
Summary: Building a machine learning model is just one step. Validating its performance on unseen data is crucial. Python offers various tools like train-test split and cross-validation to assess model generalizability. This helps identify overfitting and select the best model for real-world use.
Introduction
Model validation in Python refers to the process of evaluating the performance and accuracy of Machine Learning models using various techniques and metrics. It is a crucial step in the model development process to ensure that the model generalizes well to unseen data and does not overfit or underfit the training data.
By validating models, data scientists can assess their effectiveness, identify areas for improvement, and make informed decisions about model deployment. Python provides a range of libraries and tools, such as scikit-learn and pandas, to facilitate the model validation process and streamline the evaluation of Machine Learning models.
What is Model Validation
Model validation is the process of evaluating the performance and accuracy of Machine Learning models to ensure they generalize well to new, unseen data. It is essential to validate models before deployment to ensure they are reliable and effective in real-world applications.
Types of Model Validation Techniques
Train-Test Split
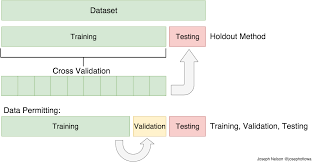
This involves splitting the dataset into two subsets: one for training the model and another for testing its performance. This is a simple yet effective way to evaluate a model’s performance.

Cross-Validation
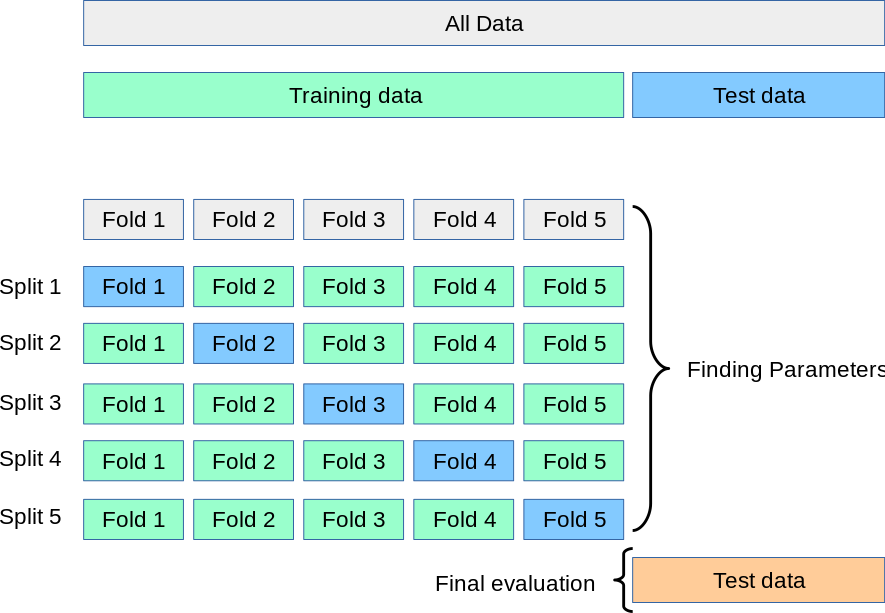
This technique divides the data into k subsets and trains the model k times, each time using a different subset as the test set and the remaining subsets as the training set. This helps to ensure that the model is robust and not dependent on a particular subset of data.

Leave-One-Out Cross-Validation (LOOCV)
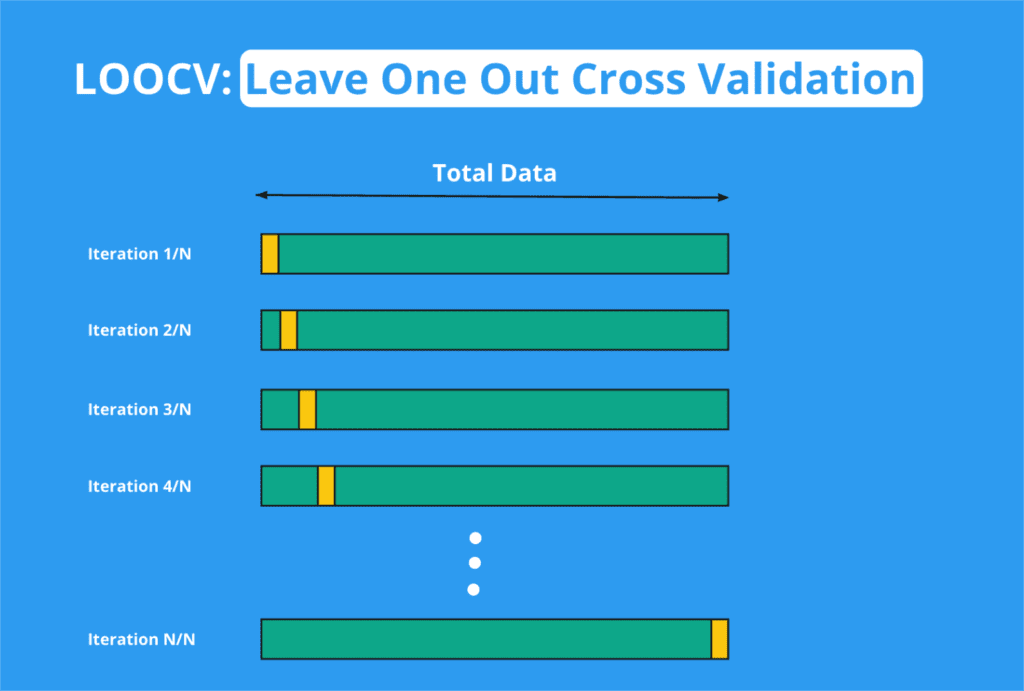
This is a special case of k-fold cross-validation where k is equal to the number of data points in the dataset. It is computationally expensive but can provide a more accurate estimate of the model’s performance
 .
.
These techniques help data scientists assess the performance of their models and make informed decisions about which models to deploy in production.
Cross-Validation Techniques
Cross-validation is a technique used to evaluate the performance of Machine Learning models by splitting the data into multiple subsets. The most common types of cross-validation techniques are k-fold cross-validation, stratified k-fold cross-validation, and leave-one-out cross-validation.
K-Fold Cross-Validation

In k-fold cross-validation, the data is divided into k subsets. The model is trained on k-1 subsets and tested on the remaining subset. This process is repeated k times, with each subset used exactly once as the test set. The final performance metric is the average of the metrics obtained in each iteration.

lit(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# Train and evaluate the model
Stratified K-Fold Cross-Validation

Stratified k-fold cross-validation is used when the target variable is imbalanced. It ensures that each fold has a similar distribution of target classes as the whole dataset, thus reducing bias in the model evaluation.

split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# Train and evaluate the model
Leave-One-Out Cross-Validation (LOOCV)
In leave-one-out cross-validation, a single data point is used as the test set, and the rest of the data is used for training. This process is repeated for each data point, and the final performance metric is the average of all iterations.

o.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# Train and evaluate the model
Comparison of Cross-Validation Techniques
Each cross-validation technique has its advantages and disadvantages. K-fold cross-validation is computationally efficient but may not be suitable for imbalanced datasets. Stratified k-fold cross-validation addresses this issue but can be more computationally expensive.
LOOCV provides an unbiased estimate of model performance but can be computationally prohibitive for large datasets. The choice of cross-validation technique depends on the specific characteristics of the dataset and the goals of the model evaluation.
Train-Test Split
The train-test split technique is used to evaluate the performance of a Machine Learning model. It involves splitting the dataset into two separate sets: the training set and the testing set. The training set is used to train the model, while the testing set is used to evaluate its performance.
It is important to split the data into training and testing sets to ensure that the model generalizes well to new, unseen data. By evaluating the model on a separate testing set, we can assess its performance more accurately and avoid overfitting to the training data.
Best practices for splitting data include:
Randomization: Randomly shuffle the dataset before splitting to ensure that the data is evenly distributed between the training and testing sets.
Stratification: If the dataset is imbalanced, use stratified sampling to ensure that each class represent proportionally in both the training and testing sets.
Cross-Validation: Use cross-validation techniques, such as k-fold cross-validation, to further validate the model and reduce the risk of overfitting.

By following these best practices, we can ensure that our model evaluate in an unbiased manner and can generalize well to new data.
Overfitting and Underfitting
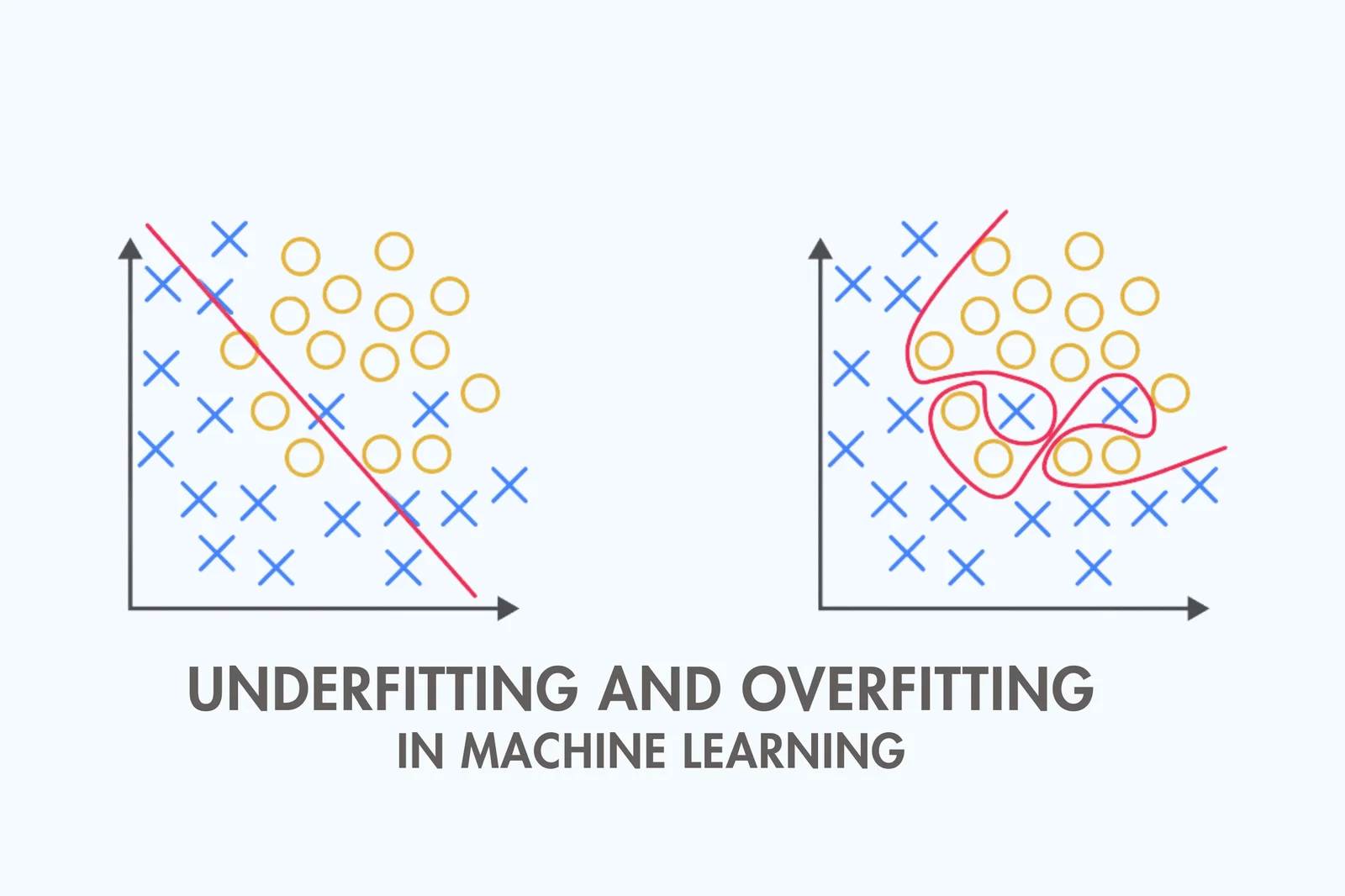
Overfitting and underfitting are two common problems in Machine Learning that can affect the performance of a model.
Overfitting occurs when a model learns the training data too well, capturing noise and random fluctuations in the data instead of the underlying patterns. This can lead to poor generalization performance, where the model performs well on the training data but poorly on unseen data.
Underfitting, on the other hand, occurs when a model is too simple to capture the underlying patterns in the data. This can also lead to poor performance, as the model may not be able to accurately capture the complexity of the data.
Both overfitting and underfitting can impact model validation by making it difficult to assess the true performance of the model. To prevent overfitting, techniques such as cross-validation, regularization, and early stopping can be used.
Cross-validation helps to assess the model’s performance on unseen data, while regularization techniques, such as L1 and L2 regularization, help to penalize overly complex models. Early stopping involves stopping the training process before the model starts to overfit.
Underfitting can prevent by using more complex models, collecting more data, or reducing the regularization strength. By addressing these issues, we can improve the generalization performance of our models and make more accurate predictions on unseen data.
Hyperparameter Tuning
Hyperparameters are configuration settings that are external to the model and whose values cannot estimate from the data. They control the learning process of the model and can significantly impact its performance.
Examples include the learning rate in neural networks, the depth of a decision tree, or the regularization parameter in linear models.
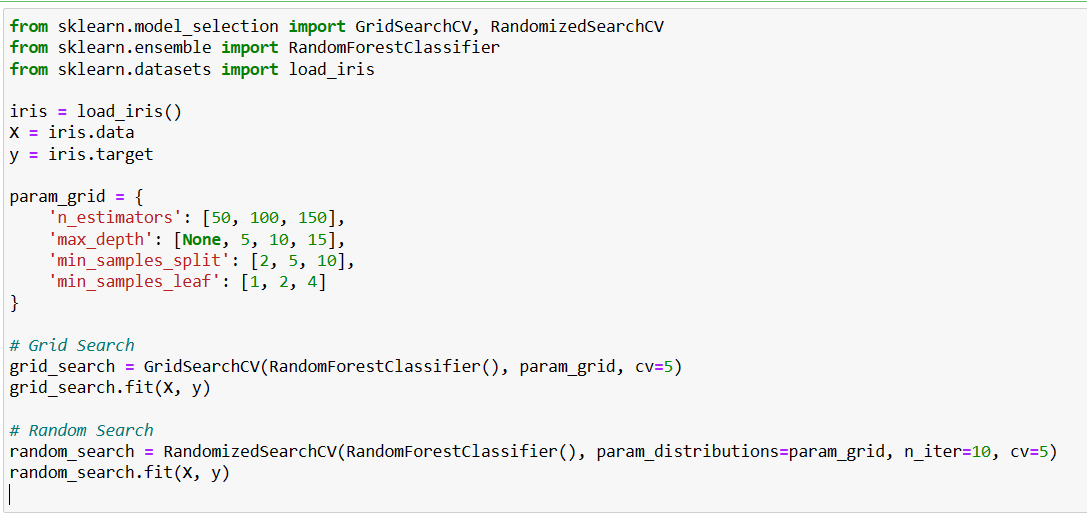
Hyperparameter tuning is essential because selecting the right hyperparameters can greatly improve a model’s performance. Grid search and random search are two popular techniques for hyperparameter tuning.
Grid search exhaustively searches through a specified hyperparameter grid, evaluating the model’s performance for each combination. Random search, on the other hand, samples hyperparameter values randomly from a predefined distribution.
Tuning hyperparameters during model validation is crucial to ensure the model generalizes well to new, unseen data. Failing to tune hyperparameters can result in overfitting or underfitting, leading to poor performance on unseen data.
Model Evaluation Metrics
Common model evaluation metrics such as accuracy, precision, recall, and F1-score use to assess the performance of Machine Learning models.
Accuracy measures the proportion of correct predictions out of the total predictions made by the model. It is suitable for balanced datasets where each class represent fairly equally.
Precision measures the proportion of true positive predictions out of all positive predictions made by the model. It is useful when the cost of false positives is high.
Recall (also known as sensitivity or true positive rate) measures the proportion of true positive predictions out of all actual positive instances in the dataset. It is important when the cost of false negatives is high.
F1-score is the harmonic mean of precision and recall, providing a single metric that balances both measures. It is useful when you want to consider both precision and recall in a single value.
The choice of evaluation metric depends on the specific nature of the problem. For example, in a spam email classification task, recall may be more important than precision because missing a spam email (false negative) is more detrimental than marking a non-spam email as spam (false positive). Understanding the trade-offs between these metrics helps in selecting the most appropriate one for the problem at hand.
Case Study: Model Validation in Python
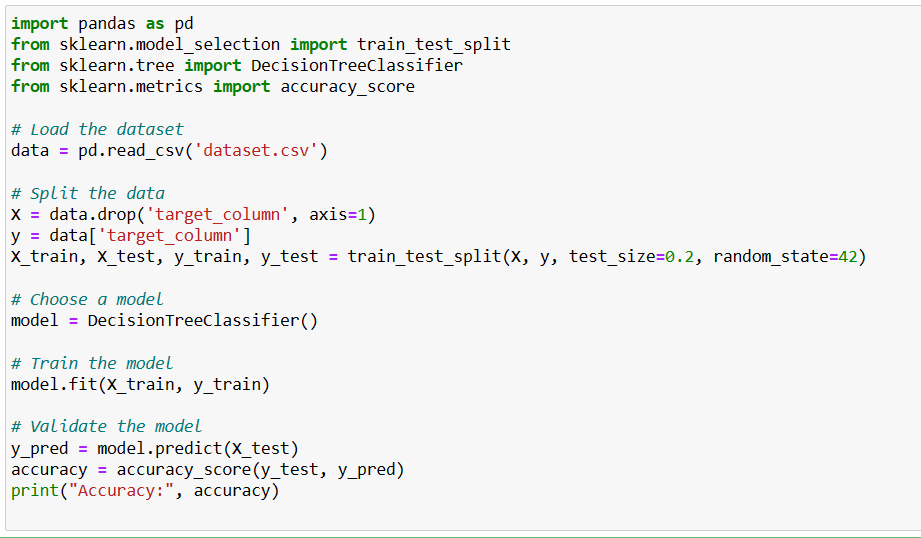
To demonstrate model validation in Python, we can use the popular libraries scikit-learn and pandas. Here’s a step-by-step example using a simple dataset:
1. Load the Dataset: Use pandas to load and preprocess the dataset.
2. Split the Data: Split the dataset into training and testing sets using train_test_split from scikit-learn.
3. Choose a Model: Select a Machine Learning model, such as a decision tree classifier, and instantiate it.
4. Train the Model: Fit the model to the training data.
5. Validate the Model: Use the testing set to make predictions and evaluate the model using metrics like accuracy, precision, recall, and F1-score.
6. Interpret the Results: Analyze the model’s performance metrics to understand how well it generalizes to new data.
Interpreting the results involves analyzing the accuracy and other metrics to determine the model’s performance. A higher accuracy indicates better performance, but it’s essential to consider other metrics to get a comprehensive understanding of the model’s behavior.
Frequently Asked Questions
What Do You Mean by Model Validation?
Model validation checks how well your trained model performs on new data it hasn’t seen before. It ensures the model generalizes well and isn’t just memorizing the training data.
What is Validation in Python?
In Python’s Machine Learning libraries, validation techniques like train-test split and cross-validation help you evaluate a model’s performance on unseen data.
What is Model Validation for Machine Learning Models?
Model validation in Machine Learning is crucial to avoid overfitting, where the model performs well on training data but poorly on unseen data. Validation helps you identify the best model for real-world use.
What’s the Difference Between Model Validation and Testing?
Both assess model performance, but validation uses unseen data, while testing might use a held-out portion of the training data. Validation helps identify generalizability, while testing can provide a final performance check.
Conclusion
Model validation is a critical step in the Machine Learning pipeline to ensure that models generalize well to unseen data. By using techniques like cross-validation, train-test splits, and hyperparameter tuning, data scientists can evaluate and fine-tune their models for better performance.
Python, with libraries like scikit-learn and pandas, provides powerful tools for implementing these techniques. Interpreting the results of model validation, including metrics like accuracy, precision, recall, and F1-score, allows data scientists to make informed decisions about model deployment.
Overall, effective model validation in Python is essential for building reliable and accurate Machine Learning models.
Authors
-

Written by:
Rahul KumarReviewed by:



