
Summary: Explore the differences between Star Schema and Snowflake Schema in dimensional modelling. Learn how each schema impacts performance, data integrity, and complexity to find the best fit for your data warehousing needs.
Introduction
Dimensional modelling is crucial for organising data to enhance query performance and reporting efficiency. Effective schema design is essential for optimising data retrieval and analysis in data warehousing. This blog explores the “Star Schema vs Snowflake Schema,” two fundamental techniques in dimensional modelling.
We will examine their structures, benefits, and applications, offering insights into which schema best suits different business needs. We aim to help you understand how these schemas impact data warehousing and guide you in selecting the most appropriate design for your organisation’s analytical requirements.
What is Dimensional Modeling?
Dimensional modelling is a design technique used in data warehousing to organise data into structures that simplify reporting and analysis. The primary goal is to make data easily accessible and understandable for users, facilitating efficient querying and data retrieval.
Key concepts:
- Dimensions: These are descriptive attributes related to the data. Examples include time, location, and product categories. Dimensions provide context and allow users to analyse data from different perspectives.
- Facts: Facts represent quantitative data or metrics. They typically include sales figures, revenue, or quantities. Facts are usually stored in fact tables and are the primary focus of analysis.
- Measures: Measures are the actual numerical values users analyse. They result from aggregating facts, including totals, averages, or percentages.
Must Read Blogs:
Exploring the Power of Data Warehouse Functionality.
Data Lakes Vs. Data Warehouse: Its significance and relevance in the data world.
Exploring Differences: Database vs Data Warehouse.
Role in Data Warehousing and Business Intelligence
Dimensional modelling plays a crucial role in data warehousing and business intelligence by structuring data to enhance performance and usability. It allows for intuitive data exploration and reporting, supports complex queries, and enables users to derive meaningful insights quickly. This modelling approach is essential for effective decision-making and strategic planning.
Explore: How Business Intelligence helps in Decision Making.
Understanding Star Schema
The Star Schema is a popular design approach used in data warehousing to organise and optimise data retrieval. This schema features a central fact table connected to multiple-dimension tables, forming a star-like shape.
The fact table holds quantitative data (e.g., sales, revenue) and serves as the primary focus for analysis. Surrounding it are dimension tables that provide context to the data, such as time, product, or customer details.
Components
In a Star Schema, the fact table is the core element, containing measurable data, often called facts. Each record in this table represents a transactional event and includes foreign keys linking to dimension tables. Dimension tables are structured to provide detailed attributes related to the facts.
For instance, a sales fact table might link to dimension tables for products, dates, and stores. These tables are usually denormalised, storing redundant data to simplify queries and enhance performance.
Characteristics and Benefits
One of the primary characteristics of the Star Schema is its simplicity. The straightforward design, with a single fact table surrounded by dimension tables, makes it easy to understand and navigate.
This simplicity translates into high performance, particularly in query execution. Since dimension tables are denormalized, the schema reduces the number of joins required during queries, leading to faster data retrieval and improved response times.
The Star Schema is user-friendly due to its intuitive structure. Analysts and business users can easily comprehend and interact with the schema, which simplifies the process of generating reports and performing data analysis. The clear separation between facts and dimensions helps create straightforward queries and visualisations, making it an ideal choice for business intelligence applications.
Use Cases and Scenarios
The Star Schema is highly effective in scenarios where fast query performance and ease of reporting are crucial. It is commonly used in data warehouses for business analytics and reporting.
For instance, a retail business might employ a Star Schema to analyse sales performance across different regions and periods. The schema supports complex queries and aggregations, making it suitable for operational reporting and ad-hoc analysis.
Star Schema’s design prioritises simplicity and performance, making it advantageous for various data warehousing and business intelligence needs. Its clear structure and ease of use facilitate efficient data analysis and reporting.
Also Read: Must Read Guide: Roadmap to Become a Database Administrator.
Understanding Snowflake Schema

The Snowflake Schema is a sophisticated design used in data warehousing that extends the principles of dimensional modelling. Unlike the Star Schema, it organises data into a more complex, normalised structure.
In this schema, the central fact table is connected to dimension tables, which are further broken down into related tables resembling snowflakes. This normalisation process reduces data redundancy and ensures a more organised data structure.
Components
At the core of the Snowflake Schema lies the fact table, which captures measurable data, such as sales figures or transaction amounts. This fact table links to dimension tables that provide context, such as customer details, product information, and periods.
However, dimension tables are normalised in the Snowflake Schema, meaning they are divided into multiple related tables to minimise redundancy. For example, a product dimension table might be split into separate tables for categories, subcategories, and individual products.
Characteristics and Benefits
One of Snowflake Schema’s main advantages is its reduction in data redundancy. By normalising dimension tables, the schema ensures data is stored efficiently, eliminating duplicate entries and minimising the need for repetitive data storage. This normalisation helps conserve storage space and maintain a cleaner data model.
The Snowflake Schema enhances data integrity through its normalised structure. Organising data into related tables enforces consistency and accuracy across the database.
For instance, if product information is updated in one table, the changes propagate through related tables, ensuring the entire dataset remains accurate and up-to-date. This integrity is crucial for maintaining reliable data across complex analytical processes.
Use Cases and Scenarios
The Snowflake Schema is particularly effective when data integrity and efficient storage are priorities. It is well-suited for environments with large and complex datasets, where normalisation can improve performance and reduce redundancy.
For example, a large financial institution might use a Snowflake Schema to manage intricate data related to transactions, accounts, and financial products. The schema’s ability to handle detailed, normalised data makes it ideal for complex queries and comprehensive reporting.
Know More: Discovering Different Types of Keys in Database Management Systems.
Star Schema vs. Snowflake Schema: Key Differences
When designing a data warehouse, the choice of schema can significantly impact the system’s efficiency, ease of use, and performance. This section explores the critical differences between these schemas, focusing on design complexity, performance considerations, data redundancy, ease of use, and maintenance.
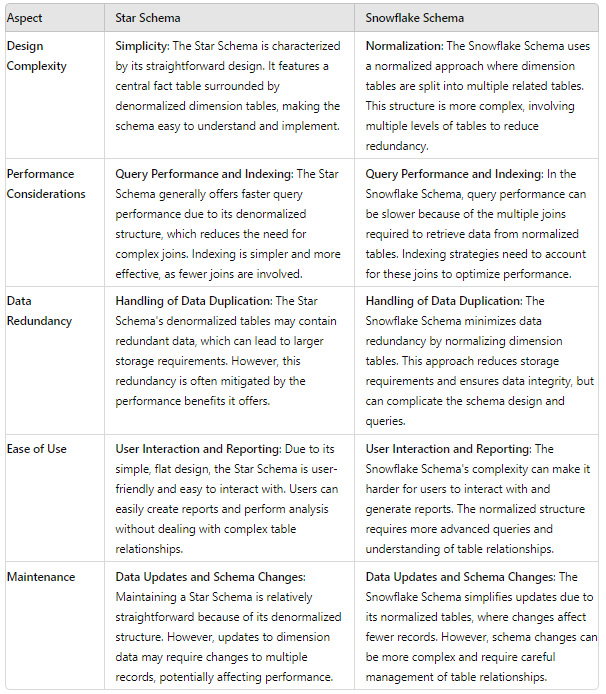
Comparative Analysis
Understanding the advantages and disadvantages of Star Schema and Snowflake Schema is crucial when evaluating them. Both schemas have distinct features that can impact their effectiveness based on various factors, such as data volume, query complexity, and reporting needs.
Star Schema: Pros and Cons
Pros: The Star Schema stands out for its simplicity and speed. Its design features a central fact table connected to denormalised dimension tables, facilitating quicker query performance. The straightforward structure makes it easy for users to comprehend and manage, supporting efficient reporting and faster development cycles.
Cons: However, the denormalised nature of the dimension tables in a Star Schema can lead to data redundancy. This increases storage requirements and raises the risk of data inconsistencies. Additionally, managing updates can be challenging, as any changes to dimension data must be consistently applied across multiple records.
Snowflake Schema: Pros and Cons
Pros: With its normalised dimension tables, the Snowflake Schema excels at reducing data redundancy and improving data integrity. Organising data into related tables minimises anomalies and storage needs, making it an efficient choice for handling large datasets and complex relationships.
Cons: On the downside, the Snowflake Schema introduces query complexity due to its normalised structure requiring more joins. This can impact performance and make query writing more cumbersome. The intricate design may also challenge users, resulting in a steeper learning curve.
Choosing the Right Schema
When choosing between the Star and Snowflake Schemas, several factors come into play:
- Data Volume: The Star Schema’s simplicity may be sufficient for smaller datasets. However, the Snowflake Schema’s efficiency in handling complex data might be more appropriate for large datasets with intricate relationships.
- Query Complexity: If the focus is on straightforward queries and performance, Star Schema’s design supports faster data retrieval. For more complex queries, the Snowflake Schema, despite its complexity, may better handle intricate data relationships.
- Reporting Needs: The Star Schema is advantageous for ease of use and rapid reporting. Conversely, if data integrity and reducing redundancy are priorities, the Snowflake Schema offers a more structured approach.
Explore More: Build Data Pipelines: Comprehensive Step-by-Step Guide.
Examples

Understanding Star Schema’s and Snowflake Schema’s practical applications can provide valuable insights into their effectiveness in real-world scenarios. Both schemas offer unique advantages and are suited to different types of data environments. Here, we explore how these schemas are utilised across various industries.
Real-world Applications of Star Schema
The Star Schema excels in environments where simplicity and speed are critical. For instance, many retail organisations use the Star Schema to analyse sales data. In these setups, a central fact table captures sales transactions.
In contrast, dimension tables provide details such as products, stores, and periods. This design allows for rapid query performance and straightforward reporting. Retail giants like Walmart and Amazon leverage this schema to generate sales reports, track inventory, and analyse customer behaviour effectively.
Another notable application is in financial institutions. Banks and investment firms utilise the Star Schema to manage large volumes of transaction data. For example, a fact table might record transaction amounts, with dimension tables detailing accounts, customers, and periods. This setup facilitates quick access to critical financial metrics, aiding in performance analysis and fraud detection.
Real-world Applications of Snowflake Schema
With its normalised structure, the Snowflake Schema is beneficial in environments where data integrity and efficiency are paramount. One prominent example is healthcare analytics. Hospitals and health systems use the Snowflake Schema to manage complex patient records, and fact tables store medical treatments and patient outcomes.
In contrast, normalised dimension tables capture detailed attributes such as medical conditions, treatments, and healthcare providers. This design reduces data redundancy and ensures accurate reporting on patient care and operational efficiency.
In the telecommunications industry, the Snowflake Schema supports intricate customer data management. Telecommunications companies employ this schema to track service usage, billing information, and customer demographics. By normalising data across multiple tables, companies ensure consistency and reduce duplication, facilitating better decision-making and targeted marketing strategies.
Both schemas play crucial roles in different industries, highlighting their adaptability to various data management needs.
Conclusion
In comparing the Star Schema vs. Snowflake Schema, each has distinct advantages depending on your needs. The Star Schema excels in simplicity and performance and is ideal for straightforward queries and rapid reporting.
On the other hand, the Snowflake Schema offers better data integrity and efficiency for complex datasets. Choosing the proper schema depends on data volume, query complexity, and reporting requirements.
Frequently Asked Questions
What is the Main Difference Between Star Schema and Snowflake Schema?
The Star Schema features a central fact table connected to denormalized dimension tables, simplifying design and enhancing query performance. The Snowflake Schema, in contrast, uses a central fact table with normalised dimension tables, reducing redundancy but making queries more complex due to multiple joins.
Which Schema is Better for Large Datasets, Star Schema or Snowflake Schema?
The Snowflake Schema is more suited for large datasets because its normalised structure minimises data redundancy and ensures data integrity. This is especially beneficial for handling complex relationships and large volumes of data despite potentially increasing query complexity compared to the Star Schema.
How does the Star Schema improve query performance?
The Star Schema enhances query performance using a single fact table with denormalised dimension tables. This design reduces the need for complex joins, leading to faster data retrieval and more straightforward queries. It’s ideal for scenarios requiring quick responses and efficient reporting.
Authors
-

Written by:
Sam WaterstonReviewed by:



