
Summary: This article explores how Machine Learning (ML) can predict insurance premiums based on customer data. It also discusses Natural Language Processing (NLP) advancements and how AI is becoming better at understanding spoken language and facial recognition
Background
Data has always played a central role in the insurance industry; today, insurance carriers have access to more than ever. We have created more data in the past five years than the human race has ever created.
Insurers—like organisations in most industries—are overwhelmed by the explosion in data from various sources, including telematics, online and social media activity, voice analytics, connected sensors and wearable devices.
They need machines to process this information and unearth analytical insights. However, most insurers are struggling to maximise the benefits of Machine Learning.
This situation is seeing a gradual but steady change, driven by an environment characterised by increased competition, elastic marketplaces, complex claims and fraud behaviour, higher customer expectations and tighter regulation.
Insurers are being forced to explore ways to use predictive modelling and Machine Learning to maintain their competitive edge, boost business operations and enhance customer satisfaction.
Key Factors Driving this Change
Enterprises want to use advanced Machine Learning to drive smart, automated applications in healthcare diagnosis, predictive maintenance, customer service, and automated data centres.
Open Source
As data becomes omnipresent, open-source protocols will emerge to ensure data is shared and used. Different public and private entities will create ecosystems for sharing data on multiple use cases under a common regulatory and cybersecurity framework.
Harnessing the Internet of Things (IoT) Data
The volume and velocity of data from IoT will drive the need to automate the generation of actionable insight using advanced Machine Learning tools.
According to Gartner, by 2025, 55 per cent of enterprises will employ dedicated people to monitor and guide Machine Learning (such as neural networks). The notion of training rather than programming systems will become increasingly important.
NLP Algorithms on the Rise
Natural Language Processing algorithms are continuously advancing. AI is becoming proficient at understanding spoken language and facial recognition, helping to make it more useful and intuitive.
These algorithms are evolving unexpectedly, as Google found when Google Translate invented its language to help it translate more effectively.
Case Study
The myriad opportunities in the insurance sector, especially health insurance, motivated me to undertake this capstone project. Health has taken a back seat in this ever-advancing world, but the pandemic has made us realise its importance.
Access to healthcare is still a challenge, primarily due to the high costs associated with it. Insurance is the most important factor in improving individuals’ healthcare access.
Given their characteristics, I wish to predict the insurance premium charges of an insuree. Their characteristics include
Age
BMI
Biological Sex
Smoker
Region
Exploratory data analysis yielded excellent insights into the data.
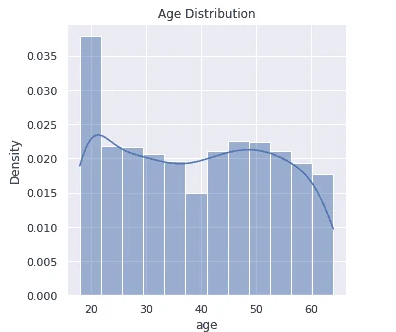
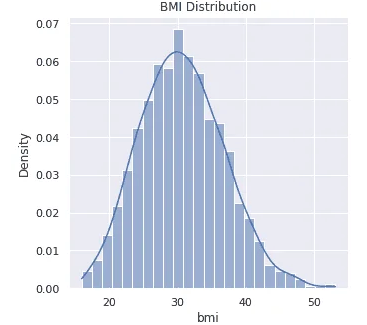
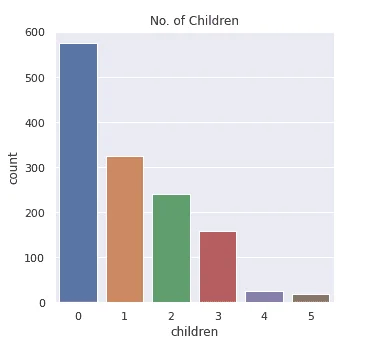
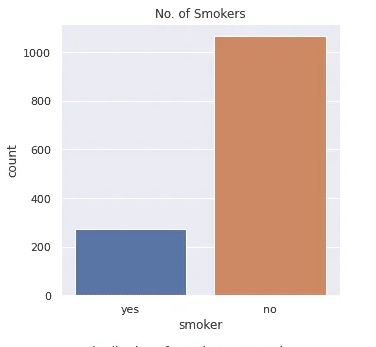
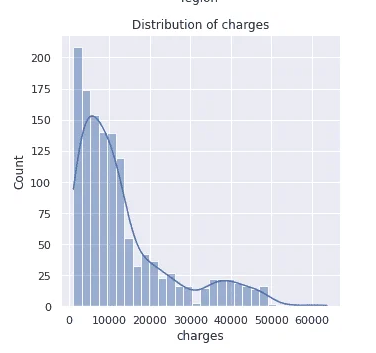
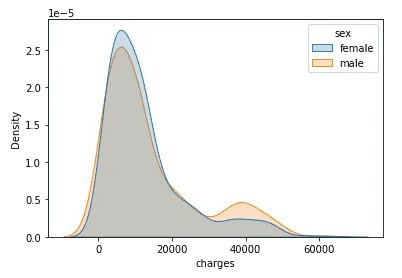
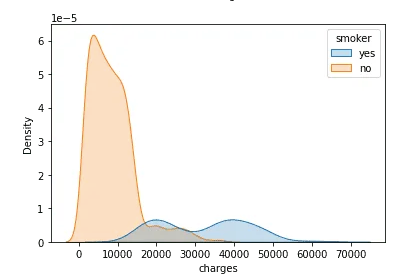
The data had no NULL values, an important factor in data quality. Each of the independent data features had no outliers, and data wrangling was successfully performed.
Modelling
I applied a regression algorithm to predict insurance charges for the insurees. After applying regression to the data set, the prediction was successful with an R-squared value of 0.7488.
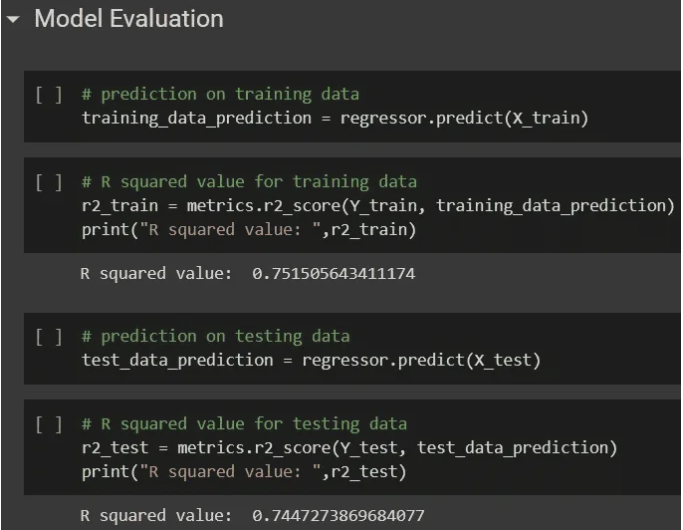
Scope for Improvement
One could use other machine learning algorithms to improve the accuracy and fine-tuning of the model. A linear regression model’s performance could be improved by using:
Adding interaction terms to model how two or more independent variables together impact the target variable.
Polynomial terms addition to model the nonlinear relationship between an independent variable and the target variable.
Adding spines to approximate piecewise linear models.
Fitting isotonic regression to remove any assumption of the target function form.
One could also use non-linear ML algorithms like regression trees to improve performance.
Challenges Insurers Typically Encounter When Adopting Machine Learning
Training requirements
AI-powered intellectual systems must be trained in a domain, e.g., claims or billing for an insurer. This requires a separate training system, which insurers find difficult to provide for AI model training. Models need to be trained with huge volumes of documents/transactions to cover all possible scenarios.
Right Data Source
The quality of data used to train predictive models is equally important as the quantity in the case of Machine Learning. The datasets need to be representative and balanced so that they can give a better picture and avoid bias. This is important to train predictive models. Generally, insurers struggle to provide relevant data for training AI models.
Difficulty in Predicting Returns
It’s difficult to predict improvements that Machine Learning can bring to a project. For example, it’s not easy to plan or budget a project using Machine Learning, as the funding needs may vary during the project based on the findings.
Therefore, it is almost impossible to predict the return on investment. This makes it hard to get everyone on board the concept and invest in it.
Data security
The huge amount of data used for Machine Learning algorithms has created an additional security risk for insurance companies. With such an increase in collected data and connectivity among applications, there is a risk of data leaks and security breaches. A security incident could lead to personal information falling into the wrong hands. This creates fear in the minds of insurers.
Frequently Asked Questions
Can Machine Learning Really Predict my Insurance Cost?
Yes, ML algorithms can analyze factors like age, health, and location to estimate insurance premiums. However, these are just estimates, and your actual cost might vary.
Is My Data Safe When Using AI-powered Insurance?
Data security is a concern with AI. Insurers need robust measures to protect sensitive customer information from leaks or breaches.
What Are The Benefits of NLP in Insurance?
NLP helps AI understand customer requests and documents. This can streamline tasks like processing claims and improve communication between insurers and clients.
Conclusion
Machine Learning offers a powerful tool for insurance companies to improve their operations and customer satisfaction. By leveraging advanced algorithms, insurers can gain valuable insights from vast amounts of data, leading to more accurate premium pricing, efficient claims processing, and better fraud detection.
However, challenges such as training requirements, data quality, and security concerns need to be addressed for successful ML adoption. As the technology matures and these hurdles are overcome, Machine Learning will undoubtedly play a transformative role in the future of insurance.
Authors
-

Written by:
Shlok KamatReviewed by:



