Summary: The SQL CREATE INDEX statement is a powerful tool for improving query performance by creating indexes on frequently searched columns. Indexes enable faster data retrieval, optimize joins, and enhance database efficiency. Learn the syntax, examples, and best practices for creating single-column or multi-column indexes to boost SQL query execution.
Introduction
In the world of databases, query performance is paramount. Slow queries can lead to frustrating user experiences, application bottlenecks, and inefficient resource utilization. One of the most powerful tools in a database administrator’s or developer’s arsenal to combat slow queries is database indexing. At the heart of this mechanism lies the SQL CREATE INDEX statement.
This guide will delve deep into SQL indexes: what they are, why they are crucial for performance, how to create them using SQL CREATE INDEX, the various types available, the associated trade-offs, and best practices for effective implementation.
By the end, you’ll have a solid understanding of how to leverage indexes to significantly speed up your database operations.
Key Takeaways
- Indexes speed up data retrieval by optimizing query execution.
- Create indexes on frequently queried or joined columns.
- Unique indexes ensure data integrity by preventing duplicates.
- Over-indexing can degrade performance; use indexes judiciously.
- Unused indexes should be removed to improve database efficiency.
What is a SQL Index?
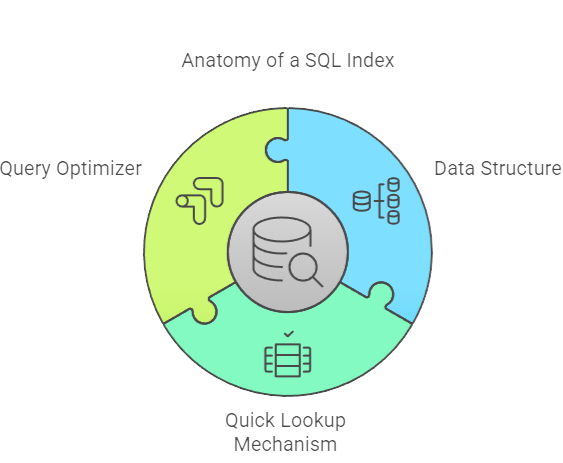
Imagine trying to find a specific topic in a massive textbook without an index at the back. You’d have to flip through potentially hundreds or thousands of pages sequentially – a tedious and time-consuming process. A database index serves a similar purpose for your data tables.
Technically, an index is a separate data structure, often stored on disk, that provides a quick lookup mechanism for finding rows in a table based on the values in one or more columns.
Instead of scanning the entire table (an operation known as a Full Table Scan), the database’s Query Optimizer can use an appropriate index to quickly locate the specific data rows required for a query.
The most common underlying structure for database indexes is a B-Tree (Balanced Tree). This structure allows for efficient searching, insertion, deletion, and sequential access of indexed data, typically performing these operations in logarithmic time complexity (O(log n)), which is significantly faster than the linear time complexity (O(n)) of a Full Table Scan on large tables.
Why Use Indexes?
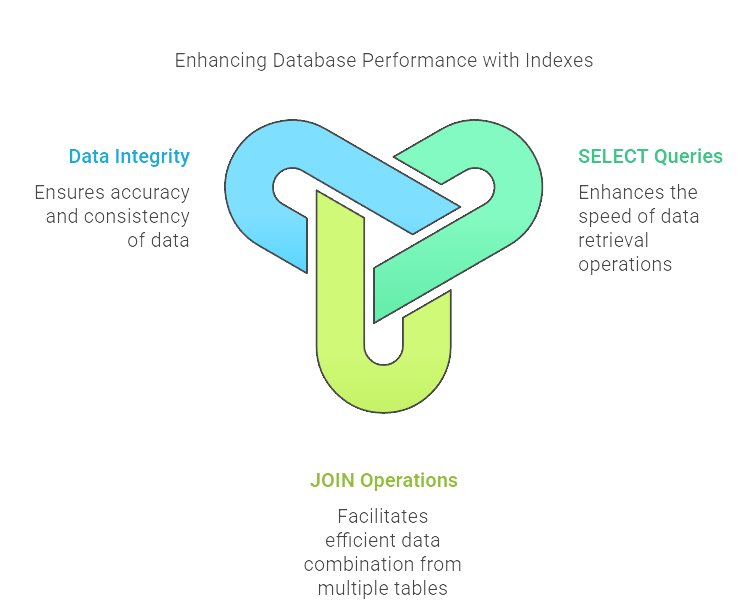
The primary reason to use indexes is to accelerate data retrieval, primarily benefiting SELECT query performance. Here’s how indexes make a difference:
Faster Data Lookups (WHERE Clause)
When you filter data using a WHERE clause on an indexed column, the database can use the index to directly pinpoint the relevant rows. Instead of checking every single row in the table, it navigates the index structure (like the B-Tree) to find pointers to the matching rows.
This operation, often called an Index Seek, is vastly faster than a Full Table Scan, especially on large tables.
Efficient JOIN Operations
Indexes on columns used in JOIN conditions (typically foreign key columns matching primary key columns) are critical. They allow the database to efficiently find matching rows between tables without having to compare every row from one table against every row in the other.
Speeding Up ORDER BY and GROUP BY
If an index exists on the columns used in an ORDER BY clause, the database might be able to retrieve the data in the already sorted order directly from the index, avoiding a costly sorting step. Similarly, indexes can sometimes help optimize GROUP BY operations by allowing the database to easily group related indexed entries together.
Enforcing Uniqueness
Unique Index types not only speed up lookups but also enforce data integrity by ensuring that no two rows have the same value in the indexed column(s). Primary keys usually have a unique index created automatically.
The performance difference can be staggering. A query that takes minutes on an unindexed table might return results in milliseconds once the appropriate indexes are created.
The SQL CREATE INDEX Statement: Syntax and Usage
The fundamental command to create an index in SQL is CREATE INDEX. While the exact syntax can have minor variations between different database systems (like PostgreSQL, MySQL, SQL Server, Oracle), the core structure is generally consistent:

Let’s break down the components:
- CREATE INDEX: The SQL keyword combination that initiates index creation.
- [UNIQUE]: An optional keyword. If specified, it creates a Unique Index, which prevents duplicate values in the specified column(s) across different rows. Attempting to insert or update data that violates this uniqueness constraint will result in an error.
- [TYPE]: Optional and vendor-specific. For example, SQL Server uses CLUSTERED or NONCLUSTERED here. Other databases might specify index types like HASH, GIN, GiST (PostgreSQL) using different syntax (e.g., USING method). We’ll discuss common types shortly.
- index_name: The name you assign to the index. Choose a descriptive name, often indicating the table and the column(s) indexed (e.g., idx_customers_email, ix_orders_customerid_orderdate). Naming conventions are important for maintainability.
- ON table_name: Specifies the table on which the index is being created.
- (column1 [ASC | DESC], column2 [ASC | DESC], …): Specifies the column(s) to be included in the index.
- You can create a single-column index or a Composite Index (multi-column index) by listing multiple columns.
- The order of columns in a Composite Index is crucial (more on this later).
- ASC (Ascending, default) or DESC (Descending) specifies the sort order for the column within the index. This can be important for optimizing ORDER BY clauses that match the index’s sort order.
Example:

Common Types of SQL Indexes
Databases offer various index types, each suited for different scenarios:
Clustered vs. Non-Clustered Indexes
Clustered Index
This index defines the physical storage order of the rows in the table based on the indexed column(s). Because the data rows themselves are sorted and stored according to the clustered index key, there can be only one clustered index per table.
Often, the primary key is implemented as the clustered index by default. Think of it like a telephone directory physically sorted by last name. Lookups on the clustered index key are very fast.
Non-Clustered Index
This index is a separate structure from the data rows. It contains the indexed column values and a pointer (like a row identifier or the clustered index key) back to the actual data row in the table. You can have multiple non-clustered indexes per table.
Think of this like the index at the back of a book – it points you to the page number (the data row location), but the book itself isn’t physically sorted according to that index. Most indexes you create manually will be non-clustered.
Single-Column vs. Composite Indexes
Single-Column Index
An index created on just one column. Useful for queries filtering or sorting on that specific column.
Composite Index (Multi-Column Index)
An index created on two or more columns. Extremely useful for queries that filter or sort on multiple columns simultaneously.
The order of columns in a composite index matters significantly. An index on (colA, colB) can efficiently serve queries filtering on colA alone, or on both colA and colB. However, it’s generally less effective or ineffective for queries filtering only on colB.
Best Practices for Effective Database Indexing
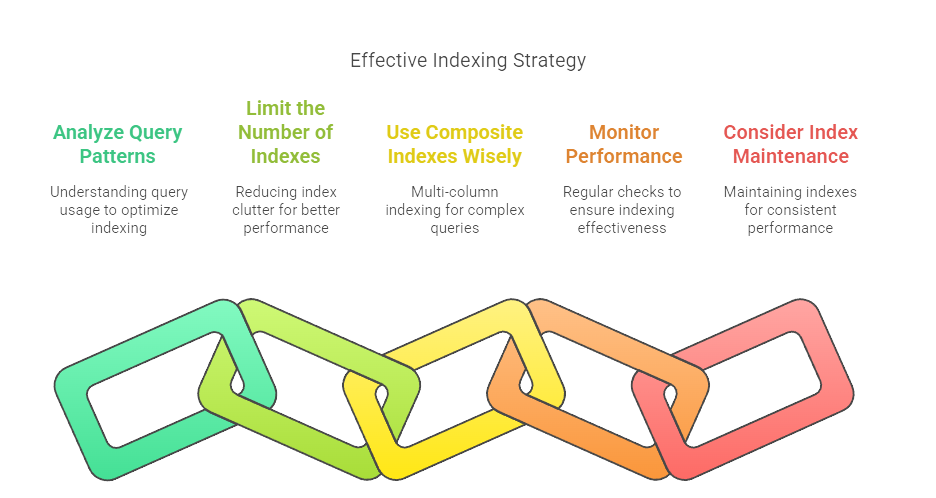
Achieving optimal performance through indexing requires a thoughtful approach. This section highlights the best practices that ensures effective indexing of database:
Analyse Your Workload
Don’t guess! Use database-specific tools to identify slow queries and understand their Execution Plan. Tools like EXPLAIN (PostgreSQL, MySQL), EXPLAIN PLAN (Oracle), or viewing Actual Execution Plans (SQL Server) show how the database is accessing data and whether it’s using indexes effectively.
Index Foreign Keys
It’s almost always a good practice to index foreign key columns, as they are frequently used in JOIN operation. Some database systems do this automatically, but verify.
Monitor Index Usage
Periodically review which indexes are actually being used by the Query Optimizer. Most database systems provide views or functions to track index usage statistics. Unused indexes are prime candidates for removal.
Perform Index Maintenance
Regularly check for index fragmentation and perform reorganization or rebuilding tasks as needed to keep indexes efficient. The frequency depends on how volatile the table data is.
Test Thoroughly
Before adding an index in production, test its impact in a development or staging environment. Measure query performance before and after adding the index to confirm the benefit and ensure no negative side effects on other queries or write operations.
Don’t Forget DROP INDEX
If an index is no longer needed, is redundant, or is negatively impacting performance, remove it using the DROP INDEX command.
Conclusion
Database Indexing is a fundamental concept for achieving high query performance in SQL databases. The SQL CREATE INDEX statement is the key to unlocking this potential, allowing you to build structures that enable rapid data retrieval.
However, indexing is a balancing act. While indexes dramatically speed up SELECT query operations (especially those involving WHERE clause filtering, JOIN operation, and ORDER BY clauses), they introduce overhead for write operations (INSERT, UPDATE, DELETE) and consume Storage Space.
Frequently Asked Questions
What Is the Purpose of the SQL CREATE INDEX Statement?
The CREATE INDEX statement creates an index on table columns to improve query performance by speeding up data retrieval operations. It is particularly useful for frequently queried columns or those used in joins, enabling faster searches and optimized database efficiency.
How Does a Unique Index Differ from a Regular Index?
A unique index ensures that all values in the indexed column are unique, preventing duplicate entries while maintaining data integrity. Regular indexes allow duplicate values but focus solely on improving query speed and efficiency.
What are the Best Practices for Creating Indexes In SQL?
Create indexes based on query patterns, focusing on frequently searched columns or those used in joins. Use multi-column indexes for combined queries and avoid over-indexing as it can slow down updates and increase storage requirements
Authors
-

Written by:
Neha SinghReviewed by: