
Summary: This article delves into the role of optimizers in deep learning, explaining different types such as SGD, Adam, and RMSprop. It highlights their mechanisms, advantages, and practical applications in training neural networks. Understanding these optimizers is crucial for improving model performance and achieving efficient learning outcomes in AI tasks.
Introduction
Deep Learning has revolutionized the field of artificial intelligence by enabling machines to learn from vast amounts of data. At the heart of this learning process lies an essential component known as the optimizer.
Optimizers are algorithms that adjust the parameters of a neural network to minimize the loss function, thereby improving the model’s performance. This blog post will delve into various types of optimizers, their mechanisms, advantages, and practical examples.
Key Takeaways
- Optimizers adjust neural network parameters to minimize loss functions effectively.
- Different optimizers suit various tasks and dataset characteristics.
- Adam combines the benefits of Momentum and RMSprop for efficient training.
- Stochastic Gradient Descent accelerates convergence with random sample updates.
- Experimentation with optimizers is essential for optimal model performance.
What is an Optimizer?
An optimizer in Deep Learning is a method or algorithm used to update the weights and biases of a neural network during training. The primary goal of an optimizer is to minimize the loss function, which quantifies how well the model’s predictions match the actual outcomes.
By iteratively adjusting the model parameters based on computed gradients, optimizers facilitate the learning process.
The Role of Loss Functions
Before diving into optimizers, it’s crucial to understand loss functions. The loss function measures how well a model performs on a given dataset. Common loss functions include Mean Squared Error (MSE) for regression tasks and Cross-Entropy Loss for classification tasks. The optimizer uses the gradients derived from these loss functions to make informed updates to the model parameters.
Types of Optimizers
There are several optimizers used in Deep Learning, each with its unique characteristics and applications. Below are some of the most commonly used optimizers:
Gradient Descent
Gradient Descent is the most basic optimization algorithm used in Machine Learning. It updates the parameters by moving them in the direction of the negative gradient of the loss function with respect to those parameters.
Update Rule
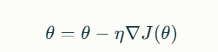
where θθ represents the parameters, ηη is the learning rate, and J(θ)J(θ) is the loss function.
Example: In a simple linear regression problem, Gradient Descent can be used to find the optimal slope and intercept that minimize prediction errors.
Stochastic Gradient Descent (SGD)
Stochastic Gradient Descent improves upon traditional Gradient Descent by updating parameters using only one sample at a time instead of using the entire dataset.
Advantages
- Faster convergence
- Better generalization due to noise introduced by random sampling
Example: SGD is widely used in training deep neural networks where datasets are too large to fit into memory.
Mini-Batch Gradient Descent
Mini-Batch Gradient Descent combines the advantages of both Gradient Descent and Stochastic Gradient Descent by using a small batch of samples for each update.
Advantages
- Reduces variance in parameter updates
- Takes advantage of vectorization for faster computation
Example: This method is commonly used in training Convolutional Neural Networks (CNNs) for image classification tasks.
Momentum
Momentum is an enhancement over SGD that helps accelerate gradients vectors in the right directions, thus leading to faster converging.
Update Rule
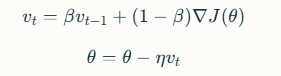
where vtvt is the velocity, and ββ is a hyperparameter that determines how much momentum to retain.
Example: Momentum is particularly useful in navigating ravines in error surfaces, common in Deep Learning models.
Nesterov Accelerated Gradient (NAG)
NAG is a variation of Momentum that looks ahead at where the parameters will be after applying momentum and computes gradient updates accordingly.
Advantages
- More responsive to changes in gradients
- Can lead to faster convergence
Example: NAG is effective in training deep networks with complex architectures.
Adagrad
Adagrad adapts the learning rate for each parameter based on historical gradients, allowing for larger updates for infrequent features and smaller updates for frequent features.
Update Rule:
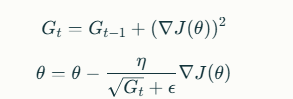
Example: Adagrad works well for sparse data scenarios, such as text classification tasks using bag-of-words representations.
RMSprop
RMSprop addresses Adagrad’s diminishing learning rates by using an exponentially decaying average of squared gradients.
Advantages
- Maintains a more constant learning rate
- Works well in non-stationary settings
Example: RMSprop is often used in recurrent neural networks (RNNs) due to its ability to handle sequences effectively.
Adam (Adaptive Moment Estimation)
Adam combines ideas from Momentum and RMSprop. It maintains two moving averages—one for gradients and another for squared gradients—allowing it to adaptively adjust learning rates for each parameter.
Update Rule:
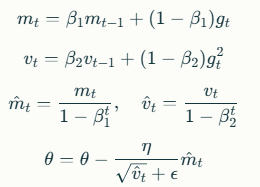
where gt=∇J(θ)gt=∇J(θ).
Example: Adam is widely regarded as one of the best optimizers for various tasks due to its efficiency and ease of use across different types of neural networks.
Choosing an Optimizer
Selecting an appropriate optimizer can significantly impact model performance. Factors influencing this choice include:
- The nature of the dataset (e.g., size, sparsity)
- The architecture of the neural network
- The specific task at hand (e.g., classification vs. regression)
It’s often beneficial to experiment with different optimizers and tune their hyperparameters, such as learning rates, to identify which yields optimal results for your particular problem.
Conclusion
Optimizers play a critical role in training Deep Learning models by adjusting parameters iteratively based on computed gradients. Understanding various optimizers—such as SGD, Adam, and RMSprop—enables practitioners to select suitable algorithms tailored to their specific needs.
As Deep Learning continues to evolve, staying informed about advancements in optimization techniques will be essential for developing efficient AI systems.
Frequently Asked Questions
How Do Optimizers Work in Deep Learning?
Optimizers adjust a neural network’s parameters iteratively during training by minimizing a loss function through gradient descent methods. They utilize computed gradients from backpropagation to determine parameter updates efficiently, significantly speeding up training processes compared to unoptimized methods.
What Factors Should I Consider When Choosing an Optimizer?
When selecting an optimizer, consider factors like your dataset’s size and characteristics, model architecture complexity, specific task requirements, and computational resources available. Experimentation with different optimizers can also help identify which performs best for your application.
Why Is Adam Considered One of The Best Optimizers?
Adam combines benefits from both Momentum and RMSprop optimizers by maintaining adaptive learning rates based on past gradient information. This allows it to converge quickly while handling various types of data effectively, making it suitable for many Deep Learning applications.
Authors
-

Written by:
Aashi VermaReviewed by:



