
Summary: Maximum Likelihood Estimation (MLE) is a statistical method used to estimate the parameters of a model by maximizing the likelihood function, which measures how well the model explains the observed data. MLE is widely applicable in various fields, including economics, finance, and Machine Learning, providing efficient and consistent parameter estimates.
Introduction
Maximum Likelihood Estimation (MLE) is a cornerstone of statistical inference, widely used across various fields such as economics, biology, and Machine Learning.
It provides a systematic approach to estimate the parameters of a statistical model by maximizing the likelihood function, which quantifies how well a model explains the observed data. This blog will delve into the intricacies of MLE, exploring its definition, significance, application, and challenges.
Key Takeaways
- MLE maximizes the likelihood function to estimate model parameters.
- It provides efficient and consistent estimates as sample size increases.
- MLE is applicable in diverse fields like finance and biology.
- Correct model specification is crucial for accurate MLE results.
- MLE can be sensitive to outliers and model assumptions.
What is Maximum Likelihood Estimation?
Maximum Likelihood Estimation is a statistical method for estimating the parameters of a probability distribution or model. The fundamental principle behind MLE is to find the parameter values that maximize the likelihood of observing the given sample data under the assumed statistical model. In simpler terms, it identifies the parameters that make the observed data most probable.
For instance, if we assume that our data follows a normal distribution with unknown mean (μμ) and variance (σ2σ2), MLE helps us estimate these parameters by maximizing the likelihood function derived from the normal distribution’s probability density function.
The Likelihood Function
The likelihood function is central to MLE. It computes the probability of obtaining the observed data given specific parameter values. For a set of independent observations x1,x2,…,xnx1,x2,…,xn from a distribution with a parameter θθ, the likelihood function L(θ)L(θ) is defined as:
L(θ)=P(X=x1,x2,…,xn∣θ)L(θ)=P(X=x1,x2,…,xn∣θ)
In practice, it is often more convenient to work with the log-likelihood function, which is the natural logarithm of the likelihood function:
ℓ(θ)=log(L(θ))ℓ(θ)=log(L(θ))
Maximizing L(θ)L(θ) is equivalent to maximizing ℓ(θ)ℓ(θ), and this transformation simplifies calculations, especially when dealing with products of probabilities.
Steps in Maximum Likelihood Estimation
Maximum Likelihood Estimation (MLE) is a fundamental statistical method used for estimating the parameters of a probability distribution or model based on observed data. The process involves several systematic steps that guide the estimation of parameters to maximize the likelihood function. Here, we outline the steps involved in MLE.
Step 1: Define the Likelihood Function
The first step in MLE is to write down the likelihood function L(θ)L(θ). This function represents the probability of observing the given data under specific parameter values. For a sample of independent observations x1,x2,…,xnx1,x2,…,xn drawn from a probability distribution characterized by parameters θθ, the likelihood function is defined as:
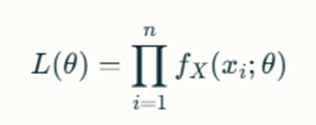
where fX(xi;θ)fX(xi;θ) is the probability density function (PDF) or probability mass function (PMF) evaluated at each observation xixi.
Step 2: Take the Natural Logarithm of the Likelihood Function
To simplify calculations, particularly when dealing with products of probabilities, we take the natural logarithm of the likelihood function. This results in the log-likelihood function:
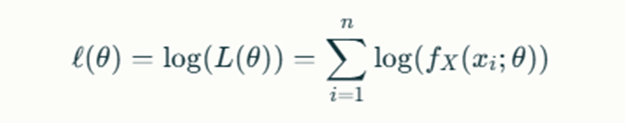
This transformation is beneficial because it converts products into sums, making differentiation easier.
Step 3: Maximize the Log-Likelihood Function
The next step is to find the parameter values that maximize the log-likelihood function. This is typically done by taking the derivative of ℓ(θ)ℓ(θ) with respect to θθ and setting it equal to zero:
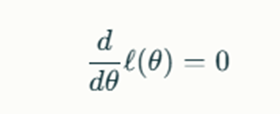
For single-parameter models, this leads to a straightforward equation. In cases where θθ is multi-dimensional (vector-valued), you will need to solve a system of equations:
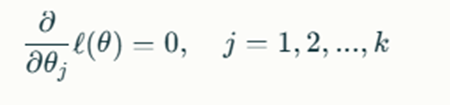
where kk is the number of parameters in θθ.
Step 4: Verify that You Have a Maximum
After finding potential maximum points from Step 3, it’s essential to confirm that these points correspond to a maximum rather than a minimum or inflection point. This can be achieved by examining the second derivative (or Hessian matrix for multi-parameter cases):
- If d2dθ2ℓ(θ)<0dθ2d2ℓ(θ)<0, then θ^θ^ is indeed a maximum.
- Alternatively, numerical methods or graphical analysis can also be used for verification.
Example of MLE
To illustrate these steps, consider estimating parameters for a Poisson distribution based on observed data. Suppose we observe counts of events and want to estimate the parameter λλ.
Likelihood Function: For a Poisson distribution, the likelihood function for observed counts x1,x2,…,xnx1,x2,…,xn is:
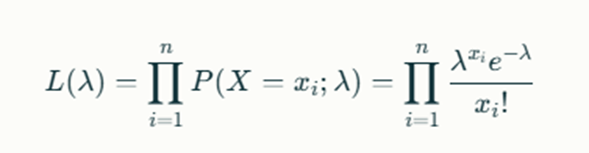
Log-Likelihood Function:
Taking logs gives us:
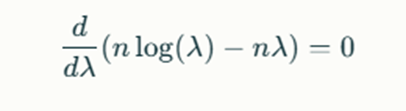
Solving this leads to:
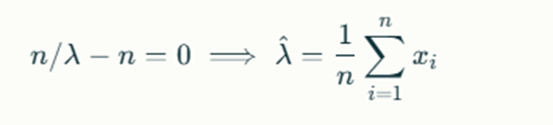
This example illustrates how MLE provides an efficient way to estimate parameters by following systematic steps that ensure robustness and accuracy in statistical modelling.
Applications of Maximum Likelihood Estimation
Maximum Likelihood Estimation (MLE) is a versatile statistical technique employed in various fields for estimating the parameters of probability distributions and statistical models. Its ability to provide efficient and consistent estimates makes it a preferred choice in many empirical applications. Here are some key areas where MLE is prominently utilized:
Econometrics
In econometrics, MLE is widely used for estimating the parameters of economic models. It allows researchers to fit models to data that may be non-linear or involve complex relationships. Common applications include:
- Regression Analysis: MLE is used to estimate parameters in linear and nonlinear regression models, providing insights into the relationships between variables.
- Time Series Analysis: MLE helps in estimating parameters for time series models, such as ARIMA (AutoRegressive Integrated Moving Average) models, which are essential for forecasting economic indicators.
Machine Learning
MLE plays a critical role in Machine Learning, particularly in probabilistic modeling. Its applications include:
- Classification Models: Techniques like logistic regression use MLE to estimate the parameters that maximize the likelihood of observing the training data.
- Clustering Algorithms: MLE is employed in Gaussian Mixture Models (GMM), where it helps in estimating the parameters of multiple Gaussian distributions that best fit the data.
Bioinformatics
In bioinformatics, MLE is crucial for analyzing biological data, particularly in genetics and genomics:
- Gene Expression Analysis: MLE is used to model gene expression levels, allowing researchers to identify significant genes associated with diseases.
- Phylogenetics: It aids in estimating evolutionary trees by maximizing the likelihood of observed genetic sequences under various evolutionary models.
Finance
MLE is extensively applied in finance for modeling and estimating risk:
- Asset Pricing Models: It helps estimate parameters in models like the Capital Asset Pricing Model (CAPM) and Arbitrage Pricing Theory (APT).
- Risk Management: MLE is used to estimate Value at Risk (VaR) and other risk metrics by fitting distributions to financial returns.
Challenges and Limitations of Maximum Likelihood Estimation
While Maximum Likelihood Estimation (MLE) is a powerful and widely used statistical method for estimating the parameters of a probability distribution, it is not without its challenges and limitations.
Understanding these drawbacks is crucial for researchers and practitioners to ensure appropriate application and interpretation of results. Here are some of the key challenges associated with MLE:
Model Assumptions
MLE relies heavily on the assumption that the chosen model accurately describes the underlying data-generating process. If the model is misspecified, the resulting estimates can be biased or inconsistent. For instance, assuming a normal distribution when the data follows a different distribution can lead to significant errors in parameter estimation.
Sensitivity to Initial Values
The optimisation process used in MLE can be sensitive to the choice of starting values for the parameters. Poorly chosen initial values may lead to convergence at local maxima rather than the global maximum of the likelihood function, resulting in suboptimal estimates.
This sensitivity necessitates careful selection or multiple runs with different starting points to ensure reliable results.
Computational Complexity
For complex models or large datasets, MLE can become computationally intensive and time-consuming. The need for numerical optimization techniques, especially in high-dimensional parameter spaces, can lead to increased computational costs and longer processing times25. This complexity may limit its applicability in real-time or resource-constrained environments.
Bias in Small Samples
MLE estimates can be biased when applied to small sample sizes. While MLE properties improve with larger samples—leading to asymptotic consistency and efficiency—the estimates derived from small datasets may not reflect the true parameter values accurately12. This limitation makes it essential to consider sample size when interpreting MLE results.
MLE vs Other Estimation Methods
Maximum Likelihood Estimation (MLE) is a widely used statistical method for estimating parameters of a probability distribution based on observed data. Here’s how MLE compares with other estimation methods, particularly the Method of Moments (MoM) and Least Squares Estimation (LSE).
Efficiency and Consistency
MLE is known for its efficiency, particularly when the model is correctly specified. It achieves the Cramér-Rao lower bound, which indicates that it has the lowest possible variance among unbiased estimators as the sample size increases. This means that MLE tends to provide more precise estimates in large samples.
MoM, while simpler to compute, does not generally achieve the same level of efficiency as MLE. It matches sample moments to population moments, which can lead to less accurate estimates, especially if the underlying distribution is not well understood.
LSE is also efficient under certain conditions, particularly in linear regression models where errors are normally distributed. However, it may not perform as well as MLE in cases where the assumptions of normality are violated.
Bias and Asymptotic Behavior
MLE can be biased in small samples but becomes asymptotically unbiased as the sample size increases. This means that with larger datasets, the bias diminishes relative to the standard deviation, making MLE a robust choice for large samples34.
MoM estimators can also be biased and may not converge to the true parameter value as efficiently as MLE, especially if the moments do not capture the characteristics of the distribution well.
LSE is typically unbiased under its assumptions but can be sensitive to outliers and model misspecification.
Robustness and Flexibility
MLE requires a specific model for the data and can be less robust if that model is incorrect. However, it is flexible enough to be applied across various statistical models and distributions.
MoM is often considered more straightforward but may fail under certain conditions where MLE would still provide consistent estimates. Its reliance on specific moments makes it less versatile than MLE.
LSE is primarily used in linear models and may not generalize well to non-linear relationships or other types of data distributions.
Best Practices of Maximum Likelihood Estimation (MLE)
Maximum Likelihood Estimation (MLE) is a powerful statistical method used for estimating the parameters of a model. Here are three best practices to ensure effective implementation of MLE:
Assume an Appropriate Model for the Data
Choosing the correct model is crucial as the results of MLE are highly dependent on this assumption. It is essential to specify a probability distribution that accurately reflects the underlying process generating the observed data. For example, one might choose between normal, binomial, or Poisson distributions based on the nature of the data being analyzed14.
Calculate the Joint Likelihood Function
Once a model is assumed, the next step is to compute the joint likelihood function. This function aggregates the likelihoods of each individual data point given the model parameters. The joint likelihood function is pivotal because it forms the basis for determining which parameter values maximize the likelihood of observing the given data12.
Optimise Parameter Values
The final step involves finding the parameter values that maximise the joint likelihood function. This typically requires taking the derivative of the likelihood function with respect to the parameters, setting it to zero, and solving for these parameters. This optimisation process can be performed using numerical methods when analytical solutions are not feasible
Conclusion
Maximum Likelihood Estimation stands as a fundamental technique in statistical inference, providing robust estimates across various applications. Its principles are deeply rooted in probability theory and optimization, making it essential for both practitioners and researchers.
Despite its challenges, understanding and applying MLE effectively can lead to significant insights from data.
Frequently Asked Questions
What is Maximum Likelihood Estimation?
Maximum Likelihood Estimation (MLE) is a statistical method used to estimate parameters by maximizing the likelihood function based on observed data. It identifies values that make observed outcomes most probable.
What are Some Applications Of MLE?
MLE is widely used in fields such as econometrics for regression analysis, Machine Learning for fitting models like logistic regression, bioinformatics for genetic studies, and finance for risk modeling.
What are Common Challenges Faced With MLE?
Common challenges include sensitivity to model assumptions leading to biased estimates, computational complexity in high dimensions, and issues with non-identifiability where multiple parameter values yield similar likelihoods.
Authors
-

Written by:
Aashi VermaReviewed by:



