
Summary : The mode in statistics is the most frequently occurring value in a dataset, ideal for identifying trends in categorical and numerical data. Understanding the mode and its types (unimodal, bimodal, multimodal) provides insights into common values, supporting effective decision-making across business, education, healthcare, and more.
Introduction
Statistics is crucial in understanding data and making informed decisions across various fields. Among the key measures of central tendency—mean, median, and mode—knowing the mode in statistics is essential for analysing datasets effectively.
The mode represents a dataset’s most frequently occurring value, offering valuable insights, mainly when data distributions vary. This article will explore the concept of mode, its calculation, applications, and significance in statistical analysis, providing a comprehensive understanding of this vital statistical measure.
If you are curious about ‘n’ in statistics.
Key Takeaways
- The mode is a crucial measure of central tendency that identifies the most frequent value.
- Types of modes—unimodal, bimodal, and multimodal—offer insights into data distribution.
- Unlike mean or median, the mode is ideal for categorical data and unaffected by outliers.
Understanding the Mode

In statistics, the mode refers to the value that appears most frequently in a data set. It is a measure of central tendency, which helps summarise numbers. Unlike other measures such as mean and median, the mode can be used with categorical and numerical data.
For instance, in a survey of favourite fruits, if “apple” is mentioned most often, then “apple” is the mode of that data set.
How Mode Differs from Mean and Median
The mode differs significantly from other measures of central tendency, like mean and median. The mean is the average of all values, calculated by summing the numbers and dividing by the count. Conversely, the median represents the middle value when the data is sorted in ascending or descending order.
While outliers can influence the mean, and the median provides a measure of central tendency that divides the data into halves, the mode focuses solely on frequency. This distinction makes the mode particularly useful for understanding the most common value in a set, regardless of its position.
Importance of Mode in Data Sets
Understanding the mode is crucial in various fields, as it reveals the most prevalent trends within data. For example, identifying the mode of sales figures in retail can help businesses determine which products are most popular among consumers. In educational settings, the mode can indicate students’ most common grade or score, allowing educators to assess overall performance.
Moreover, the mode can be invaluable in market research, allowing companies to tailor their strategies based on their target audience’s most frequently desired attributes. The mode provides insights that aid decision-making and strategy development by highlighting the most common occurrences.
Here are some important blogs for you related to statistics:
Process and Types of Hypothesis Testing in Statistics.
A Comprehensive Guide to Descriptive Statistics.
Crucial Statistics Interview Questions for Data Science Success.
Types of Mode
In statistics, mode is often associated with the most common value in a dataset. However, datasets can sometimes have more than one mode. This variability in mode leads to three primary types: Unimodal, Bimodal, and Multimodal.
Understanding these types can help identify trends, patterns, and the nature of data distribution, ultimately improving data interpretation. Let’s dive into each type of mode with definitions and examples.
Unimodal
A Unimodal dataset has one clear mode, which contains a single value that appears more frequently than any other value. This type of mode is the simplest and most commonly encountered in statistics, often giving a quick insight into the data’s central tendency.
Example of Unimodal Data
Consider a dataset representing the number of books read by a group of students in a month:
3, 5, 7, 7, 9, 10, 12
In this dataset, the number 7 appears twice, more frequently than any other number. Thus, the mode makes this dataset unimodal. Here, the mode indicates the most common reading level among the students in this sample.
When Unimodal Mode is Useful
Unimodal data is often encountered when a single value is expected to dominate, such as average monthly sales, number of hospital visits, or test scores. By identifying a clear, unimodal mode, researchers can quickly determine the most frequent or typical behaviour in the dataset, aiding in decision-making and trend analysis.
Bimodal
A Bimodal dataset has two modes, meaning two values appear with the highest frequency. Bimodal distributions are useful when the data has two peaks or clusters, reflecting two dominant groups within a single dataset. Bimodal data may indicate a split or dual pattern in data, highlighting two distinct trends.
Example of Bimodal Data
Consider a dataset showing the number of cups of coffee consumed by office workers in a day:
1, 3, 3, 4, 6, 6, 8, 10
In this example, 3 and 6 appear twice, making them the two modes of the dataset. This dataset is, therefore, bimodal, suggesting two common levels of coffee consumption among the workers.
When Bimodal Mode is Useful
Bimodal distributions can reveal underlying subgroup behaviours, such as preferences or consumption habits. For instance, a bimodal distribution in market research might indicate two main customer groups with different product preferences. Recognising bimodal patterns helps businesses and researchers understand diverse trends within a dataset, allowing for more targeted analysis.
Multimodal
A Multimodal dataset has three or more modes, which include multiple values with the same high frequency. Multimodal data often signifies a complex distribution, with several peaks or commonly occurring values within a dataset. This complexity may indicate a highly varied population or multiple overlapping groups within the data.
Example of Multimodal Data
Imagine a dataset recording the number of hours people spend on different hobbies each week:
2, 2, 5, 5, 8, 8, 12, 15, 15
The numbers 2, 5, 8, and 15 occur twice, making them the modes. The multimodal dataset indicates multiple popular durations for hobby engagement, potentially due to varied lifestyle choices among different demographic groups.
When Multimodal Mode is Useful
Multimodal data is commonly seen in datasets representing diverse populations, such as large-scale surveys, where respondents’ answers fall into several common categories. Multimodal patterns reveal the presence of multiple preferences or behaviours within the data, which is essential for nuanced analysis and segment-specific insights in fields like public health, marketing, and social science.
How the Type of Mode Affects Data Interpretation
Understanding whether a data set is unimodal, bimodal, or multimodal is vital for accurate interpretation. Each type of mode provides different insights, shaping the way data analysts and researchers conclude the data:
Unimodal Data
With a single peak, unimodal data points to a centralised trend, making it simpler to analyse and interpret. Unimodal distributions suggest that most data points follow a standard pattern or central value, which is helpful for generalisations.
Bimodal Data
Bimodal distributions indicate the presence of two distinct groups or behaviours within the data, which can lead to deeper analysis. When data is bimodal, understanding the underlying characteristics of each subgroup becomes essential, as merging these groups could obscure meaningful distinctions.
Multimodal Data
Multimodal distributions reveal a high level of diversity within the data, often reflecting several independent patterns. For complex data sets, multimodality may indicate that the population has several subgroups, each exhibiting unique characteristics. Accurate interpretation of multimodal data requires separating these groups or employing techniques like clustering to analyse each group independently.
You might be interested in knowing about inferential statistics.
How to Calculate the Mode

While calculating the mode may seem straightforward, different approaches depend on the type of data. Below is a step-by-step guide with examples to help you find the mode in ungrouped and grouped data.
Calculating the Mode for Ungrouped Data
For ungrouped data, the mode is simply the value that occurs most frequently. This is often used with small data sets or when analysing qualitative data.
- Identify the Most Frequent Value: List all values in the data set and count how often each value appears.
- Determine the Mode: The mode is the value with the highest frequency. The data set is multimodal if multiple values have the same highest frequency.
Example: Suppose we have a data set: 3, 7, 3, 8, 9, 3, 8.
- Step 1: Identify the frequency of each value: 3 appears three times, 8 appears twice, and 7 and 9 each appear once.
- Step 2: Since 3 has the highest frequency, the mode is 3.
Calculating the Mode for Grouped Data
For grouped data, the mode is found within the modal class, the class interval with the highest frequency. This calculation requires a formula to estimate the precise mode within that interval.
Formula:
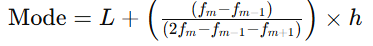
Where:
- L = Lower limit of the modal class
- fm = Frequency of the modal class
- fm−1 = Frequency of the class before the modal class
- fm+1 = Frequency of the class after the modal class
- h = Class interval width
Example:
Consider a data set divided into intervals:
- 10-20: frequency 4
- 20-30: frequency 8
- 30-40: frequency 15 (Modal class)
- 40-50: frequency 7
- 50-60: frequency 5
Using the values for the modal class:
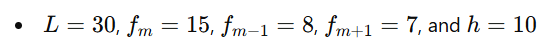
Substitute these into the formula to calculate the mode: ![]()
Following this calculation will give the approximate mode for the grouped data.
Do you know what the variables in statistics are? If not, then click on the hyperlink.
When to Use the Mode
The mode is a valuable measure of central tendency when analysing categorical or nominal data, especially in cases where identifying the most frequent occurrence within a data set is essential. Unlike the mean and median, which are influenced by all values in a data set, the mode represents only the most commonly occurring value. Here’s when the mode can be beneficial:
Categorical Data Analysis
Mode is ideal for categorical data, like survey responses or product preferences, where it reveals the most popular category or choice.
Identifying Patterns in Consumer Preferences
Businesses often use mode to understand customer preferences by pinpointing the most frequently purchased product, the most common size, or preferred features.
Data Sets with Outliers
The mode remains unaffected in data with extreme values, making it more stable and reliable for understanding central tendency without skew.
Non-Numeric Data Analysis
Mode is often the only viable option for non-numeric data, such as finding the most common name, location, or other qualitative attributes.
Simplified Reporting
When communicating results to a general audience, the mode provides an easily understandable figure representing popular choices or trends in data.
You should definitely check out the best statistics books for data science.
Applications of Mode

The mode plays an essential role in statistical analysis, offering insights into a data set’s most frequently occurring values. This measure of central tendency is handy across various fields, helping analysts and decision-makers understand trends, preferences, and common outcomes within a group. Here are some critical applications of the mode across different industries:
Business and Marketing
Companies use the mode to identify popular products, customer preferences, or high-frequency purchase items. This insight helps tailor inventory and marketing strategies to effectively meet customer demand.
Education
In academic assessments, the mode can show the most common scores, allowing educators to gauge student performance trends and identify any prevalent knowledge gaps.
Healthcare
Medical professionals use the mode to analyse common symptoms among patient groups, assisting in diagnosing illnesses and tailoring treatment plans based on the most frequent symptoms.
Retail
Retailers often rely on the mode to understand best-selling products. Knowing the mode helps optimise stock levels, promotions, and shelf placement.
Public Policy
Government agencies may apply the mode to survey data, such as understanding the most common housing types or income brackets in a population, to inform resource allocation and policy development.
These applications show how the mode provides valuable insights that can guide industry decision-making.
Take a look at parameters in statistical analysis by clicking on the link.
Limitations of Mode
The mode is a simple measure of central tendency, but its limitations can affect its usefulness in statistical analysis. Unlike the mean or median, the mode doesn’t always offer a comprehensive view of the data. Here are some key limitations to consider:
Inapplicability for Continuous Data
The mode is less useful for continuous data sets, as it applies best to discrete data with distinct values. This limitation makes using the mode for precise; continuous data analysis challenging.
Lack of Uniqueness
Some data sets may be multimodal, with multiple modes, or even lack a mode entirely, especially when all values appear with similar frequencies. This ambiguity can complicate data interpretation.
Sensitivity to Data Changes
One of the limitations of mode is that it can be highly sensitive to minor data changes. Adding or removing a single data point can shift the mode, leading to potential instability in the analysis.
Limited Descriptive Power
The mode provides minimal insight into the data distribution and spread. It focuses only on the most frequent value, which may not represent the data accurately in skewed distributions.
Dependency on Frequency
Mode is heavily dependent on the frequency of data points, so it may not accurately represent central tendency in smaller or widely varied data sets.
Understanding these limitations helps you decide when the mode suits your analysis.
In the end, learn the difference between Descriptive and Inferential Statistics by clicking here.
Closing Statements
The mode is a critical measure of central tendency in statistics, providing insights into the most frequently occurring values within a dataset. Unlike the mean or median, the mode is ideal for categorical and numerical data and remains unaffected by extreme values.
Understanding the mode and its types—unimodal, bimodal, and multimodal—enhances data interpretation across varied fields, from business and education to healthcare and public policy.
While it is essential for identifying popular trends, the mode also has limitations, especially in continuous data analysis. However, it offers a straightforward yet powerful means of analysing and communicating key data patterns.
Frequently Asked Questions
What is the Mode in Statistics?
In statistics, the mode is the value that occurs most frequently in a dataset. It’s a critical central tendency measure used for categorical and numerical data to identify the most common value.
When is it Useful to Use the Mode?
The mode is valuable when analysing categorical data, detecting customer preferences, or identifying patterns where the most frequent occurrence is essential. It’s also ideal for datasets with outliers, as it remains unaffected by extreme values.
How is Mode Different from Mean and Median?
Unlike the mean (average) and median (middle value), the mode focuses solely on frequency. This makes it especially useful for identifying the most common value in categorical data, where mean and median may not apply.
Authors
-

Written by:
Aashi VermaReviewed by:



