by focusing on the prediction phase rather than model training. This characteristic makes them particularly advantageous in specific contexts, though they come with certain trade-offs. Here’s a detailed look at the key points about Lazy Learning algorithms:
No Fixed Model: Lazy Learning algorithms do not construct a fixed model during the training phase. Instead, they store the training data and make predictions by comparing new instances with stored ones. This approach allows for quicker adaptation to new data and changes in data distribution.
Dependence on Similarity Measures: The effectiveness of Lazy Learning algorithms depends significantly on the choice of similarity measure and the value of kkk (the number of neighbors considered). Accurate similarity measures and optimal kkk values are crucial for making reliable predictions.
Handling Complex Relationships: Lazy Learning excels in scenarios where relationships between features and labels are complex, non-linear, or difficult to model explicitly. It can capture intricate patterns without needing a predefined model structure.
Popular Algorithms: Some well-known Lazy Learning algorithms include k-Nearest Neighbors (k-NN), Case-Based Reasoning (CBR), and Locally Weighted Learning (LWL). These methods leverage stored instances to make predictions.
Computational Trade-Off: While Lazy Learning models offer flexibility and interpretability, they can be computationally intensive during the prediction phase, particularly with large datasets. This is because each prediction involves searching and comparing instances, which can be slower than Eager Learning algorithms.
Adaptability to Changing Data: Lazy Learning is beneficial in dynamic environments where the data distribution evolves or complex relationships are present. By delaying generalisation until prediction time, these models provide adaptable solutions for various Machine Learning tasks.
Tabular Representation of the Difference Between Lazy Learning and Easy Learning
Examining a tabular representation of the difference between lazy and eager learning provides a clear, concise comparison of these machine learning approaches. It helps quickly understand their distinctions, advantages, and disadvantages, making it easier to choose the appropriate method based on specific use cases and requirements.
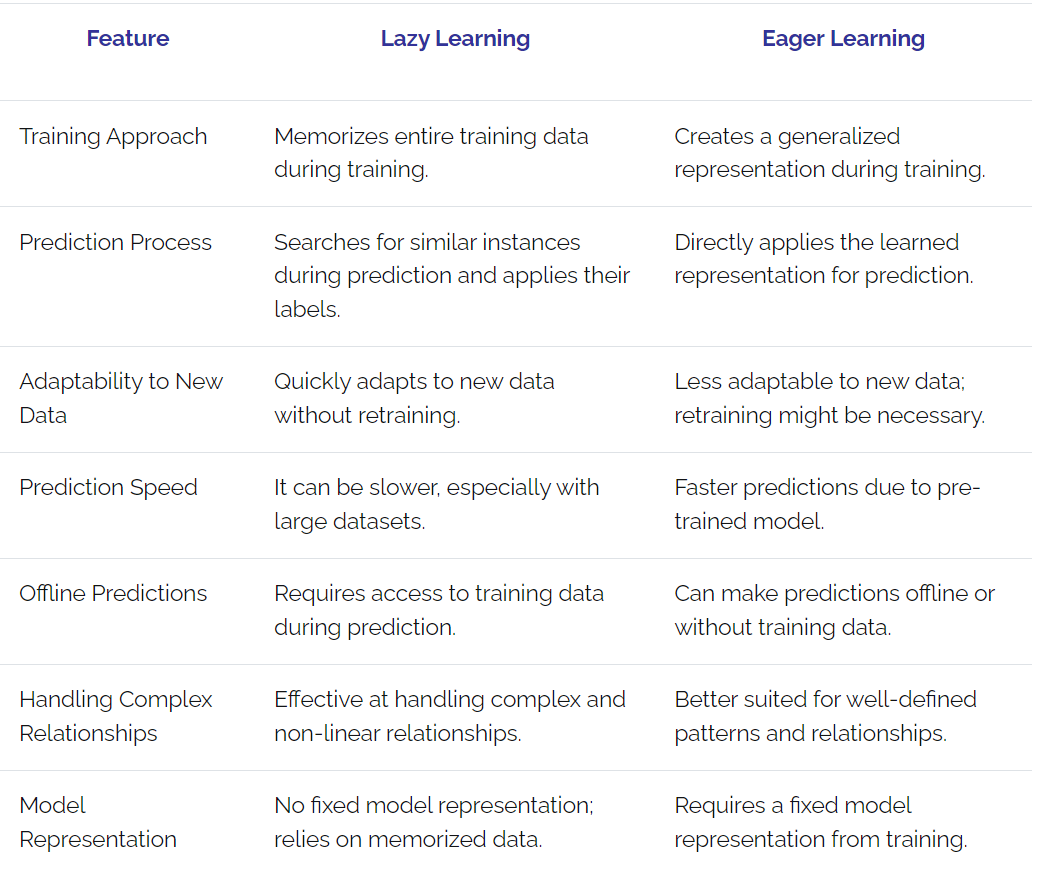

Lazy vs. Eager Learning: The Difference Which One is Better for You?
Lazy and Eager Learning are two distinct paradigms in Machine Learning, each with its advantages and limitations. With its adaptability to new data, ability to handle complex relationships and transparent decision-making process, Lazy Learning excels in dynamic environments and scenarios where data distributions are non-stationary.
On the other hand, Eager Learning offers optimised performance, fast predictions, and ease of deployment, making it a strong contender for well-structured datasets with clear patterns and relationships. The choice between Lazy and Eager Learning depends on the specific characteristics of the problem.
Lazy Learning might be the preferred choice for tasks involving real-time data, online learning, or where interpretability is crucial. Conversely, Eager Learning could be more suitable for applications demanding efficient predictions on static, well-labeled datasets.
Ultimately, understanding the strengths and weaknesses of both approaches empowers practitioners to make informed decisions and select the learning paradigm that best aligns with the unique requirements of their Machine Learning tasks.
Frequently Asked Questions
What is Eager Learning in Machine Learning?
Eager Learning, or Eager Supervised Learning, involves training a model on a labeled dataset before making predictions. This approach allows the model to generalise from the training data, enabling efficient classification and regression of new instances based on learned patterns.
What are the advantages of Lazy Learning?
Lazy Learning, or Instance-Based Learning, excels in adaptability and flexibility. It stores training data without creating a generalised model, allowing quick adjustments to new data. This method is particularly effective for complex relationships and scenarios where data distributions change frequently.
How does Eager and Lazy Learning differ?
Eager Learning pre-trains models on labeled data for fast predictions, while Lazy Learning defers generalisation until forecasts are needed. Eager Learning is best for well-structured datasets, whereas Lazy Learning adapts better to dynamic environments with complex relationships.
Conclusion
In machine learning, Eager and Lazy Learning represent two distinct paradigms with unique strengths and applications. Eager Learning emphasises pre-training on labeled datasets, resulting in rapid and efficient predictions for structured data. In contrast, Lazy Learning excels in adaptability, utilising stored instances to handle complex relationships and changing data distributions.
Understanding these methodologies allows practitioners to select the most suitable approach based on their specific needs, prioritising speed, efficiency, flexibility, and interpretability. Ultimately, the choice between these learning strategies can significantly impact the performance and effectiveness of machine learning models in real-world applications.
Authors
-

Written by:
Neha SinghReviewed by:



