Summary: Big Data encompasses vast amounts of structured and unstructured data from various sources. Key components include data storage solutions, processing frameworks, analytics tools, and governance practices. Understanding these elements is essential for organisations to leverage Big Data effectively, driving insights that enhance decision-making and operational efficiency across industries.
Introduction
In today’s digital age, the volume of data generated is staggering. According to a report by Statista, the global data sphere is expected to reach 180 zettabytes by 2025, a significant increase from 33 zettabytes in 2018.
This explosive growth of data is driven by various factors, including the proliferation of internet-connected devices, social media interactions, and the increasing digitization of business processes.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively.
Key Takeaways
- Big Data originates from diverse sources, including IoT and social media.
- Data lakes and cloud storage provide scalable solutions for large datasets.
- Processing frameworks like Hadoop enable efficient data analysis across clusters.
- Analytics tools help convert raw data into actionable insights for businesses.
- Strong data governance ensures accuracy, security, and compliance in data management.
What is Big Data?
Big Data refers to datasets that are so large or complex that traditional data processing applications are inadequate to handle them.
The term encompasses not only the volume of data but also its variety and velocity. Big Data can be structured, semi-structured, or unstructured, and it comes from numerous sources such as sensors, social media platforms, transaction records, and more.
The Three Vs of Big Data
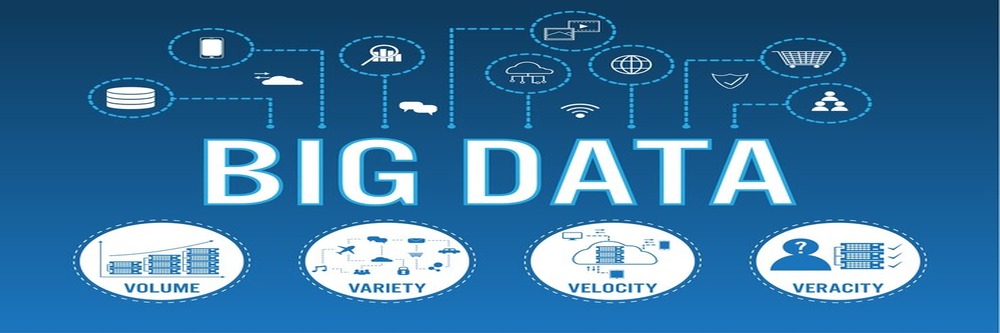
To understand Big Data better, it is crucial to explore its foundational elements known as the Three Vs: Volume, Variety, and Velocity.
Volume
Volume refers to the sheer amount of data generated every second. For example, Facebook users upload over 350 million photos daily, while Twitter users send out approximately 500 million tweets each day. This massive influx of data necessitates robust storage solutions and processing capabilities.
Variety
Variety indicates the different types of data being generated. This includes structured data (like databases), semi-structured data (like XML files), and unstructured data (like text documents and videos). For instance, Netflix uses diverse data types—from user viewing habits to movie metadata—to provide personalised recommendations.
Velocity
Velocity pertains to the speed at which data is generated and processed. Real-time analytics are becoming increasingly important for businesses that need to respond quickly to market changes. For example, financial institutions utilise high-frequency trading algorithms that analyse market data in milliseconds to make investment decisions.
Additional Vs of Big Data
Beyond the original Three Vs, other dimensions have emerged that further define Big Data. Understanding these enhances insights into data management challenges and opportunities, enabling organisations to maximise the benefits derived from their data assets.
Veracity
Veracity refers to the trustworthiness and accuracy of the data. As organisations collect vast amounts of information from various sources, ensuring data quality becomes critical. For instance, healthcare providers must rely on accurate patient records to make informed treatment decisions.
Value
Value emphasises the importance of extracting meaningful insights from data. Organisations must focus on transforming raw data into actionable intelligence that drives decision-making. Companies like Amazon leverage customer behaviour analysis to enhance their marketing strategies and improve user experiences.
Main Components of Big Data
Big Data is a term that describes the massive volume of structured and unstructured data that is too large and complex for traditional data-processing software to manage.
The components of Big Data encompass the technologies and methodologies used to store, process, analyse, and derive insights from this vast array of information. Understanding these components is crucial for organisations looking to leverage Big Data effectively.
Data Sources
Data sources are the origins from which Big Data is generated. They can be categorised into several types. These diverse sources contribute to the volume, variety, and velocity of data that organisations must manage.
- Social Media: Platforms like Facebook, Twitter, and Instagram generate vast amounts of user-generated content daily.
- Internet of Things (IoT): Devices such as sensors, smart appliances, and wearables continuously collect and transmit data.
- Transactional Systems: Businesses gather data from sales transactions, customer interactions, and operational processes.
- Web Logs: Websites track user behaviour through log files that record page visits, clicks, and other interactions.
Storage Solutions
Efficient storage solutions are essential for managing the vast amounts of data generated by various sources.These storage solutions are designed to handle the challenges posed by the sheer volume and complexity of Big Data. Key storage solutions include:
- Data Lakes: Centralised repositories that store raw data in its native format until needed for analysis. Data Lakes allows for flexibility in handling different data types.
- Cloud Storage: Services like Amazon S3, Google Cloud Storage, and Microsoft Azure Blob Storage provide scalable storage solutions that can accommodate massive datasets with ease.
- Distributed File Systems: Technologies such as Hadoop Distributed File System (HDFS) distribute data across multiple machines to ensure fault tolerance and scalability.
Data Processing Frameworks
Processing frameworks are essential for analysing large datasets efficiently. These frameworks facilitate the efficient processing of Big Data, enabling organisations to derive insights quickly.Some popular frameworks include:
- Apache Hadoop: An open-source framework that allows for distributed processing of large datasets across clusters of computers. It is known for its high fault tolerance and scalability.
- Apache Spark: A fast processing engine that supports both batch and real-time analytics, making it suitable for a wide range of applications.
- Apache Flink: Designed specifically for stream processing, Flink enables real-time analytics on continuous data streams.
Analytics Tools
Once data is stored and processed, analytics tools help organisations extract valuable insights .Analytics tools play a critical role in transforming raw data into actionable insights. Key tools include:
- Business Intelligence (BI) Tools: Software like Tableau or Power BI allows users to visualise and analyse complex datasets easily.
- Machine Learning Algorithms: These algorithms can identify patterns in data and make predictions based on historical trends.
- Natural Language Processing (NLP): NLP techniques analyse textual data from sources like customer reviews or social media posts to derive sentiment analysis or topic modelling.
Data Governance
Data governance encompasses the policies and practices that ensure the accuracy, security, and compliance of data within an organisation. Effective data governance is essential for maintaining trust in organisational data assets.Key aspects include:
- Data Quality Management: Ensuring accuracy and consistency in datasets through validation processes.
- Data Security Measures: Protecting sensitive information from breaches through encryption and access controls.
- Compliance Regulations: Adhering to legal standards such as GDPR or HIPAA when handling personal data.
Real-Time Processing
Real-time processing capabilities are becoming increasingly important as organisations seek to respond quickly to changing conditions. It allows organisations to make timely decisions based on current data rather than relying on historical information.Technologies enabling real-time analytics include:
- Stream Processing Frameworks: Tools like Apache Kafka facilitate the continuous ingestion and processing of streaming data.
- In-Memory Databases: Databases such as Redis store data in memory for lightning-fast access and processing speeds.
Visualisation Tools
Visualisation tools help present complex data in an understandable format, making it easier for stakeholders to interpret insights. Effective visualisation enhances communication around data insights and supports informed decision-making.Common tools include:
- Tableau: A leading BI tool that provides interactive visualisations and dashboards.
- Power BI: Microsoft’s analytics service that offers robust visualisation capabilities integrated with other Microsoft products.
Real-World Examples of Big Data Applications
To illustrate how organisations leverage Big Data components effectively, here are some compelling real-world examples across various industries:
Healthcare: Predictive Analytics for Patient Care
Mount Sinai Medical Centre in New York utilises predictive analytics powered by Big Data to forecast patient admissions based on historical health trends. By analysing past patient records, they can optimise staffing levels and resource allocation, resulting in improved patient care outcomes.
Finance: Fraud Detection
JPMorgan Chase employs advanced analytics tools to monitor real-time transactions for fraudulent activities. By analysing patterns in transaction behaviour using Big Data technologies, they can flag suspicious activities promptly, significantly reducing fraud cases and saving millions annually.
Retail: Personalized Shopping Experience
Retail giants like Amazon harness Big Data to offer personalised shopping experiences. By analysing customer preferences based on browsing history and previous purchases, they provide tailored product recommendations that enhance customer satisfaction and loyalty.
Transportation: Route Optimisation
UPS uses Big Data analytics through its ORION system to optimise delivery routes based on traffic patterns and weather conditions. This initiative has led to substantial cost savings—reportedly reducing fuel consumption by millions of gallons annually while improving delivery efficiency.
Agriculture: Precision Farming
John Deere employs Big Data technologies in precision farming practices by collecting sensor data from agricultural equipment. This information helps farmers optimise planting schedules and resource usage, leading to higher yields while minimising waste.
Entertainment: Content Recommendation Systems
Streaming platforms like Netflix utilise Big Data analytics to recommend content based on user viewing habits. By analysing vast amounts of user interaction data, they enhance viewer engagement through personalised content suggestions tailored to individual preferences.
Conclusion
As we navigate an increasingly data-driven world, understanding the main components of Big Data becomes vital for organisations aiming to harness its potential effectively.
By embracing these components and continuously evolving their strategies around Big Data management, companies can position themselves at the forefront of innovation while unlocking new opportunities for growth in an ever-changing landscape.
Frequently Asked Questions
What is the Role of Data Processing Frameworks in Big Data?
Data processing frameworks, such as Apache Hadoop and Apache Spark, are essential for managing and analysing large datasets. They enable distributed processing across clusters, allowing organisations to handle vast amounts of data efficiently. These frameworks support both batch and real-time analytics, enhancing data accessibility and insights.
How Does Big Data Ensure Data Quality?
Big Data ensures data quality through various practices, including data validation, cleansing, and normalization. Organisations implement data governance frameworks to monitor accuracy and consistency. Tools for automated data quality management help identify and rectify errors, ensuring that the insights derived from the data are reliable.
What is a Data Lake, And How Does It Differ from a Traditional Database?
A data lake is a centralised repository that stores vast amounts of raw data in its native format until needed for analysis. Unlike traditional databases that require structured data, data lakes accommodate structured, semi-structured, and unstructured data, providing greater flexibility for analytics.
Authors
-

Written by:
Julie BowieReviewed by: