
Summary: Stochastic Gradient Descent (SGD) is a foundational optimisation algorithm in Machine Learning. It efficiently handles large datasets, adapts through advanced variants, and powers applications in Deep Learning frameworks. Despite challenges like noise and sensitivity to learning rates, SGD remains pivotal, evolving through research to enhance its stability and efficiency.
Introduction
Stochastic Gradient Descent (SGD) is a powerful optimisation algorithm widely used in Machine Learning to minimise loss functions and improve model accuracy. Optimisation is crucial in Machine Learning, ensuring efficient learning and better generalisation.
Introduced in the 1950s, SGD evolved significantly with advancements in computing power and neural networks. This blog explores the mechanics of Stochastic Gradient Descent, its challenges, enhancements, and applications, providing insights to help you implement and optimise it effectively for modern AI solutions.
Key Takeaways
- Stochastic Gradient Descent (SGD) efficiently minimises loss functions and updates model parameters iteratively.
- Random sampling in SGD introduces noise, helping escape local minima and accelerating convergence.
- Variants like Adam and RMSprop improve SGD’s stability, convergence speed, and adaptability.
- SGD faces issues like sensitivity to learning rates, noisy updates, and oscillation near the global minimum.
- SGD powers Deep Learning frameworks like TensorFlow and PyTorch, enabling AI solutions in healthcare, e-commerce, and finance.
Fundamentals of Gradient Descent
Gradient Descent is the backbone of optimisation in Machine Learning. It is an iterative algorithm that helps models minimise the loss function by updating parameters in the direction of the steepest descent. This method identifies the loss function’s gradient, or slope, concerning model parameters and takes steps to reduce iteratively.
The process continues until the loss is minimised or the change in gradient becomes negligible. Gradient Descent is widely used in training linear models and neural networks because of its efficiency and simplicity.
Types of Gradient Descent
Gradient Descent has evolved into several variations to cater to computational needs and dataset sizes. Each type balances accuracy and efficiency, offering unique advantages and trade-offs. Understanding these variants is crucial to selecting the optimal approach for a specific Machine Learning problem.
Batch Gradient Descent
It processes the entire training dataset to compute the gradient in each iteration. This method ensures a stable and smooth convergence path but requires significant memory and computation, making it impractical for large datasets.
Mini-Batch Gradient Descent
It divides the dataset into smaller batches and uses them to compute gradients. It balances computational efficiency and stability, making it the most popular variant for training Deep Learning models.
Stochastic Gradient Descent (SGD)
It updates the parameters for each data point. It is computationally efficient for large datasets and introduces randomness, which helps escape local minima but may lead to noisy updates.
Key Differences Between Batch Gradient Descent and SGD
Batch Gradient Descent updates parameters less frequently but achieves smoother convergence. In contrast, SGD updates parameters more regularly, enabling faster progress but with a noisier path. This difference makes SGD more suitable for large datasets and online learning, while Batch Gradient Descent is better suited for smaller, static datasets.
How SGD Works

Alt Text: How SGD Works
Stochastic Gradient Descent (SGD) is a foundational optimisation algorithm widely used in Machine Learning. Unlike batch gradient descent, which processes the entire dataset in one step, SGD updates model parameters using a single data point or a small subset at a time. This approach makes SGD faster and more efficient, especially for large datasets.
Here’s a detailed look at its workings.
- Initialise Parameters: Begin by randomly initialising model parameters such as weights and biases.
- Shuffle the Dataset: Shuffle the training data to ensure randomness and prevent cyclic patterns during optimisation.
- Select a Data Point: Randomly pick one sample (or a mini-batch) from the dataset.
- Compute Gradient: Calculate the gradient of the loss function concerning the parameters for the selected sample.
- Update Parameters: Adjust the parameters by subtracting the product of the gradient and the learning rate.
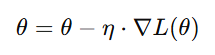
Alt Text: Equation for adjusting parameters
Here, θ represents parameters, η\etaη is the learning rate, and ∇L(θ) is the gradient of the loss function.
- Repeat: Iterate through all data points for a fixed number of epochs or until convergence.
Role of Learning Rate in SGD
The learning rate (η) determines the step size for parameter updates. A high learning rate accelerates convergence but risks overshooting the minimum, while a low learning rate ensures stability but can make the process slower. Adaptive learning rate techniques, such as decay schedules or optimisers like Adam, help balance this trade-off.
Advantages of Random Sampling in Weight Updates
Random sampling adds a stochastic element to the process, helping SGD escape local minima and saddle points. It also reduces the computational cost per iteration, making it scalable for large datasets. Additionally, the randomness injects variability, which often leads to faster convergence compared to deterministic methods.
Challenges in Stochastic Gradient Descent
Stochastic Gradient Descent (SGD) is a widely used optimisation algorithm that comes with its own challenges. While its efficiency and ability to handle large datasets make it indispensable, practitioners often face hurdles in ensuring smooth convergence and optimal performance. Below, we explore the key challenges of SGD and their implications.
Noise and Convergence Issues
SGD’s reliance on randomly sampled data points introduces inherent noise during optimisation. Unlike Batch Gradient Descent, which computes the gradient using the entire dataset, SGD updates the model parameters based on a single or a small batch of data.
This randomness can cause the optimisation path to be less stable, making it harder for the algorithm to converge smoothly. While noise can help escape local minima, it also risks overshooting or oscillating around the global minimum, particularly in high-dimensional problems.
Oscillation Near the Global Minimum
Due to the stochastic nature of SGD, the algorithm may struggle to settle near the global minimum. As it updates parameters based on noisy gradients, it often oscillates instead of converging precisely.
This behaviour becomes more pronounced when the learning rate is not appropriately scaled. Oscillations can lead to suboptimal solutions, especially when fine-tuned precision is critical.
Sensitivity to Learning Rate and Hyperparameter Tuning
The learning rate plays a pivotal role in determining the success of SGD. If the learning rate is too high, the algorithm may fail to converge, continuously bouncing around the solution.
Conversely, a low learning rate can slow progress, requiring excessive computation. Furthermore, hyperparameters like momentum or decay schedules must be meticulously tuned to achieve the best results. Finding the right balance often demands significant experimentation and domain expertise.
Addressing these challenges requires careful tuning, regularisation, and the use of advanced variants like Adam or RMSprop.
Enhancements and Variants of SGD

Alt Text: Enhancements and Variants of SGD
Stochastic Gradient Descent (SGD) has been pivotal in optimising Machine Learning models. However, its vanilla form often needs help with issues like slow convergence, getting stuck in local minima, or sensitivity to hyperparameters like the learning rate.
Various enhancements and variants of SGD have been developed to address these limitations, improving its performance and adaptability in diverse scenarios.
Momentum-Based SGD
Momentum-based SGD introduces a mechanism to accelerate convergence, especially in scenarios with high-dimensional data. By incorporating a fraction of the previous update into the current update, momentum smoothens the path toward the minimum.
This approach reduces oscillations in the gradient direction and helps bypass local minima. The formula for momentum updates adds a velocity term controlled by a hyperparameter (commonly set at 0.9). This technique benefits Deep Learning tasks where the loss landscape is complex and riddled with saddle points.
Learning Rate Schedules
The learning rate significantly impacts SGD’s efficiency. Static learning rates may lead to either slow convergence or overshooting the optimum. Learning rate schedules dynamically adjust the learning rate during training.
Popular strategies include learning rate decay, where the rate decreases as training progresses, and adaptive learning rates, where the rate adjusts based on the gradient magnitude. Techniques like step decay, exponential decay, and cyclical learning rates have proven effective in improving model performance and stability.
Popular Variants
Variants of SGD, like RMSprop, Adagrad, and Adam, combine ideas like adaptive learning rates and momentum for superior performance.
- Adagrad adapts the learning rate individually for each parameter, making it ideal for sparse data.
- RMSprop builds on Adagrad by introducing decay to control learning rate adaptation, preventing minimal updates.
- Adam combines RMSprop and momentum, offering robustness and faster convergence across various problems.
These enhancements make SGD versatile and more effective, solidifying its place in modern Machine Learning.
Applications of SGD
The ability of SGD to handle massive datasets and complex models makes it indispensable across diverse applications, from basic supervised learning tasks to advanced Deep Learning frameworks. Below, we explore how SGD is applied in real-world scenarios.
Use Cases in Supervised Learning
SGD is pivotal in supervised learning tasks such as regression and classification. In linear regression, SGD iteratively updates the model’s coefficients to minimise the error between predicted and actual values, enabling efficient training on large datasets. For logistic regression, commonly used in binary classification, SGD optimises the likelihood function to ensure accurate predictions.
SGD is the backbone for training models in neural networks by minimising the loss function. It adjusts the weights and biases of the network layer by layer, making it highly effective for tasks like image recognition, natural language processing, and time-series forecasting.
Application in Deep Learning Frameworks
SGD is integral to popular Deep Learning frameworks like TensorFlow and PyTorch, where it is implemented with various enhancements. These frameworks often use SGD variants like Adam or RMSprop to improve convergence speed and stability.
For example, in convolutional neural networks (CNNs) used for image analysis or recurrent neural networks (RNNs) applied to sequential data, SGD helps fine-tune model parameters to achieve state-of-the-art performance.
Real-World Examples of SGD in Action
Major companies leverage SGD to power innovative solutions. Google uses SGD to train its search algorithms and language models. Amazon applies SGD in recommendation engines to personalise shopping experiences. In healthcare, SGD facilitates training Deep Learning models for medical imaging, improving diagnostics and treatment planning.
SGD’s versatility and efficiency make it a key driver in advancing Machine Learning across industries.
Practical Implementation of SGD
Stochastic Gradient Descent (SGD) is widely used to optimise Machine Learning models due to its simplicity and efficiency. Implementing SGD effectively requires understanding its workflow, utilising the right tools, and troubleshooting potential challenges. Here’s a practical guide to get you started.
Implementing SGD in Python is straightforward. Below is a step-by-step approach:
- Initialise Parameters: Define model parameters (weights and biases) and set a learning rate.
- Compute Gradients: Use the loss function to calculate the gradient of each parameter.
- Update Parameters: Adjust parameters using the formula
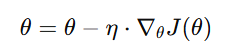
Where θ is the parameter, η is the learning rate, and ∇θJ(θ) is the gradient.
- Iterate: Loop over the training data multiple times (epochs) until convergence.
Example Code:
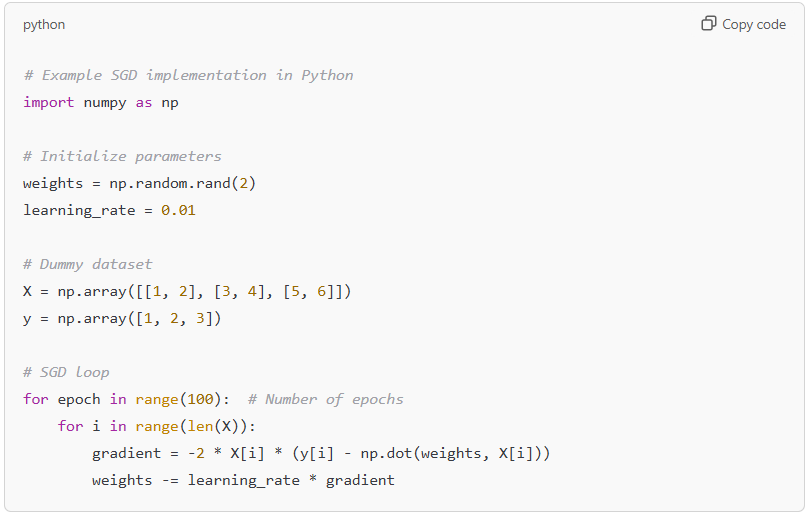
Alt Text: Code showing SGD loop to update weights iteratively.
Common Libraries Supporting SGD
Modern Machine Learning frameworks make implementing SGD seamless. Libraries like TensorFlow and PyTorch provide prebuilt optimisers, allowing you to focus on model design and experimentation rather than writing low-level code.

Alt Text: PyTorch example of SGD optimiser with training loop.
By using these libraries, you gain access to advanced features like momentum, adaptive learning rates, and GPU acceleration, enhancing the flexibility and efficiency of your implementation.
Tips for Debugging and Optimising
Debugging and optimising SGD is essential for achieving stable and fast convergence. Small adjustments in hyperparameters or preprocessing techniques can significantly affect training outcomes.
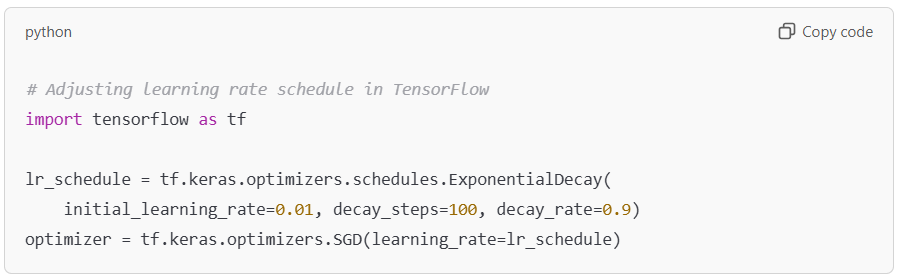
Alt Text: TensorFlow code for SGD with exponential decay.
Regularly monitor loss values, normalise data, and experiment with learning rate schedules to ensure smooth convergence. Debug unexpected behaviours early to prevent prolonged training inefficiencies.
By combining the right tools and techniques, you can unlock the full potential of SGD for your Machine Learning projects.
Future Prospects and Research
As Machine Learning evolves, Stochastic Gradient Descent (SGD) remains central to optimisation. However, with the increasing complexity of models and datasets, researchers are exploring ways to enhance its efficiency, stability, and adaptability. This section delves into key innovations, emerging trends, and challenges in SGD-based optimisation.
Innovations in Optimisation Algorithms Building on SGD
Recent advancements aim to refine SGD by addressing its limitations, such as slow convergence and sensitivity to hyperparameters. Momentum-based methods like Nesterov Accelerated Gradient (NAG) and adaptive approaches like Adam have demonstrated faster convergence and robustness in diverse scenarios.
Moreover, second-order methods, such as those incorporating curvature information (e.g., L-BFGS), are being hybridised with SGD to balance computational efficiency and precision.
Another notable innovation is variance reduction techniques, such as SVRG (Stochastic Variance Reduced Gradient), which stabilise updates by reducing noise, thereby improving convergence rates. Researchers are also exploring quantum-inspired optimisation algorithms incorporating SGD principles for faster computation in high-dimensional spaces.
Trends in Combining SGD with Other Methods
A growing trend involves integrating SGD with reinforcement learning (RL) techniques. For instance, policy gradient methods in RL rely heavily on SGD to optimise policies in continuous action spaces. Similarly, combining SGD with evolutionary algorithms enables more diverse exploration during optimisation, particularly in problems with sparse gradients.
In federated learning, researchers adapt SGD for distributed environments, where data resides on multiple devices. Techniques like Federated Averaging extend SGD to address challenges such as communication efficiency and data heterogeneity.
Challenges to Address in Future Research
Despite advancements, SGD faces challenges. Ensuring stability in non-convex optimisation remains a critical issue, especially with increasingly deeper neural networks. Developing adaptive learning rate strategies that require minimal tuning is another pressing need. Additionally, researchers are prioritising addressing SGD’s inefficiency in handling sparse and imbalanced data.
Future work must also focus on enhancing the interpretability of SGD-based optimisation processes to foster greater trust and transparency in AI systems.
Closing Statements
Stochastic Gradient Descent (SGD) is an indispensable algorithm for optimising Machine Learning models. Its efficiency in handling large datasets, adaptability with various enhancements, and suitability for Deep Learning frameworks make it a cornerstone in modern AI.
While it has challenges like sensitivity to hyperparameters and noisy updates, advanced variants like Adam and RMSprop have mitigated many issues. With ongoing research and innovations, SGD continues evolving, ensuring robust performance across healthcare, e-commerce, and finance industries.
Practitioners can unlock its potential to build accurate and efficient Machine Learning solutions by understanding its mechanics, applications, and enhancements.
Frequently Asked Questions
What is Stochastic Gradient Descent (SGD)?
Stochastic Gradient Descent (SGD) is an optimisation algorithm used in Machine Learning to minimise loss functions by iteratively updating parameters using individual data points.
Why is SGD Important in Machine Learning?
SGD’s efficiency in handling large datasets and its ability to optimise complex models like neural networks make it crucial for training Machine Learning algorithms.
How does SGD Differ from Batch Gradient Descent?
SGD updates parameters using single data points, introducing randomness and faster updates, whereas Batch Gradient Descent uses the entire dataset for smoother but slower convergence.
Authors
-

Written by:
Karan SharmaReviewed by:



