
Summary: Web crawling and web scraping are essential techniques in data collection, but they serve different purposes. Web crawling involves systematically browsing the internet to index content, while web scraping extracts specific data from websites. Understanding their differences helps businesses leverage these tools effectively for SEO, research, and competitive analysis.
Introduction
In the digital age, data is a valuable resource that powers decision-making, enhances user experiences, and drives business strategies. Two essential techniques for gathering data from the web are web crawling and web scraping.
While these terms are often used interchangeably, they refer to distinct processes with different purposes and methodologies. This blog will explore the differences between web crawling and web scraping, their applications, advantages, and the best practices for using these techniques effectively.
What is Web Crawling?

Web crawling is the automated process of systematically browsing the internet to gather and index information from various web pages. This process is crucial for search engines like Google, Bing, and others, which rely on crawlers (often referred to as “spiders” or “bots”) to discover and index new content on the web.
How Web Crawling Works
- Starting Point: Web crawlers begin their journey from a list of seed URLs, which are the initial web pages they will visit. These URLs can be manually specified or generated based on previously crawled data.
- Following Links: As the crawler visits each page, it scans the content and identifies hyperlinks to other pages.It then follows these links to continue the crawling process, creating a web of interconnected pages.
- Data Collection: The crawler collects information from each page it visits, including the page title, meta tags, headers, and other relevant data. Crawlers then store this information in a database for indexing.
- Regular Updates: Web crawlers frequently revisit websites to check for updates or changes in content. This ensures that the indexed information remains current and accurate. Search engines use this updated data to provide relevant results to users.
Key Characteristics of Web Crawling
- Systematic Navigation: Crawlers methodically traverse the web, following links and mapping site structures. This systematic approach helps ensure that no important pages are missed.
- Vast Data Handling: Crawlers process and index massive amounts of data efficiently, making them essential for search engines that index billions of web pages.
- Dynamic Updating: Web crawlers regularly revisit sites to update their data and reflect new changes. This dynamic nature is crucial for maintaining the relevance of search engine results.
- Scalability: They can expand their reach and capacity as the web grows. Advanced crawling algorithms allow them to adapt to new content and changes in website structures.
- Precision: Advanced algorithms ensure they accurately categorise and store data. This precision is vital for search engines to deliver relevant results based on user queries.
Use Cases for Web Crawling
Web crawling extracts data from websites. Web crawling can be a valuable tool for businesses and individuals seeking to gather information from the web.
Search Engine Indexing
The primary use of web crawling is to index web pages for search engines, allowing users to find relevant information quickly. Search engines rely on crawlers to discover new pages and update existing ones.
Website Quality Assurance
Companies use crawlers to check their websites for broken links, missing images, and other issues that may affect user experience. Regular crawling helps maintain website integrity.
Market Research
Researchers may crawl specific websites to gather data on industry trends, competitor analysis, and consumer behaviour. This data can inform strategic decisions and marketing efforts.
Web Archiving
Crawlers create archives of web pages for historical reference or compliance purposes. Institutions like libraries and government agencies use web archiving to preserve digital content.
What is Web Scraping?

Web scraping, on the other hand, is the process of extracting specific data from web pages. Unlike web crawling, which gathers information broadly, web scraping targets particular pieces of data for analysis or use in applications.
How Web Scraping Works
- Target Selection: The first step in web scraping is identifying the specific web pages or elements from which data will be extracted. This could be product listings, reviews, or any other relevant information.
- Data Extraction: Scraping tools or scripts download the HTML content of the selected pages. The scraper then parses the HTML to locate and extract the desired data fields. This process often involves using libraries or frameworks that simplify HTML parsing.
- Data Structuring: The extracted data is often structured into a more usable format, such as CSV, JSON, or Excel, for further analysis or storage. Structuring the data helps facilitate analysis and integration with other systems.
- Automation: Many scraping tools allow for automation, enabling users to schedule scraping tasks to run at specific intervals. This automation is particularly useful for gathering data from dynamic websites that change frequently.
Key Characteristics of Web Scraping
- Targeted Data Extraction: Web scraping focuses on extracting specific information from web pages, such as product prices, user reviews, or contact details. This targeted approach allows for more precise data collection.
- Customizable: Scraping tools can be configured to target specific elements on a page, allowing for flexibility in data collection. Users can specify which data fields to extract based on their needs.
- Data Structuring: The output from web scraping is often organised into structured formats, making it easier to analyse and use. Structured data can be easily imported into databases or analytical tools.
Use Cases for Web Scraping
Web scraping is a powerful technique that extracts data from websites. It has diverse applications, including price comparison, market research, social media monitoring, content aggregation, and even data journalism.
Price Comparison
E-commerce platforms use web scraping to gather pricing information from competitors, enabling them to adjust their prices accordingly. This practice helps businesses remain competitive in the market.
Market Research
Businesses scrape data from various sources to gather insights about consumer preferences, trends, and competitor strategies. This information can inform product development and marketing strategies.
Content Aggregation
News websites or blogs may scrape content from multiple sources to provide a comprehensive overview of current events or topics. This aggregation helps users access diverse information in one place.
Lead Generation
Companies can scrape contact information from websites to build databases of potential customers. This practice is often used in B2B marketing to identify and reach out to prospects.
Key Differences Between Web Crawling and Web Scraping
While web crawling and web scraping are closely related and often used together, they have distinct differences:
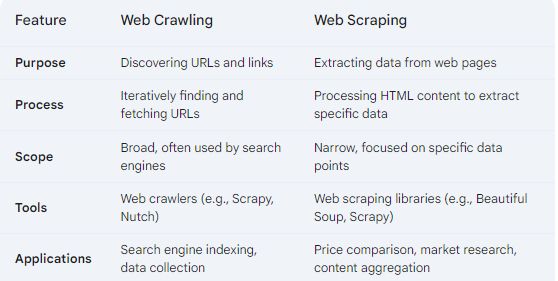
The Interplay Between Web Crawling and Web Scraping
In many data extraction projects, we can use web crawling and web scraping in tandem. The process typically begins with web crawling to discover and index URLs, followed by web scraping to extract specific data from those pages.
Example Workflow
- Crawling: A web crawler starts with a seed URL and follows links to discover all relevant pages on a website. This process helps create a comprehensive map of the site’s content.
- Indexing: The crawler indexes the discovered pages, creating a database of URLs and associated metadata. This indexed data serves as a foundation for targeted scraping.
- Scraping: Once the URLs are indexed, a web scraper extracts specific data fields from the relevant pages. This targeted extraction focuses on the information needed for analysis.
- Data Analysis: The extracted data is then structured and analysed for insights or used in applications. This analysis can inform business strategies, market research, or product development.
Benefits of Using Both Techniques

Web crawling and web scraping are essential techniques for extracting valuable data from websites. These tools enable businesses to gather market intelligence, analyse competitor activities, and gain insights into customer behaviour.
Comprehensive Data Collection
Combining crawling and scraping allows for a more thorough data collection process, ensuring that all relevant information is gathered. This comprehensive approach is essential for businesses that rely on data-driven decisions.
Efficiency
Using crawlers to discover URLs reduces the manual effort required to identify target pages for scraping. This efficiency saves time and resources in data collection efforts.
Improved Data Quality
The interplay between crawling and scraping can enhance the overall quality of the data collected, as crawlers can help filter out irrelevant or duplicate content.
Ethical Considerations
When engaging in web crawling and scraping, it is essential to consider the ethical implications and legal guidelines surrounding these practices. Here are some key points to keep in mind:
Respect Robots.txt
Most websites have a robots.txt file that outlines the rules for web crawlers and scrapers. This file specifies which parts of the site can be crawled or scraped. Always check and adhere to these rules to avoid violating a website’s terms of service.
Avoid Overloading Servers
Crawling and scraping can put a significant load on a website’s server, especially if done at scale. It is crucial to implement rate limiting and avoid making too many requests in a short period to prevent disrupting the site’s functionality. Implementing delays between requests can help mitigate this issue.
Data Privacy
Be mindful of the data you collect and ensure that you are not violating any privacy laws or regulations. Handle sensitive information, such as personal data with care and in compliance with relevant laws, such as GDPR. Always anonymize or aggregate data when possible to protect individual privacy.
Attribution
If you use scraped data in your work, consider providing attribution to the source. This practice not only shows respect for the original content creators but also enhances the credibility of your work. Proper attribution can also help build relationships with content providers.
Legal Compliance
Be aware of the legal implications of web scraping in your jurisdiction. Some websites explicitly prohibit scraping in their terms of service, and violating these terms could lead to legal consequences. Always consult legal advice if unsure about the legality of your scraping activities.
Tools for Web Crawling and Scraping
Several tools and frameworks are available for web crawling and scraping, catering to different needs and expertise levels. Here are some popular options:
Web Crawling Tools
Web crawling tools automate the process of extracting data from websites. They can collect information for various purposes, such as market research, SEO analysis, or data mining. Popular tools include:
Scrapy
An open-source web crawling framework that allows users to build spiders for crawling and scraping websites. It is highly customizable and supports various data storage formats. Scrapy is known for its speed and efficiency, making it a popular choice among developers.
Apache Nutch
A powerful web crawler built on Apache Hadoop, suitable for large-scale data crawling projects. It is designed for scalability and can handle vast amounts of data. Nutch is often used in conjunction with other Hadoop tools for big data processing.
Heritrix
An open-source web crawler designed for web archiving. It is often used by libraries and institutions to capture and preserve web content. Heritrix is particularly useful for long-term archiving projects.
Web Scraping Tools
Web scraping tools automate the process of extracting data from websites. These tools, like Beautiful Soup and Scrapy, streamline data collection, making it efficient and scalable for various data-driven tasks.
Beautiful Soup
A Python library for parsing HTML and XML documents. It is commonly used for web scraping due to its simplicity and ease of use. Beautiful Soup allows users to navigate and search through the parse tree, making it easy to extract data from complex HTML structures.
Puppeteer
A Node.js library that provides a high-level API for controlling headless Chrome or Chromium. It is useful for scraping dynamic content rendered by JavaScript. Puppeteer allows users to simulate user interactions, making it ideal for scraping modern web applications.
Octoparse
A user-friendly web scraping tool that allows users to extract data without coding. It features a visual interface for setting up scraping tasks, making it accessible for non-technical users. Octoparse also offers cloud-based scraping capabilities for scalability.
Best Practices for Web Crawling and Scraping
Effective web crawling and scraping requires careful planning and execution. Adhere to ethical guidelines, respect robots.txt files, handle errors gracefully, and optimise your crawler for efficiency. Consider using libraries like Scrapy or Beautiful Soup for efficient data extraction. To ensure successful and ethical web crawling and scraping, consider the following best practices:
Plan Your Strategy
Before starting, define your goals, identify target websites, and determine the specific data you need to collect. A clear plan will help streamline the process and ensure you gather relevant information.
Use Appropriate Tools
Select the right tools and frameworks based on your technical expertise and the complexity of your project. Consider the specific features and capabilities of each tool to find the best fit for your needs.
Implement Rate Limiting
To avoid overloading servers, implement rate limiting to control the frequency of requests made to a website. This practice helps maintain the integrity of the site and prevents potential bans or legal issues.
Monitor for Changes
Websites frequently update their content and structure. Regularly monitor your scraping setup to ensure it continues to function correctly. Implement error handling to manage any changes in the website’s design.
Stay Informed
Keep up to date with the latest developments in web crawling and scraping, including changes in website policies and legal regulations. Engaging with online communities and forums can help you stay informed about best practices and emerging tools.
Document Your Process
Maintain clear documentation of your crawling and scraping processes, including the tools used, the data collected, and any challenges encountered. This documentation can be invaluable for future projects and for sharing knowledge with team members.
Conclusion
Web crawling and web scraping are powerful techniques for gathering and extracting data from the internet. While they share some similarities, they serve distinct purposes and are used in different contexts. Understanding the differences between these two methods is crucial for effectively leveraging them in data-driven projects.
By combining web crawling and scraping, businesses and researchers can gather comprehensive data sets that provide valuable insights and inform decision-making. However, it is essential to approach these practices ethically and responsibly, respecting the rights of content creators and adhering to legal guidelines.
As the digital landscape continues to evolve, the importance of web crawling and scraping will only grow, making it essential for professionals to stay informed about best practices, tools, and ethical considerations in this field.
With the right approach, web crawling and scraping can unlock a wealth of information that drives innovation and enhances understanding across various domains.
Frequently Asked Questions
What is the Primary Difference Between Web Crawling and Web Scraping?
Web crawling involves discovering and indexing web pages, while web scraping focuses on extracting specific data from those pages.
Can Web Crawling and Scraping Be Used Together?
Yes, they are often used together. Crawling is typically the first step to discover URLs, followed by scraping to extract targeted data.
What are Some Common Use Cases for Web Scraping?
Common use cases include price comparison, market research, lead generation, and content aggregation from multiple sources.
Authors
-

Written by:
Versha RawatReviewed by:


