
Summary: Naive Bayes classifiers are a family of probabilistic models based on Bayes’ theorem, widely used for classification tasks. They assume that features are conditionally independent given the class label, which simplifies computations. Common applications include text classification, spam detection, and sentiment analysis due to their speed and effectiveness with large datasets.
Introduction
Naive Bayes is a powerful and widely used classification algorithm in Machine Learning, particularly known for its simplicity and effectiveness. It operates on the principle of Bayes’ theorem, which relates the conditional and marginal probabilities of random events.
Naive Bayes classifiers are employed in numerous practical scenarios. For instance, email services use to filter spam messages by analyzing the frequency of certain words. If an email contains terms like “free,” “winner,” or “click here,” it might be classified as spam based on learned probabilities.
Another example is in sentiment analysis, It can determine whether a customer review is positive or negative by evaluating the presence of specific words or phrases.
In healthcare, It can predict whether a patient has a particular disease based on symptoms and medical history. For example, it can analyze symptoms like fever, cough, and fatigue to classify whether a patient might have the flu.
These examples highlight how it provides quick and efficient solutions across various domains.
Key Takeaways
- Naive Bayes classifiers are based on Bayes’ theorem for efficient classification.
- They assume feature independence, simplifying calculations in models.
- Common applications include text classification and spam filtering.
- Despite assumptions, they perform well in many real-world scenarios.
- Naive Bayes is fast, making it suitable for large datasets.
What is Naive Bayes?
Naive Bayes is a family of probabilistic algorithms based on applying Bayes’ theorem with strong (naive) independence assumptions between the features. In simpler terms, it assumes that the presence of a particular feature in a class is independent of other features.
Despite this assumption being unrealistic in many real-world situations, It often performs surprisingly well.
The algorithm is particularly useful for large datasets because it requires only a small amount of training data to estimate the parameters necessary for classification.
How Does Naive Bayes Work?
At the core of Naive Bayes is Bayes’ theorem, which describes the probability of an event based on prior knowledge of conditions related to the event. The formula for Bayes’ theorem is:
P(Y∣X)=P(X∣Y)⋅P(Y)P(X)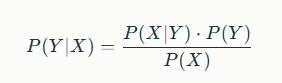
Where:
- P(Y∣X)P(Y∣X) is the posterior probability: the probability of class YY given the feature XX.
- P(X∣Y)P(X∣Y) is the likelihood: the probability of feature XX given class YY.
- P(Y)P(Y) is the prior probability: the initial probability of class YY.
- P(X)P(X) is the evidence: the total probability of feature XX.
In practice, calculating P(X∣Y)P(X∣Y) and P(Y)P(Y) from training data allows us to predict classes for new instances.
The Naive Assumption
The “naive” aspect of Naive Bayes comes from its assumption that all features are independent given the class label. This means that knowing one feature does not provide any information about another feature.
For example, if we are predicting whether an email is spam based on words present in it, the algorithm assumes that each word’s presence contributes independently to the probability of it being spam.
Steps in Naive Bayes Classification
classification is a straightforward yet powerful technique based on Bayes’ Theorem. It is particularly effective for large datasets and is widely used in applications like text classification. Here are the key steps involved in the Naive Bayes classification process:
Step 1: Training Phase
- Collect training data with features and corresponding class labels.
- Calculate prior probabilities for each class based on their frequency in the dataset.
- For each feature, calculate likelihood probabilities (conditional probabilities) based on their
- occurrences within each class.
Step 2: Prediction Phase
- For a new instance to classify, calculate posterior probabilities for each class using Bayes’ theorem.
- Since P(X)P(X) remains constant across classes during classification, it can be ignored when comparing probabilities.
- The class with the highest posterior probability is selected as the predicted class.
Example: Email Spam Classification
To illustrate how Naive Bayes works, consider a simple example where we classify emails as either “Spam” or “Not Spam.” Suppose we have the following training data:
- Spam emails contain words like “free,” “win,” and “money.”
- Not Spam emails contain words like “meeting,” “schedule,” and “project.”
Calculate Prior Probabilities
If out of 100 emails, 40 are spam and 60 are not spam:
P(Not\Spam)=\frac{60}{100}=0.6
Calculate Likelihoods
If “free” appears in 30 spam emails and 5 not spam emails:
- P(free|Spam)=\frac{30}{40}=0.75
- P(free|Not\Spam)=\frac{5}{60}=0.083
Make Predictions
For an incoming email containing the word “free”
Calculate posterior probabilities:
- P(Spam|free)\propto P(free|Spam)\cdot P(Spam)=0.75\cdot 0.4=0.3
- P(Not\Spam|free)\propto P(free|Not\Spam)\cdot P(Not\Spam)=0.083\cdot 0.6=0.05
- Since P(Spam|free)>P(Not\Spam|free), the email is classified as Spam.
Types of Naive Bayes Classifiers
Naive Bayes classifiers are a family of probabilistic classifiers based on Bayes’ theorem, which assumes that the presence of a particular feature in a class is independent of the presence of any other feature.
This assumption simplifies the computation and makes the algorithm efficient for classification tasks. There are three primary types of classifiers, each suited for different types of data:
Multinomial Naive Bayes Classifier
This classifier is used primarily for document classification tasks where the features represent the frequencies of words in a document. It assumes that the features follow a multinomial distribution.
Example
A common application is in text classification, such as categorizing emails as “spam” or “not spam.” In this case, the features could be the counts of each word in the email.
Bernoulli Naive Bayes Classifier
The Bernoulli Naive Bayes classifier is similar to the multinomial model but works with binary/boolean features. It assumes that each feature is independent and indicates whether a word occurs in a document (1) or not (0).
Example
This model is also used in text classification, particularly when dealing with binary occurrences of terms, such as determining if an email contains specific keywords that classify it as spam.
Gaussian Naive Bayes Classifier
This classifier is used when the features are continuous and assumes that these features follow a Gaussian (normal) distribution. It calculates probabilities based on the mean and variance of the features.
Example
An application could be in medical diagnosis, where attributes like blood pressure or cholesterol levels are continuous variables used to classify patients into categories such as “healthy” or “at risk” based on their measurements
Conclusion
Naive Bayes classifiers provide an effective means for solving classification problems across various domains due to their simplicity and efficiency in handling large datasets. While they operate under strong independence assumptions that may not always hold true in practice, they frequently deliver accurate results in applications such as spam filtering, sentiment analysis, and medical diagnosis.
Frequently Asked Questions
What is the Main Principle Behind Naive Bayes?
Naive Bayes operates on Bayes’ theorem and assumes that all features are independent given the class label, allowing for efficient probability calculations for classification tasks.
In What Scenarios Is Naive Bayes Most Effective?
Naive Bayes excels in text classification tasks such as spam detection and sentiment analysis due to its ability to handle high-dimensional data efficiently while providing quick predictions.
What are Some Limitations of Using Naive Bayes?
The primary limitations include its assumption of feature independence and potential inaccuracies when encountering unseen feature values during prediction unless techniques like Laplace smoothing are applied.
Authors
-

Written by:
Neha SinghReviewed by:



