
Summary: Dropout Regularization is a vital technique in Deep Learning that enhances model generalisation by randomly deactivating neurons during training. This approach prevents overfitting, allowing models to learn robust features and perform better on unseen data. Its effective implementation can significantly improve performance in complex neural networks.
Introduction
In Deep Learning, model generalisation is crucial for creating robust models that perform well on unseen data. Regularization techniques help improve generalisation by preventing overfitting. Dropout Regularization in Deep Learning is a powerful method which forces the model to learn more robust features.
This blog aims to explain dropout, its benefits, practical implementation, and real-world applications. The global Deep Learning market is projected to grow from USD 24.53 billion in 2024 to USD 298.38 billion by 2032, showing an amazing CAGR of 36.7% during the forecast period (2024-2032). Therefore, mastering techniques like dropout is key to staying ahead in this rapidly growing field.
Key Takeaways
- Dropout Regularization enhances model generalisation by preventing overfitting.
- It works by randomly deactivating neurons during training.
- The optimal dropout rate typically ranges from 20% to 50%.
- Dropout is particularly effective for large neural networks.
- Combining dropout with other techniques can further improve model performance.
What is Dropout Regularization?
Dropout is a popular Regularization technique used in Deep Learning models to prevent overfitting. It works by randomly “dropping out” or deactivating a percentage of neurons during each training step. This means that some neurons are ignored during training, forcing the network to rely on a more diverse set of features. Dropout is typically applied to fully connected layers of neural networks.
Impact on Neural Networks and Preventing Overfitting
Dropout helps reduce overfitting by making the model less sensitive to specific neurons. Without dropout, the model may memorise the training data, resulting in poor generalisation of new data.
By randomly omitting neurons during training, dropout ensures that the network cannot solely depend on any single neuron or connection, which promotes learning more robust, generalised features.
This Regularization technique encourages ensemble learning within a single model, as different subsets of neurons are activated on each training pass. As a result, the model becomes more versatile and less likely to overfit, ultimately improving its performance on unseen data.
How Dropout Works
Let’s explore how dropout works and its impact on performance during training and inference.
The application of dropout changes between a model’s training and inference phases. During training, dropout is actively applied, but during inference, it is turned off. This distinction ensures that the model behaves consistently during prediction while still benefiting from Regularization during training.
During Training
Dropout is introduced to prevent the model from relying too heavily on any specific neuron. Each iteration turns off a random subset of neurons (set to zero), forcing the model to learn a more distributed data representation.
This makes it less likely to overfit, as the model is discouraged from memorising patterns specific to any neuron or feature.
During Inference
When making predictions, dropout is not applied, and all neurons are active. However, the outputs are scaled by a factor corresponding to the dropout rate used during training, ensuring the model behaves consistently.
This approach allows the model to leverage the network’s full capacity without the stochasticity introduced by dropout during training.
Probability of Dropout (Hyperparameter) and Its Effect on Performance
The model’s dropout rate, a hyperparameter, dictates the probability with which neurons are randomly dropped during training. The optimal dropout rate depends on the complexity of the model and the dataset, and tuning this parameter is crucial for achieving the best performance.
Effect on Performance
The dropout rate controls the trade-off between underfitting and overfitting. A high dropout rate (e.g., 50%) forces the model to learn more general features and reduces the risk of overfitting. Still, if it’s too high, the model may struggle to capture sufficient information, leading to underfitting.
On the other hand, a low dropout rate may not provide enough Regularization to counteract overfitting. Thus, choosing the right dropout rate is key to improving the network’s generalisation of unseen data.
Example of a Neural Network With and Without Dropout
To understand the practical implications of dropout, comparing a neural network’s performance with and without it is useful. Dropout can significantly improve a model’s generalisation ability by ensuring it does not depend too much on any single neuron.
Without Dropout
In a network without dropout, each neuron in the layer contributes fully to the output, and the network may memorise specific patterns in the training data. While this can improve accuracy on the training set, the model’s performance often suffers when evaluated on unseen data, as it has overfitted to the training set.
With Dropout
When dropout is applied, some neurons are randomly deactivated during training. This forces the model to learn more diverse and generalisable features, making it more robust and better at handling new, unseen data. With dropout, the model becomes less prone to overfitting, leading to improved generalisation.
Mathematical Formulation
Mathematically, the dropout Regularization can be expressed as follows:
For a given layer, let the output before applying dropout be hi, and the dropout mask (a vector that randomly drops certain neurons) be mi, where each mi is 0 or 1 (indicating whether a neuron is kept or dropped).
The output after dropout can be calculated as:
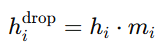
Where ???????? is sampled from a Bernoulli distribution with probability ????, the probability of keeping a neuron. The expected output of a neuron during training is scaled by ![]() to maintain consistent activation values during inference:
to maintain consistent activation values during inference:
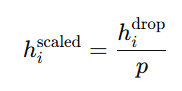
This ensures the output is appropriately scaled during inference when no dropout occurs.
Benefits of Dropout Regularization
Dropouts force the model to learn redundant and robust features by randomly disabling neurons during training, improving its generalisation ability. Let’s explore the main benefits of this approach.
Helps with Generalisation by Reducing Reliance on Specific Neurons
One of the main advantages of dropout is its ability to improve generalisation. During training, neurons are randomly dropped, meaning the model cannot rely too heavily on any single unit.
This forces the network to learn a more diverse set of features, reducing the likelihood of the model memorising training data. As a result, it performs better on unseen data, making it more suitable for real-world applications where new, unseen data is common.
Encourages the Model to Learn Robust Features
Dropout helps in building a more robust model. When neurons are dropped out, the network is forced to learn alternative paths to solve the problem, making it less likely to rely on specific features.
This redundancy allows the model to generalise better. It is trained to extract meaningful patterns without overfitting to noisy or irrelevant data. The model ends up learning features that are truly essential for prediction rather than memorising the training data.
Works Well with Large Networks and Datasets
Dropout is particularly effective in large neural networks with numerous parameters. Overfitting is a common problem in such models due to the network’s high capacity to memorise training data.
Applying dropout regularises large networks, making them more efficient in handling massive datasets. The technique helps maintain deep networks’ performance while preventing them from overfitting to training noise.
Comparison to Other Regularization Techniques
While dropout is highly effective, it isn’t the only Regularization technique. L2 Regularization, known as weight decay, penalises large weights to prevent overfitting. However, dropout tends to be more effective at improving generalisation, as it actively forces the network to learn multiple data representations.
Another alternative, early stopping, involves halting training when performance on the validation set declines. Still, dropout often requires less manual intervention and can be more reliable in large-scale models.
Practical Implementation
This section will discuss implementing dropout in popular Deep Learning frameworks like TensorFlow, Keras, and PyTorch. Additionally, we’ll explore an example code snippet and discuss how to tune the dropout rate for optimal performance.
Implementing Dropout in TensorFlow and Keras
TensorFlow and Keras (now a part of TensorFlow) provide a simple way to implement dropout in neural networks. Dropout is added as a layer in the model architecture. The key parameter to define is the dropout rate, which controls the percentage of neurons to drop during training.
Here is how to implement dropout in a Keras model:

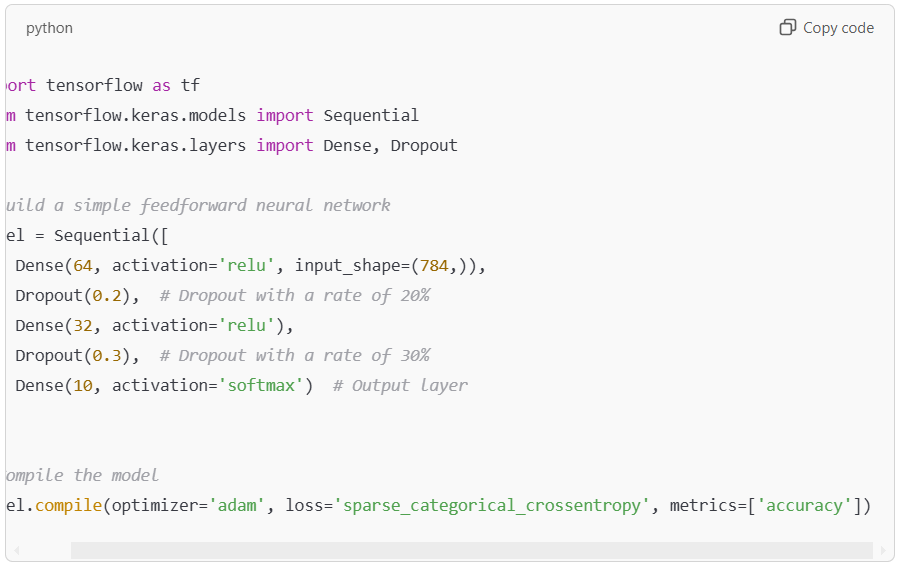
In this example, a Sequential model is defined with two Dropout layers. The dropout rates are set to 20% and 30%, respectively. During training, these layers will randomly drop 20% or 30% of the neurons in the previous layer, which helps prevent overfitting by making the model more robust.
Implementing Dropout in PyTorch
In PyTorch, dropout can be added using the torch.nn.Dropout class. Similar to Keras, the dropout rate is specified as a parameter. However, in PyTorch, dropout is typically applied within a class that defines the neural network architecture.
Here’s how to implement dropout in a simple neural network using PyTorch:
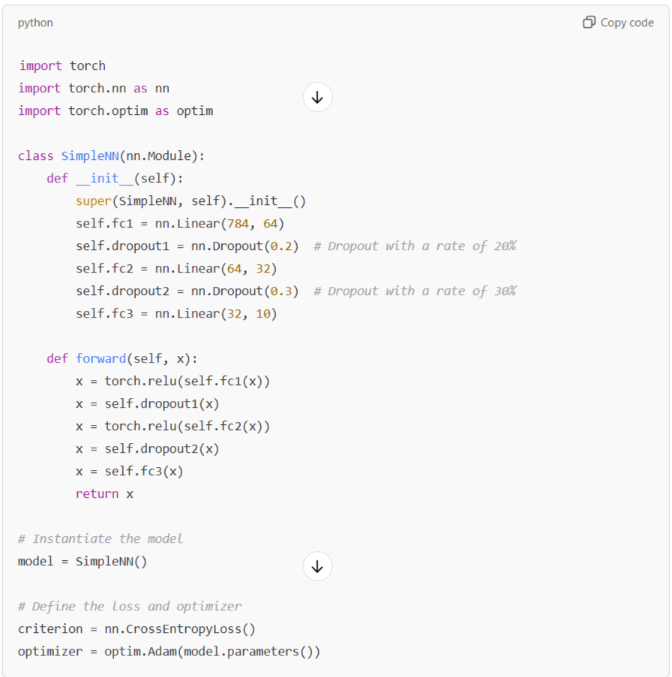
In this PyTorch example, dropout is applied after each fully connected layer using the Dropout class. The dropout rates are set to 20% and 30%. As with TensorFlow, these layers will help reduce overfitting by dropping units randomly during training.
Tuning Dropout Rate for Optimal Performance
The dropout rate is a hyperparameter that plays a crucial role in determining the effectiveness of dropout Regularization . A 20% and 50% dropout rate typically works well for most models. However, the optimal rate may vary depending on the complexity of the model and the dataset.
To tune the dropout rate, you can perform a hyperparameter search, experiment with different dropout rates, and evaluate model performance on a validation set. It’s important to remember that too high a dropout rate may result in underfitting, where the model struggles to learn effectively, while too low a rate may lead to overfitting.
A common approach is to start with a dropout rate of 0.2 (20%) and gradually increase it (e.g., to 0.3 or 0.5) based on training and validation accuracy results. Tools like GridSearchCV in Keras or Optuna in PyTorch can automate this process, helping you find the best dropout rate for your specific task.
When to Use Dropout
Dropout is an effective Regularization technique, but like any tool, it is best used in the right context. Understanding when and how to apply dropout can significantly improve the performance of your models while minimising the risk of overfitting. Here’s an overview of the scenarios where dropout shines and the potential drawbacks to be mindful of.
Types of Models and Tasks Where Dropout is Beneficial
Dropout is especially useful in deep neural networks, where the complexity and number of parameters are high. Convolutional neural networks (CNNs) and recurrent neural networks (RNNs), which often deal with large datasets and complex patterns, benefit from dropout’s ability to prevent overfitting.
When dropout is applied, tasks like image classification, natural language processing (NLP), and time-series forecasting see marked improvements in generalisation.
Dropout is particularly effective when working with large models highly likely to memorise the training data. For example, in a deep CNN used for object detection or an RNN for language modelling, dropout forces the network to rely on multiple paths for decision-making, enhancing robustness.
Potential Drawbacks of Dropout
While dropout is powerful, it is not without its challenges. One of the primary drawbacks is the computational cost. Randomly dropping neurons during training requires additional operations, which can slow the training process, especially in large models.
Furthermore, applying too much dropout can lead to underfitting, where the model becomes too simplistic and fails to capture the underlying patterns in the data.
Another potential issue is tuning the dropout rate. Too high a rate may eliminate too many neurons, while too low may not provide enough Regularization, leading to overfitting. Finding the right balance is key to leveraging dropout effectively.
Guidelines for Applying Dropout
Apply dropout selectively to maximise its benefits. It’s best suited for large, complex models, particularly those prone to overfitting. Begin with a moderate dropout rate (typically 0.2 to 0.5) and experiment with different values during hyperparameter tuning.
Monitor the model’s performance on validation data to ensure the rate is improving generalisation without leading to underfitting. Dropout is most effective during training and should be turned off during inference (testing phase) to retain the model’s full capacity.
Challenges and Considerations
Dropout is a powerful Regularization technique, but like any method, it comes with challenges and considerations that must be carefully addressed for optimal results. Below are some of the key factors to keep in mind when using dropout in Deep Learning models.
Dropout in Very Deep Networks or Large Datasets
Applying dropout to each layer in very deep neural networks can become increasingly difficult. As the depth of the network increases, the likelihood of information being lost due to dropped neurons also increases. T
his could lead to slower convergence and less effective training, especially when large datasets are involved. A deeper network might require more careful tuning of dropout rates to balance the trade-off between reducing overfitting and retaining enough information for learning complex patterns.
Understanding the Trade-off Between Dropout Rate and Model Accuracy
Dropout involves randomly deactivating a percentage of neurons during training. While a higher dropout rate can lead to better Regularization and prevent overfitting, it also increases the risk of underfitting.
Too many neurons dropped can result in a network that lacks sufficient capacity to learn from the data, reducing the model’s accuracy. Therefore, finding the right dropout rate is crucial—too high a rate could harm model performance, while too low a rate may fail to prevent overfitting.
Overcoming Dropout Limitations with Other Regularization Techniques
While dropout is effective, it’s not a one-size-fits-all solution. Combining dropout with other Regularization techniques like L2 Regularization, batch normalisation, or early stopping can help for large or highly complex models. L2 Regularization can prevent weight values from growing too large, while batch normalisation ensures stable learning.
Early stopping monitors performance during training and halts if overfitting begins, reducing reliance on dropout alone. Combining these methods can achieve better results by addressing dropout limitations and improving overall model robustness.
By understanding these challenges and strategically combining techniques, you can maximise the benefits of dropout while minimising its downsides.
Bottom Line
Dropout Regularization is an essential technique in Deep Learning that enhances model generalisation by preventing overfitting. By randomly deactivating neurons during training, dropout encourages the network to develop robust features and diverse data representations.
This method is particularly beneficial for complex models and large datasets, ensuring improved performance on unseen data. As the Deep Learning landscape evolves, mastering dropout and its optimal application will remain crucial for practitioners aiming to build effective models.
Frequently Asked Questions
What is Dropout Regularization in Deep Learning?
Dropout Regularization is a technique for preventing overfitting in neural networks. It involves randomly disabling a fraction of neurons during training. This forces the model to learn more generalised features, improving its performance on unseen data.
How do I Implement Dropout in my Neural Network?
To implement dropout, you can add a Dropout layer in frameworks like TensorFlow or PyTorch. Specify the dropout rate (typically between 20% and 50%) to control the percentage of neurons dropped during training, enhancing model robustness.
What are the Benefits of Using Dropout Regularization?
Dropout reduces reliance on specific neurons, encourages learning of redundant features, and improves generalisation in large networks. It effectively combats overfitting, making it a valuable tool for Deep Learning practitioners.
Authors
-

Written by:
Aashi VermaReviewed by:



