
Summary: Hydra simplifies process configuration in Machine Learning by dynamically managing parameters, organising configurations hierarchically, and enabling runtime overrides. It enhances scalability, experimentation, and reproducibility, allowing ML teams to focus on innovation. With Hydra, managing complex workflows becomes efficient, ensuring consistency and flexibility across development, testing, and production environments
Introduction
Managing process configuration in Machine Learning is often complex, involving scattered parameters, environment mismatches, and scaling challenges. These issues can hinder experimentation, reproducibility, and workflow efficiency.
As the global Machine Learning market, valued at USD 35.80 billion in 2022, is expected to soar to USD 505.42 billion by 2031 at a CAGR of 34.20%, efficient configuration management becomes critical for success.
This blog highlights the importance of organised, flexible configurations in ML workflows and introduces Hydra. By the end, you’ll understand Hydra’s benefits, implementation strategies, and how it simplifies ML configurations to drive scalable innovation.
Key Takeaways
- Dynamic Configurations: Hydra enables dynamic configuration management using modular YAML files and runtime overrides.
- Scalability: Manage complex Machine Learning workflows with hierarchical and composable configurations.
- Enhanced Experimentation: Override parameters dynamically to experiment with hyperparameters or models effortlessly.
- Improved Reproducibility: Maintain consistent, shareable configurations for seamless collaboration and result replication.
- Flexibility Across Environments: Adapt configurations seamlessly across development, testing, and production workflows.
The Challenges of Process Configuration in Machine Learning
Efficient process configuration is critical for the success of Machine Learning projects. However, many teams face persistent challenges that hinder scalability, flexibility, and reproducibility. Let’s explore the key hurdles that make configuration management complex in Machine Learning workflows.
Static and Scattered Configurations
Static configurations often lead to rigid workflows that lack adaptability. Machine Learning projects evolve rapidly, frequently introducing new data, models, and hyperparameters. Scattered configurations, spread across files and scripts, make it difficult to track changes, leading to errors and inefficiencies.
Difficulty in Scaling Experiments
Scaling experiments requires a flexible configuration system that can seamlessly handle multiple variations. Without it, teams spend significant time manually updating parameters and tracking changes, slowing experimentation. This inefficiency becomes a bottleneck as projects grow in size and complexity.
Managing Multiple Environments and Parameters
Machine Learning workflows often span diverse environments, including development, testing, and production. Maintaining consistent configurations across these environments is challenging. Small discrepancies in parameters or paths can lead to unexpected failures, consuming valuable debugging time.
Impact on Productivity and Reproducibility
Poor configuration management directly affects productivity. Inconsistent setups make it hard to reproduce results, undermining trust in the outcomes. Teams lose momentum, spending more time fixing issues than driving innovation, ultimately slowing the entire project lifecycle.
What is Hydra?

Hydra is a powerful Python-based configuration management framework designed to simplify the complexities of handling configurations in Machine Learning (ML) workflows and other projects. It enables developers to dynamically manage, compose, and override configurations with minimal effort, making it an essential tool for anyone working on scalable and reproducible projects.
Overview of Hydra
Hydra provides a structured way to organise configurations at its core, enabling dynamic manipulation of parameters without altering the original codebase. Whether you are building a simple ML model or managing complex workflows across multiple environments, Hydra offers a clean, centralised solution to manage your configurations efficiently.
Hydra is open-source and widely adopted for its flexibility and seamless integration with ML frameworks like PyTorch, TensorFlow, and Scikit-learn. It bridges the gap between static configuration files and the need for dynamic, adaptable setups in iterative workflows.
Key features of Hydra are:
- Dynamic Configuration Management
Hydra allows you to define configurations as modular YAML files, which can be dynamically loaded and modified during runtime. This feature makes it easy to adapt to changing requirements without hardcoding values. - Composability
With Hydra, configurations can be split into multiple files and combined hierarchically. This composability ensures scalability in managing configurations across large projects. - Overrides
Hydra’s CLI supports on-the-fly parameter overrides. Users can modify values such as learning rates, batch sizes, or dataset paths directly from the command line, enabling rapid experimentation.
Use Cases in ML Workflows
Hydra excels in scenarios requiring frequent parameter tuning, such as hyperparameter optimisation, multi-environment testing, and orchestrating pipelines. It also simplifies managing configuration dependencies in Deep Learning projects and large-scale data pipelines.
Why Hydra is a Game-Changer for ML Practitioners
Hydra transforms the tedious configuration management process into a streamlined, flexible, and reusable system. By enabling rapid experimentation, clear organisation, and scalability, it empowers ML practitioners to focus on innovation rather than administrative overhead.
Key Benefits of Using Hydra in ML Projects
Hydra is transforming how Machine Learning (ML) practitioners manage configurations, making it easier to scale workflows, enhance experimentation, and maintain consistency. Here’s how Hydra addresses some of the most common challenges in ML projects:
Simplified Configuration Management
Hydra centralises and organises all configuration files, eliminating the hassle of managing scattered settings across different experiments. Instead of manually editing multiple files, you can define hierarchical configurations that are easy to understand and modify. This streamlined approach allows you to focus on building and improving models rather than grappling with redundant configurations.
Improved Experimentation
Hydra makes it seamless to experiment with different hyperparameters and settings. You can override parameters dynamically from the command line without altering the original configuration files, enabling rapid prototyping and iterative experimentation.
Whether you’re tuning a model or testing multiple environments, Hydra’s flexibility reduces manual effort and accelerates the experimentation process.
Enhanced Scalability
Hydra supports hierarchical configurations, allowing you to handle even the most complex ML workflows effortlessly. It enables you to nest configurations and reuse components, ensuring modularity and clarity. As your project scales, Hydra makes it easy to manage dependencies and adapt configurations to different stages of development or production.
Reproducibility
Reproducibility is critical in ML, and Hydra ensures your configurations remain consistent and shareable. By maintaining well-organised and version-controlled configuration files, Hydra simplifies collaboration and debugging. Anyone can replicate your experiments with minimal effort, ensuring consistent results across teams or systems.
With Hydra, ML projects become more efficient, scalable, and reliable, empowering teams to focus on innovation rather than configuration headaches.
Implementing Hydra in Machine Learning Workflows
Hydra simplifies managing configurations for Machine Learning workflows, allowing developers to experiment dynamically and organise their settings. This section walks you through installing Hydra, setting up a configuration file, and using it in a Machine Learning pipeline.
Step-by-Step Guide to Using Hydra
Following these steps, you’ll integrate Hydra into your ML workflows to manage parameters dynamically and efficiently.
- Installing Hydra
To get started, install Hydra using pip. This will set up the core functionality required for your project.

Verify the installation using the following command, which checks Hydra’s CLI functionality:

- Setting Up a Basic Configuration File
Hydra organises configurations using YAML files, making them modular and easy to update. Here’s how to set up a basic configuration file for a Machine Learning project.

Place this file in a conf directory. This structure allows you to maintain a clear and reusable configuration for your project.
- Using Hydra CLI for Parameter Overrides
Hydra’s CLI enables you to override parameters dynamically without modifying the configuration file. This feature is ideal for running multiple experiments quickly.

The above command modifies the current run’s batch size and learning rate while preserving the base configuration.
Example Use Case: Training a Machine Learning Model with Hydra
Using Hydra in a Machine Learning project demonstrates its power in managing dynamic configurations and simplifying experimentation.
- Configuring the Training Script
To integrate Hydra into a training script, use the @hydra.main decorator. Here’s a sample script that loads configurations dynamically.
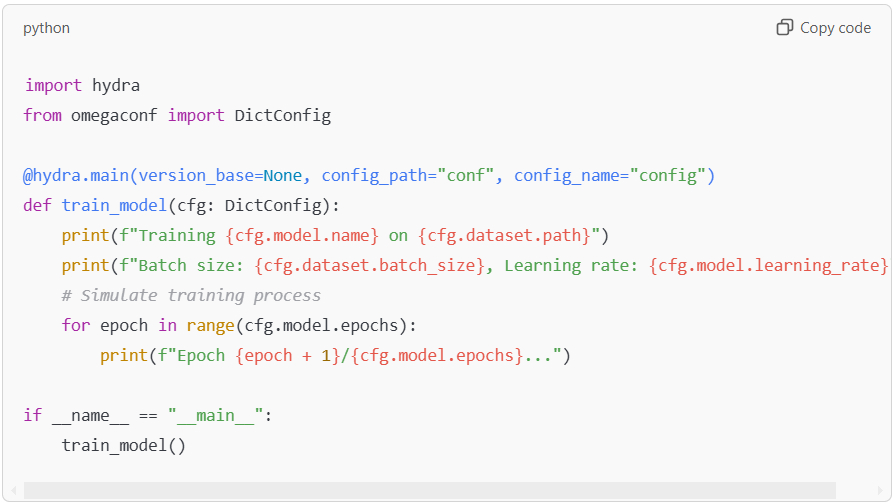
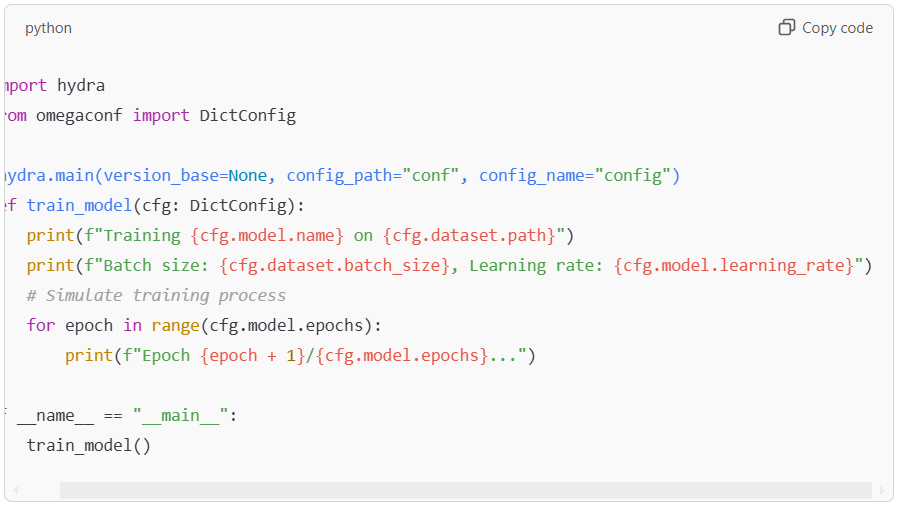
This script pulls parameters from the configuration file and dynamically applies them to the training process.
- Demonstrating Dynamic Parameter Tuning
Dynamic tuning of parameters becomes straightforward with Hydra. You can adjust values for experimentation without modifying the code.

Passing overrides allows you to experiment with different models and hyperparameters efficiently.
With Hydra, Machine Learning workflows become more adaptable, efficient, and reproducible, ensuring you can focus on optimising your models without worrying about configuration chaos.
Best Practices for Using Hydra in ML
Adopting Hydra in your Machine Learning (ML) workflows can simplify configuration management and enhance scalability. However, to maximise its potential, you must follow certain best practices. From structuring configuration files to integrating with popular ML frameworks, these tips will ensure your Hydra implementation is efficient and error-free.
Structure Configuration Files for Clarity and Scalability
Organised configuration files are the backbone of effective Hydra usage. Start by grouping related parameters into separate YAML files. For example, maintain distinct files for model hyperparameters, dataset paths, and logging settings. Use hierarchical structures to define default settings and include environment-specific overrides for scalability.
Adhering to this modular approach makes configurations easier to maintain and update. This practice fosters collaboration, as team members can quickly understand and modify specific components without disrupting the setup.
Leverage Configuration Overrides Effectively
One of Hydra’s standout features is its ability to override configurations dynamically. This capability can test different parameters without modifying the base configuration files. For instance, you can run experiments with varying learning rates or batch sizes directly from the command line:

Additionally, leverage Hydra’s multi-run feature to automate hyperparameter sweeps. This will save time and ensure systematic testing of combinations, improving your ML model’s performance.
Integrate Hydra with Popular ML Frameworks
Hydra works seamlessly with ML frameworks like PyTorch, TensorFlow, and Scikit-learn. Pass configurations directly into your training scripts using Hydra’s @hydra.main decorator when integrating. For instance, PyTorch users can dynamically feed configuration values for learning rates, optimisers, and layers into their models.
For better flexibility, ensure your configuration files include default settings tailored to your chosen framework. This avoids redundant coding and aligns with Hydra’s composability principle.
Avoid Common Pitfalls
While Hydra simplifies configuration management, certain pitfalls can disrupt your workflow. Configuration conflicts are a common issue, especially when multiple overrides clash. Prevent this by thoroughly testing each override scenario and using Hydra’s validation features.
Versioning issues can also arise when working in teams or across environments. Use tools like Git to version-control your configuration files and ensure consistency. Document your configuration structure to make onboarding smoother for new team members.
Following these best practices can unlock Hydra’s full potential, streamline your ML processes, and avoid common challenges. Structured configurations, effective overrides, seamless integration, and attention to pitfalls will position you for success in building scalable, reproducible ML workflows.
Challenges and Limitations of Hydra
While Hydra offers immense flexibility and power for managing configurations, it has challenges. Understanding its limitations can help users maximise its potential while avoiding pitfalls. Here are the key challenges and some scenarios where alternatives might be worth considering.
Learning Curve for New Users
The initial learning curve can feel steep for those unfamiliar with Hydra or dynamic configuration tools. Hydra introduces concepts like hierarchical configurations, overrides, and composable configs, which may be new to many developers.
Beginners might struggle to structure configurations correctly or troubleshoot errors from complex overrides. Adequate training and time investment are required to unlock its full potential. However, once mastered, Hydra’s benefits far outweigh the initial effort.
Potential Bottlenecks in Large-Scale Deployments
Hydra’s flexibility can sometimes introduce bottlenecks in large-scale projects, particularly when managing deeply nested configurations. Teams working in distributed environments may encounter version control and consistency issues if configurations are not standardised.
Hydra’s reliance on YAML files can also lead to verbose configurations, which may become unwieldy as projects grow. Proper planning and adherence to best practices, such as modular configuration structures, can mitigate these risks.
Alternatives to Hydra and When to Consider Them
While Hydra is highly versatile, it may not best suit every project. Simpler tools like Argparse or ConfigParser are sufficient for small-scale projects or scripts with limited configuration needs. Tools like OmegaConf (Hydra’s underlying library) or Cerberus may also suit projects requiring lightweight configuration management without Hydra’s composability.
Teams already committed to other ecosystem-specific solutions, such as TensorFlow’s tf.config, might prefer using familiar tools for faster integration.
By understanding these challenges and evaluating alternatives, teams can make informed decisions and tailor their configuration management approach to their needs.
Bottom Line
Hydra revolutionises process configuration in Machine Learning, simplifying dynamic workflows, experimentation, and scalability. By organising configurations hierarchically and enabling overrides, Hydra empowers teams to focus on innovation, not complexity. Despite a learning curve, its benefits far outweigh its challenges, making it a go-to tool for scalable, reproducible Machine Learning workflows.
Frequently Asked Questions
What is Process Configuration in Machine Learning?
Process configuration in Machine Learning involves managing parameters, environment setups, and workflows to ensure smooth experimentation, scalability, and reproducibility.
How Does Hydra Simplify ML Configurations?
Hydra organises parameters into modular YAML files, supports overrides, and enables seamless configuration management across environments, enhancing flexibility.
Why is Configuration Management Critical in ML?
Efficient configuration management ensures scalability, reproducibility, and reduced debugging, saving time and boosting innovation in Machine Learning workflows.
Authors
-

Written by:
Neha SinghReviewed by:



