
Summary: Learn how to scrape Twitter data using Python with Tweepy and Twint. This guide covers API authentication, data extraction, and ethical considerations. Whether for sentiment analysis, trend tracking, or market research, scraping Twitter data helps you gather real-time insights while ensuring compliance with Twitter’s data policies.
Introduction
One of the best ways organisations collect and gather datasets is through social media platforms like Twitter.
With 611 million monthly active users (MAU) worldwide as of 2025, Twitter (now known as X) ranks as the 12th most popular social media platform globally. This vast user base makes it a valuable source of diverse and real-time data for analysis.
However, gathering data is not easy, and data science projects require a fair amount of data to conduct analysis and evaluation. Twitter provides a rich dataset. It includes posts or tweets that reflect different ideas, sentiments, and opinions across various topics.
This diversity ensures a broad and largely unbiased dataset, making Twitter data highly useful for training new Machine Learning models.
To scrape Twitter data using Python, you must understand Data Scraping and the two key Application Programming Interfaces (APIs)—Tweepy and Twint. This blog will guide you through the process, helping you efficiently collect and analyze Twitter data. Read on to learn more!
Key Takeaways
- Scraping Twitter data using Python helps in sentiment analysis, market research, and trend monitoring.
- Tweepy enables API-based Twitter scraping, ensuring compliance with Twitter’s policies.
- Twint allows scraping without API authentication but may violate Twitter’s terms of service.
- Always adhere to ethical scraping practices and Twitter’s data usage policies.
- Extracted Twitter data can be analysed using Python libraries like Pandas, Matplotlib, and NLP tools.
What is Data Scraping?
Data Scraping, or web scraping, is extracting data from websites or online sources. It involves automated methods of retrieving information from web pages and saving it in a structured format for further analysis, storage, or use in various applications.
Data Scraping typically involves using web scraping tools or programming languages to fetch and extract data from HTML or XML documents. The process consists of sending HTTP requests to web servers, retrieving the HTML content of web pages, and then parsing and extracting the desired data elements.
Why is Data Scraping Performed?

Data scraping is an influential technique organisations and individuals use to collect and analyse large volumes of data from various online sources. Let’s explore some of the key reasons why data scraping is performed:
Data Collection
Data scraping allows organisations or individuals to gather large amounts of data from multiple sources quickly and efficiently. This data can be used for various purposes, such as market research, competitor analysis, sentiment analysis, or building databases.
Price Monitoring and Comparison
E-commerce businesses often employ data scraping to track the prices of products on different websites. This helps them monitor competitors’ prices and adjust their pricing strategies accordingly. It also enables price comparison websites to provide up-to-date and accurate information to users.
Research and Analysis
Data scraping is widely used in academic research, social sciences, and data-driven analysis. Researchers can collect data from websites, social media platforms, or online forums to analyse trends, sentiments, or user behaviour.
Lead Generation
Many businesses use data scraping to collect contact information from websites, such as emails or phone numbers. This data can be used for marketing purposes or to generate leads for sales teams.
Content Aggregation
News websites or content aggregators may employ Data Scraping to automatically collect articles, blog posts, or other content from different sources. This allows them to create comprehensive collections of information and provide users with curated content.
Monitoring and Surveillance
Data Scraping can monitor and track changes on websites or online platforms. For example, it can track stock prices, weather updates, or social media mentions.
Why Scrape Twitter Data?
Scraping Twitter data is a powerful tool for individuals and organisations looking to leverage social media insights. Twitter’s real-time nature provides valuable data that can be harnessed for various purposes. Here are some compelling reasons why scraping Twitter data is valuable:
Market Research
Twitter provides real-time information on public opinions, trends, and consumer behaviour. You can gather insights into market trends, customer preferences, and sentiment analysis by scraping Twitter data. This information can be valuable for market research, competitor analysis, and identifying emerging trends.
Social Media Monitoring
Scraping Twitter data allows you to monitor brand mentions, hashtags, and conversations related to your business or industry. By tracking discussions, you can gauge customer sentiment, address customer concerns, and identify opportunities for engagement or improvement.
Sentiment Analysis
Twitter data scraping can be used for sentiment analysis, which involves determining tweets’ sentiment or emotional tone. Analysing sentiment can help businesses understand how customers perceive their brand, products, or services. It can also be useful for tracking public opinion on specific topics or events.
Trend Analysis
Twitter is known for its real-time nature, making it a valuable source for tracking trends. You can identify popular hashtags, trending topics, and viral content by scraping Twitter data. This information can be used for content creation, social media marketing, and staying updated on current events.
Customer Insights
Twitter data scraping enables you to gather information about your target audience, interests, demographics, and behaviour. This knowledge can help businesses tailor their marketing strategies, develop targeted advertising campaigns, and personalise customer experiences.
2 APIs for Twitter Data Scraping
APIs, or Application Programming Interfaces, are sets of rules and protocols that allow different software applications to communicate with each other. In the context of Twitter data scraping, APIs enable developers to interact with Twitter’s platform to access and retrieve data. Specifically, Twitter offers two main APIs commonly used for data scraping. These include:
Tweepy
Tweepy is a popular Python library designed for easy interaction with the Twitter API. It streamlines accessing Twitter data by offering a user-friendly interface, making it more straightforward for developers to authenticate and fetch tweets, user profiles, trends, and more.
Tweepy supports the Twitter REST API and Streaming API, allowing users to gather historical data and real-time updates. It also provides functionalities like posting tweets, following users, and sending direct messages, making it a comprehensive tool for programmatically managing and analysing Twitter content.
Key features of Tweepy include:
- Authentication: Tweepy supports OAuth authentication, the standard method for securely accessing the Twitter API. It simplifies the process of authenticating your application and handling rate limits.
- API Methods: Tweepy provides methods that allow you to interact with different parts of the Twitter API. You can fetch tweets, user information, followers, timelines, and search results and perform actions like posting tweets, following or unfollowing users, and more.
- Streaming API: Tweepy supports the Twitter Streaming API, which allows you to receive real-time data from Twitter. You can track keywords, hashtags, and user mentions or filter tweets based on specific criteria.
- Rate Limit Handling: Tweepy automatically handles rate limits imposed by the Twitter API. It manages the timing and retries for API requests, ensuring you stay within the allowed limits.
Twint
Twint is a versatile Python library designed for scraping data from Twitter without relying on the Twitter API. It stands out for its ability to retrieve large volumes of historical tweets, even beyond the limits of standard API access. Twint allows users to perform advanced searches based on various parameters such as hashtags, user mentions, and date ranges.
Additionally, it can extract data like tweet content, user details, and engagement metrics. This makes Twint an invaluable tool for researchers and analysts seeking comprehensive data for sentiment analysis, trend tracking, or other data-driven projects.
Key features of Twint include:
- No API Restrictions: Twint does not require API authentication, making it a helpful tool for scraping large volumes of historical tweets without being limited by API restrictions.
- Advanced Search and Filtering: Twint allows you to perform complex searches and apply various filters to narrow your data retrieval. You can search based on keywords, usernames, locations, dates, languages, etc.
- User and Tweet Information: Twint provides detailed user and tweet information access. You can retrieve user profiles, followers, and followings and interact with tweet data such as retweets, replies, and favourites.
- Custom Output Formats: Twint allows you to export the scraped data in various formats, including CSV, JSON, and SQLite. This makes it convenient to save and analyse the data using different tools and platforms.
How Do You Scrape Data from Twitter Using Python?
To scrape data from Twitter using Python, you can utilise various libraries and APIs. Here’s a step-by-step guide on how to scrape data from Twitter using Python:
1. Set up Twitter API credentials:
- Create a Twitter Developer account and apply for a Twitter Developer API key.
- Generate access tokens (API key, API secret key, access token, and access token secret) for authentication.
2.Install the required libraries:
- Install the Tweepy library by running pip install tweepy.
3. Import the necessary libraries:

4. Authenticate with Twitter API using Tweepy:

5. Define search parameters and scrape tweets:
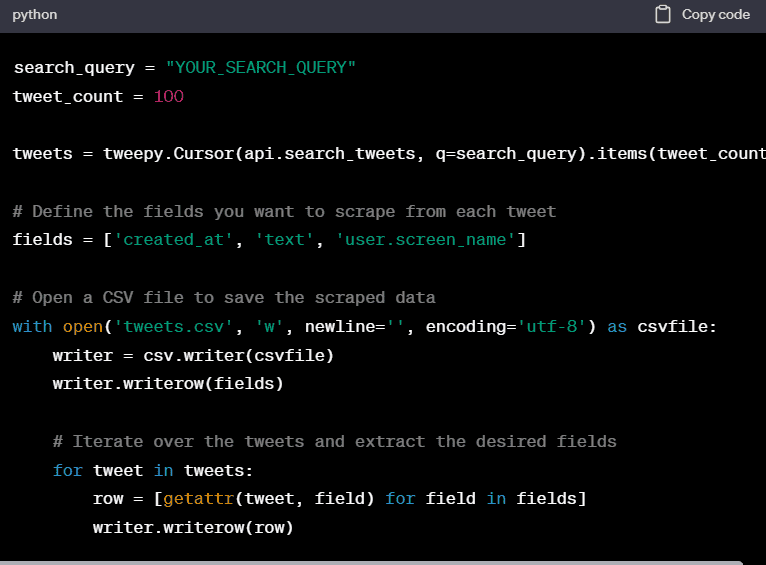
In the above example, we scrape tweets based on a search query and specify the number of tweets to retrieve. You can modify the search_query variable and fields list to suit your needs. The extracted data, including the tweet’s creation timestamp, text, and the user’s screen name, is saved in a CSV file named “tweets.csv”.
6. Execute the script: Save it as a Python file (e.g., twitter_scraper.py) and run it using a Python interpreter.
7. Analyse and process the scraped data: Once it is scraped and saved, you can analyse it using various Python libraries and techniques. For example, you can use pandas for data manipulation, Matplotlib or Seaborn for data visualisation, and natural language processing libraries for text analysis.
Remember to comply with Twitter’s terms of service and API usage guidelines when scraping data from Twitter. Be mindful of rate limits and respect users’ privacy. Additionally, consider using advanced search parameters and filters the Twitter API provides to refine your data retrieval.
Bottom Line
Scraping Twitter data using Python empowers businesses, researchers, and analysts to extract valuable insights from real-time social media activity. By leveraging APIs like Tweepy and Twint, you can efficiently collect, analyse, and visualise Twitter data for sentiment analysis, market research, and trend detection.
While Tweepy provides authenticated API access, Twint offers unrestricted scraping without API limitations. However, always comply with Twitter’s policies and ethical guidelines when collecting data. If you’re new to Python, you can learn it for free with Pickl.AI, which offers free data science courses for everyone. Start your journey today and master data science skills!
Frequently Asked Questions
How do you Scrape Twitter Data using Python?
You can scrape Twitter data using Python by utilising Tweepy or Twint. Tweepy connects to the Twitter API for authenticated data retrieval, while Twint allows scraping without API restrictions. Both libraries help extract tweets, user data, and trends for analysis. Always follow Twitter’s data policies.
Is it legal to Scrape Twitter Data using Python?
Scraping Twitter data is legal if done through Twitter’s API (Tweepy) while adhering to its guidelines. However, using Twint, which bypasses API authentication, may violate Twitter’s terms. Always review Twitter’s policies and consider ethical data scraping practices to ensure compliance with legal standards.
Which is Better for Scraping Twitter Data: Tweepy or Twint?
Tweepy is ideal for API-based scraping, offering structured access and compliance with Twitter’s rules. Twint is better for unrestricted data extraction but may violate Twitter’s terms. If you require official access, use Tweepy. For extensive historical data without authentication, Twint is more effective but riskier.
Authors
-

Written by:
Neha SinghReviewed by:



