
Summary: Entropy in Machine Learning quantifies uncertainty, driving better decision-making in algorithms. It optimises decision trees, probabilistic models, clustering, and reinforcement learning. Entropy aids in splitting data, refining predictions, and balancing exploration-exploitation. Its applications span AI and beyond, addressing challenges like uncertainty, overfitting, and feature selection for robust, data-driven solutions.
Introduction
Entropy, in a general context, measures uncertainty or disorder within a system. Rooted in thermodynamics, it later found prominence in information theory, where Claude Shannon used it to quantify unpredictability in data. This concept, pivotal in understanding data structures and communication systems, plays a significant role in Machine Learning.
By quantifying uncertainty, entropy in Machine Learning helps optimise decision-making processes, from building decision trees to fine-tuning probabilistic models. This blog aims to explore entropy’s theoretical foundations, practical applications, and impact on Machine Learning algorithms, guiding readers through its versatile applications in solving complex problems effectively.
Key Takeaways
- Entropy measures randomness, guiding algorithms to make better decisions.
- It calculates information gain, enabling effective splits for classification and regression.
- Entropy assesses uncertainty in predictions, aiding Bayesian inference and regularisation.
- Entropy enhances clustering, federated learning, finance, and bioinformatics.
- It evaluates prediction accuracy, driving efficient model training and optimisation.
Entropy in Information Theory
Entropy, a foundational concept in information theory, quantifies the uncertainty or unpredictability in a system or dataset. Introduced by Claude Shannon in 1948, entropy revolutionised how we measure information and remains central to modern Data Science, including Machine Learning. Let’s delve into its mathematical definition and key properties.
Mathematical Definition and Formula of Entropy
The mathematical formula for entropy H(X) is:
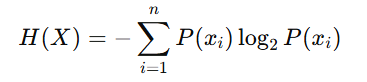
Here:
- P(xi) is the probability of the iii-th event.
- log2P(xi) measures the information content of each event in bits.
Entropy is highest when all events are equally likely, indicating maximum uncertainty.
Key Properties of Entropy
Entropy has several fundamental properties that make it versatile and impactful. These properties make entropy a powerful tool for understanding uncertainty across diverse fields.
- Entropy H(X) is always greater than or equal to zero, as probabilities are non-negative.
- Entropy is a concave function, ensuring that mixing distributions increases uncertainty.
- For a uniform distribution, entropy reaches its peak, symbolising complete unpredictability.
Role of Entropy in Machine Learning
Entropy plays a fundamental role in Machine Learning by quantifying uncertainty and guiding decision-making processes. It measures the randomness or unpredictability in data, enabling algorithms to understand and handle complex patterns.
This section explores how entropy contributes to supervised learning, evaluates uncertainty or impurity in datasets, and finds applications across various Machine Learning algorithms and tasks.
Importance of Entropy in Supervised Learning
In supervised learning, entropy is critical for making informed decisions during model training. For example, in decision tree algorithms, entropy helps identify the most effective splits in data. By calculating the information gain—a reduction in entropy after a split—algorithms prioritise features that reduce uncertainty, resulting in better classification or regression models.
Entropy also plays a role in evaluating the quality of predictions. Lower entropy indicates that the model is more confident about its predictions, while higher entropy suggests areas where the model might need improvement.
How Entropy Measures Uncertainty or Impurity in Data
Entropy quantifies the impurity in datasets by measuring the randomness in class distributions. In a classification problem, a dataset where all instances belong to one class has zero entropy, signifying no uncertainty. Conversely, entropy is at its maximum when instances are evenly distributed across classes, indicating high uncertainty.
This ability to measure uncertainty makes entropy essential in building robust models. It helps algorithms focus on highly unpredictable areas, ensuring the model learns meaningful patterns.
Applications Across Algorithms and Tasks
Beyond decision trees, entropy is widely used in clustering, feature selection, and reinforcement learning.
- Entropy evaluates cluster homogeneity in clustering, while mutual information—a derivative of entropy—identifies the most informative features in feature selection.
- In reinforcement learning, entropy encourages exploration, balancing discovering new strategies and exploiting known ones.
Entropy’s versatility ensures its relevance in traditional and modern Machine Learning applications.
Entropy in Decision Trees
Entropy plays a pivotal role in decision trees by quantifying the uncertainty or impurity of data at a given node. It helps determine the best splits during tree construction, making the model more precise with each division. By minimising entropy, decision trees ensure that the resulting nodes are as homogenous as possible, leading to better predictions.
Use of Entropy in Splitting Nodes
Decision trees use entropy to calculate Information Gain, a metric that evaluates the effectiveness of a split. Information Gain measures how much uncertainty is reduced when data is split along a specific feature. The formula for entropy at a node is:
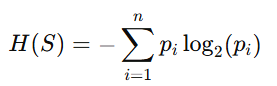
Where pi is the proportion of data points belonging to class i, information Gain is then defined as:
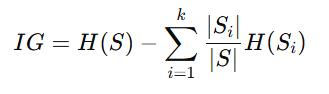
Here, H(S) is the entropy of the parent node, and H(Si) is the entropy of each child node. A higher Information Gain indicates a better split.
Comparison with Other Impurity Measures
While entropy is widely used, it is not the only impurity measure. Gini Impurity is another popular metric. Gini is calculated as:
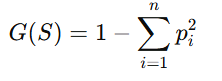
Entropy and Gini often produce similar splits, but Gini is computationally less intensive because it avoids logarithmic calculations. However, entropy provides a more granular understanding of uncertainty, making it preferred in cases where precision is critical.
Practical Example
Suppose a dataset has two classes, A and B, with probabilities 0.6 and 0.4 at a node. The entropy is:
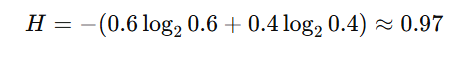
After splitting, the child nodes have entropies of 0.72 and 0.56, with respective weights. Information Gain is calculated by subtracting the weighted average of child entropies from the parent entropy. This guides the decision tree in selecting the optimal split.
Entropy thus drives decision trees to make data-driven, accurate splits for improved classification performance.
Entropy in Probabilistic Models

It plays a pivotal role in probabilistic models by quantifying uncertainty in predictions and helping refine model performance. Understanding entropy in this context provides insights into model behaviour, mainly when dealing with complex data distributions.
Entropy as a Measure of Model Uncertainty
Entropy measures the unpredictability of outcomes in a probabilistic model. When a model’s predictions are evenly spread across possible outcomes, its entropy is high, indicating greater uncertainty. Conversely, low entropy suggests the model is confident in its predictions.
For example, in classification tasks, entropy can help assess whether the model is confident about its predicted label or uncertain about multiple possibilities. This insight is crucial in scenarios like medical diagnostics or autonomous systems, where uncertainty can directly influence decision-making.
Use in Probabilistic Graphical Models and Bayesian Inference
In probabilistic graphical models, entropy assesses the uncertainty of node distributions and helps refine dependencies between variables. For instance, in Hidden Markov Models (HMMs), entropy aids in determining the most probable sequences while accounting for uncertainty in observations.
In Bayesian inference, entropy complements posterior distributions by helping balance prior knowledge with observed data. It facilitates processes like entropy-based sampling, where high-entropy regions of the parameter space are explored to improve model robustness. This approach ensures the model doesn’t prematurely converge to suboptimal solutions.
Relation to Model Regularisation and Overfitting
Entropy acts as a natural regulariser in probabilistic models. High entropy encourages exploration and prevents the model from overfitting by focusing excessively on specific data points.
Like entropy regularisation in reinforcement learning, regularisation techniques use this principle to maintain model generalizability. These methods discourage overconfident predictions by penalising low entropy, resulting in more balanced and robust models.
Cross-Entropy in Machine Learning
Cross-entropy is pivotal in Machine Learning, particularly in classification tasks and neural networks. It measures the difference between two probability distributions—the true labels and the predicted probabilities. By quantifying how closely the model’s predictions match the actual data, cross-entropy helps guide the learning process. Let’s explore its definition, connection to entropy, and practical applications.
Definition and Connection to Entropy
Cross-entropy extends the concept of entropy by comparing two probability distributions instead of evaluating a single distribution. While entropy measures the inherent uncertainty in a system, cross-entropy evaluates how well one probability distribution predicts another. Mathematically, it is expressed as:
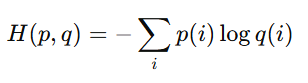
Here, p(i) represents the true probability, and q(i) is the predicted probability. A lower cross-entropy value indicates better alignment between q(i) and p(i), signifying an accurate model.
Use in Classification Tasks and Neural Networks
Cross-entropy loss is a standard objective function in classification tasks, especially for multi-class problems. It measures a model’s performance by penalising incorrect predictions based on their likelihood.
In neural networks, the softmax activation function often works with cross-entropy loss. Softmax converts raw model outputs (logits) into probabilities, making them compatible with cross-entropy calculation.
Practical Example: Softmax and Cross-Entropy Loss
Consider a multi-class classification problem with three classes. A model predicts logits [2.5,0.3,1.2]. Softmax transforms these logits into probabilities: [0.71,0.09,0.20]. If the true label is class 1, the cross-entropy loss is calculated as:
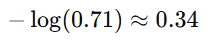
This low loss value reflects a confident and accurate prediction. Cross-entropy ensures the model adjusts its parameters to maximise the probability of true labels, driving efficient learning.
Entropy and Feature Selection
Feature selection is critical in building efficient and interpretable Machine Learning models. Reducing the number of input features can enhance computational efficiency, prevent overfitting, and improve model performance. Entropy, as a measure of uncertainty or impurity, plays a pivotal role in identifying the most informative features from a dataset.
Role of Entropy in Selecting Informative Features
Entropy quantifies the uncertainty in a feature’s ability to predict the target variable. Features that reduce uncertainty in the target are more informative. In classification tasks, this is achieved by calculating the information gain—how much a feature reduces the entropy of the target when it is split on that feature.
For example, in decision trees, entropy determines the best splits at each node. A feature that maximises information gain thereby minimising the target’s uncertainty, is selected for splitting. This process ensures that only the most predictive features are prioritised during tree-building.
Mutual Information and Its Relevance to Feature Selection
Mutual information extends the concept of entropy by measuring the shared information between a feature and the target. Unlike correlation, mutual information captures both linear and non-linear dependencies, making it a versatile tool for feature selection.
High mutual information indicates that a feature shares significant information with the target, making it a strong candidate for inclusion in the model. This approach works well for categorical and continuous data, making it adaptable across various Machine Learning tasks.
Examples of Entropy-Based Feature Selection Algorithms
Algorithms like Minimum-Redundancy-Maximum-Relevance (mRMR) use mutual information to select features relevant to the target and minimally redundant with each other. Other approaches, such as Joint Mutual Information (JMI) and Conditional Mutual Information Maximisation (CMIM), refine feature selection by considering interactions between features and the target.
These algorithms are widely used in domains like bioinformatics, natural language processing, and image recognition, where selecting meaningful features is paramount.
Entropy in Clustering and Unsupervised Learning

In unsupervised learning, clustering is vital in discovering hidden patterns within data. Entropy offers a powerful framework to measure the quality of clustering by assessing the distribution of data points across clusters.
By leveraging entropy-based evaluation metrics, practitioners can determine how well a clustering algorithm performs and decide on the optimal number of clusters to achieve meaningful segmentation.
Measuring Cluster Quality with Entropy
Entropy measures the uncertainty or randomness in the distribution of data points within clusters. A clustering algorithm that produces pure clusters (where all points belong to the same class or share similar features) has lower entropy, indicating higher quality. Conversely, clusters with mixed or scattered data points have higher entropy, reflecting poor quality.
For instance, in document clustering, entropy can evaluate how well documents within a cluster share common topics. Low entropy signifies well-defined clusters, aiding interpretability and decision-making in recommendation systems or market segmentation applications.
Entropy-Based Evaluation Metrics for Unsupervised Learning
Entropy-based metrics help assess clustering algorithms’ performance, especially when ground truth labels are unavailable. One widely used metric is Normalised Mutual Information (NMI), which combines entropy and mutual information to evaluate the similarity between predicted and true clusters.
Another common metric is Cluster Purity, where entropy quantifies how mixed the clusters are concerning a known class distribution. These metrics provide actionable insights into the relative effectiveness of different clustering approaches, such as k-means, hierarchical clustering, or Gaussian mixture models.
Determining the Optimal Number of Clusters
Entropy helps identify the ideal number of clusters by analysing the trade-off between cluster homogeneity and data representation. For example, adding more clusters reduces entropy but risks overfitting, while fewer clusters increase entropy, leading to poor segmentation.
Techniques like the Elbow Method and Silhouette Analysis often incorporate entropy as a guiding metric for choosing the optimal cluster count.
By applying entropy thoughtfully, practitioners ensure more accurate and meaningful clustering outcomes in unsupervised learning tasks.
Entropy in Reinforcement Learning
Entropy is critical in reinforcement learning (RL) as it influences decision-making in uncertain environments. It helps agents balance two conflicting objectives: exploring new possibilities and exploiting known strategies. Researchers and practitioners can develop smarter algorithms that adapt to dynamic challenges by integrating entropy into RL.
Entropy as a Measure of Exploration vs. Exploitation
In RL, agents must decide whether to exploit actions that yield high rewards based on current knowledge or explore new actions that might lead to better long-term rewards. Entropy quantifies the randomness in an agent’s policy.
A high-entropy policy promotes exploration by assigning probabilities to multiple actions, while a low-entropy policy focuses on exploiting a few selected actions. Striking the right balance between exploration and exploitation is vital for optimising performance, especially in highly uncertain environments.
Incorporating Entropy into Reward Functions
Entropy regularisation is a popular technique for embedding entropy into RL reward functions. By adding an entropy term to the objective, algorithms encourage exploration while avoiding premature convergence to suboptimal policies. The modified reward function often takes the form:
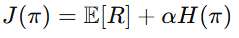
Here, H(π) represents the entropy of the policy π and α controls the weight of the entropy term. This approach ensures agents continue exploring until they identify a robust optimal policy.
Examples from Popular RL Algorithms
Soft Actor-Critic (SAC) exemplifies the practical use of entropy in RL. SAC incorporates entropy into its policy optimisation, aiming to maximise both expected reward and entropy. This design ensures efficient exploration in complex, high-dimensional action spaces.
Other algorithms, like Proximal Policy Optimisation (PPO) with entropy bonuses, also leverage similar concepts to improve learning stability and performance. These methods highlight how entropy fosters adaptability in RL systems.
Future Directions and Research Areas
As Machine Learning evolves, entropy-based approaches are gaining prominence in tackling complex challenges. This section explores innovative applications and research areas where entropy plays a transformative role.
Innovations in Entropy-Based Approaches for Deep Learning
Deep learning models often face overfitting, uncertainty quantification, and interpretability challenges. Entropy has emerged as a tool to address these issues effectively. Researchers are developing entropy-regularised loss functions to encourage model generalisation and prevent overfitting.
Entropy-based uncertainty measures are also being integrated into active learning frameworks to prioritise the most informative samples for training. Moreover, entropy-aware attention mechanisms are being explored to improve interpretability and decision-making in neural networks, particularly in natural language processing and computer vision tasks.
Entropy in Federated and Distributed Learning
Federated and distributed learning systems, which aim to train models across decentralised data sources, encounter significant data heterogeneity and privacy challenges. Entropy is increasingly used to assess data distributions across nodes, ensuring balanced model updates.
It also helps design privacy-preserving mechanisms to protect sensitive information during training, such as entropy-aware differential privacy. Additionally, researchers are exploring entropy-based aggregation strategies to improve the robustness and fairness of global models in federated learning environments.
Cross-Disciplinary Applications of Entropy in AI and Beyond
Entropy’s versatility extends its impact beyond traditional AI. In bioinformatics, entropy aids in genetic sequence analysis and protein structure prediction. In finance, it enhances portfolio optimisation and risk assessment.
Meanwhile, environmental scientists use entropy to model climate dynamics and predict natural disasters. These cross-disciplinary applications demonstrate how entropy fosters innovation across fields, making it a cornerstone for AI-driven solutions in diverse domains.
With ongoing advancements, entropy unlocks new possibilities, cementing its role as a foundational concept in AI and beyond.
In Closing
Entropy, a cornerstone in Machine Learning, quantifies uncertainty to guide data-driven decision-making. Its versatility extends from improving decision trees and probabilistic models to optimising clustering and reinforcement learning. By addressing challenges like uncertainty and overfitting, entropy is pivotal in creating robust algorithms and empowering advanced AI applications across diverse fields.
Frequently Asked Questions
What is Entropy in Machine Learning?
Entropy measures uncertainty or randomness in data, a key concept in Machine Learning. It helps algorithms evaluate unpredictability, enabling efficient decision-making. Applications include decision trees for splitting data, clustering for quality assessment, and probabilistic models for refining predictions. Entropy ensures algorithms handle complex patterns and improve data-driven insights.
How Does Entropy Impact Decision Trees?
Entropy evaluates the quality of data splits in decision trees. Calculating information gain—reducing entropy after a split—identifies features that minimise uncertainty. This process ensures more homogeneous child nodes, improving classification accuracy. Entropy-driven splits result in precise and interpretable decision trees for classification and regression tasks.
What is the Role of Cross-entropy in Machine Learning?
Cross-entropy measures the difference between actual and predicted probability distributions. It’s widely used as a loss function in classification tasks and neural networks. Cross-entropy helps models adjust parameters by quantifying prediction accuracy, improving alignment with true labels. This facilitates robust learning and enhances model performance across diverse applications.
Authors
-

Written by:
Julie BowieReviewed by:



