
Summary: The Perceptron is a simple artificial neuron used for binary classification in Machine Learning. It processes multiple inputs, applies weights, and produces an output based on an activation function. Despite its limitations, the Perceptron laid the groundwork for more complex neural networks and Deep Learning advancements.
Introduction
The Perceptron is one of the foundational concepts in Artificial Intelligence and Machine Learning. Developed in the late 1950s by Frank Rosenblatt, the Perceptron serves as a simple model of a biological neuron and is primarily used for binary classification tasks.
It represents the earliest form of neural networks and has paved the way for more complex architectures in Deep Learning. This blog will explore the basics of the Perceptron, the mathematics behind it, how it is trained, its applications, limitations, and advancements beyond the Perceptron model.
Read More:
- Learn Top 10 Deep Learning Algorithms in Machine Learning
- Top 10 Fascinating Applications of Deep Learning You Should Know
Basics of the Perceptron
At its core, a Perceptron is a type of artificial neuron that takes multiple inputs, applies weights to them, and produces a single output. The Perceptron model consists of several key components:
Inputs
These are the features or data points fed into the Perceptron. Each input corresponds to a specific feature of the data.
Weights
Each input is associated with a weight that indicates its importance in the decision-making process. Weights are adjusted during the training phase to minimise errors in predictions.
Bias
The bias is an additional parameter that allows the model to shift the activation function. It helps the Perceptron make better predictions by providing flexibility in the decision boundary.
Activation Function
The Perceptron uses an activation function to determine the output based on the weighted sum of the inputs and the bias. The most common activation function used in a Perceptron is the step function, which produces a binary output (0 or 1).
Output
The final output of the Perceptron is a binary classification indicating which class the input belongs to.
The Perceptron classifies data into one of two categories, so it functions as a binary classifier. For example, it can be used to determine whether an email is spam or not based on various features extracted from the email content.
The Mathematics Behind the Perceptron
The Perceptron operates based on a straightforward mathematical framework. The output of a Perceptron can be expressed mathematically as follows:
Weighted Sum: The Perceptron calculates the weighted sum of the inputs:
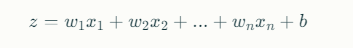
Here, wiwi represents the weight associated with the ithith input xixi, and bb is the bias.
Activation Function: The weighted sum zz is then passed through an activation function to produce the final output:
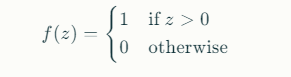
This step function determines whether the Perceptron “fires” (outputs 1) or not (outputs 0).
The Perceptron learning algorithm adjusts the weights and bias based on the errors made during predictions. When the Perceptron incorrectly classifies an input, you update the weights using the following rule:
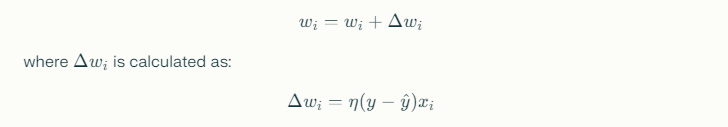
Here, ηη is the learning rate, yy is the true label, and y^y^ is the predicted label. This update rule ensures that the Perceptron learns from its mistakes and improves its predictions over time.
Training a Perceptron
Training a Perceptron involves a supervised learning process where the model learns from labelled training data. The training process can be summarised in the following steps:
Step 1: Initialisation: Start with random weights and a bias. Initialize the weights with small random values and set the bias to zero or a small constant.
Step 2: Feedforward: First, compute the output for each training example by calculating the weighted sum. Then apply the activation function to this sum. This process ensures that you obtain the final output for each example.
Step 3: Error Calculation: Compare the predicted output with the actual label to determine if there is an error.
Step 4: Weight Update: If the prediction is incorrect, update the weights and bias using the learning rule mentioned earlier. This step is repeated for each training example.
Step 5: Iteration: The process is repeated for multiple epochs (iterations over the entire training dataset) until the Perceptron converges, meaning the weights stabilise, and the error rate is minimised.
The Perceptron learning algorithm is efficient for linearly separable data, where a straight line (or hyperplane in higher dimensions) can separate the classes. However, if the data is not linearly separable, the Perceptron may fail to converge.
Applications and Limitations of the Perceptron
The Perceptron, a foundational model in Artificial Intelligence and Machine Learning, has a wide range of applications across various domains. Here are some key applications of the Perceptron based on the search results:
Image Recognition
Basic image recognition tasks use the Perceptron to classify images based on pixel values. It serves as a fundamental building block for more complex neural networks that handle image data.
Natural Language Processing (NLP)
In NLP, you can employ Perceptrons for tasks like sentiment analysis and text classification. They help in determining the sentiment of a given text or categorising documents into predefined categories.
Speech Recognition
It contributes to speech recognition systems by classifying audio signals and recognizing spoken words, enabling voice-activated applications and devices.
Logic Gates Implementation
The Perceptron can model basic logic gates like AND, OR, and NOT, making it useful for educational purposes and in the design of simple digital circuits.
Data Compression and Visualisation
Perceptrons help detect features and patterns in datasets for data compression techniques and visualization tasks, which aids in interpreting complex data.
Business Intelligence
It helps in deriving insights from input data, allowing businesses to make data-driven decisions by classifying and analysing data points.
Binary Classification
As a linear classifier, the Perceptron mainly handles binary classification tasks by distinguishing between two classes based on input features.
Limitations of Perceptron
While the Perceptron laid the groundwork for neural networks, it has several limitations. These limitations of the Perceptron model have led to the development of more advanced neural network architectures like multi-layer Perceptrons (MLPs) and Deep Learning models, which overcome many of the Perceptron’s shortcomings.
Binary Output
The output of a Perceptron can only be a binary number (0 or 1) due to the hard-limit transfer function. It cannot produce continuous or probabilistic outputs.
Linear Separability
It can only classify linearly separable sets of input vectors. If the input vectors are not linearly separable, the Perceptron may not be able to classify them correctly. A single Perceptron cannot solve non-linearly separable problems like the XOR function.
Sensitivity to Feature Scaling
Perceptrons are sensitive to the scaling of input features. If the features have different scales or units, the algorithm may converge slowly or fail to converge altogether. This is because the weight updates depend on the magnitudes of the input features, and large differences in scale can cause large weight updates to go in the wrong direction.
Limited Representational Power
The Perceptron algorithm only learns linear decision boundaries and lacks the flexibility to handle complex, non-linear problems. More advanced classifiers like support vector machines and neural networks have greater representational power and can learn non-linear decision boundaries.
No Probabilistic Output
It does not provide probabilistic output, meaning they cannot estimate the uncertainty or confidence of their predictions. This can be a disadvantage in applications where it is important to know the level of confidence in the predictions.
Advancing Beyond the Perceptron
To overcome the limitations of the Perceptron, researchers developed more advanced neural network architectures. One of the most significant advancements is the multi-layer Perceptron (MLP) or ReLU (Rectified Linear Unit).
Multi-Layer Perceptrons (MLPs)
MLPs consist of an input layer, one or more hidden layers, and an output layer. Each neuron in a layer connects to every neuron in the subsequent layer, enabling greater complexity in learning. The backpropagation algorithm typically trains MLPs by adjusting the weights based on the error gradient.
Deep Learning
The advent of Deep Learning has further advanced the capabilities of neural networks. Deep Learning models, which consist of many layers of neurons, can automatically learn hierarchical features from raw data. This has led to breakthroughs in various fields, including computer vision, natural language processing, and speech recognition.
Conclusion
The Perceptron is a foundational model in the field of Artificial Intelligence and Machine Learning. Its simplicity and effectiveness in binary classification tasks have made it a crucial stepping stone for understanding more complex neural network architectures.
While the Perceptron has its limitations, advancements such as multi-layer Perceptrons and Deep Learning have expanded its capabilities and applications.
As the field of Machine Learning continues to evolve, the principles established by the Perceptron remain relevant, providing insights into the workings of modern neural networks. Understanding the Perceptron is essential for anyone looking to delve into the world of Artificial Intelligence and Machine Learning.
Frequently Asked Questions
What is a Perceptron?
A Perceptron is a simple artificial neuron that performs binary classification tasks in Machine Learning. It takes multiple inputs, applies weights, and produces a binary output based on an activation function.
What are the limitations of the Perceptron?
The Perceptron can only classify linearly separable data, operates with a single layer, produces binary outputs, and responds sensitively to the choice of learning rate.
How does the Perceptron differ from multi-layer Perceptrons (MLPs)?
The Perceptron is a single-layer model that can only learn linear relationships, while multi-layer Perceptrons consist of multiple layers of neurons, allowing them to learn complex, non-linear patterns in data.
Authors
-

Written by:
Julie BowieReviewed by:


