
Summary: Hidden Markov Models (HMM) are statistical models used to represent systems with hidden states and observable outputs. This guide delves into their mathematical foundations, applications across various fields, implementation techniques, and challenges. Learn best practices for effectively leveraging HMMs in data-driven research and decision-making processes.
Introduction
In the realm of statistical modelling and machine learning, Hidden Markov Models (HMMs) stand out as powerful tools for dealing with sequential data. Their ability to model systems where the underlying states are not directly observable makes them particularly useful in various applications, ranging from speech recognition to bioinformatics.
This blog will provide an in-depth exploration of HMMs, covering their fundamental concepts, mathematical foundations, applications, implementation strategies, challenges, and best practices.
Understanding Hidden Markov Model
A Hidden Markov Model is a statistical model that represents systems governed by hidden states. In an HMM, the process consists of two layers: hidden states, which we cannot directly observe, and observable outputs that the hidden states generate.
The model operates under the Markov property, which assumes that the future state depends only on the current state and not on the sequence of events that preceded it.
Components of HMM
Hidden States: These are the unobservable states of the system. For example, in a speech recognition task, the model could use hidden states to represent phonemes or words.
Observations: The hidden states generate these visible outputs. In the speech example, the audio signals captured by a microphone serve as the observations.
Transition Probabilities: These probabilities define the likelihood of moving from one hidden state to another. We represent these in a matrix, where each entry shows the probability of transitioning from state ii to state jj.
Emission Probabilities: These probabilities determine the likelihood of observing a particular output from a hidden state. Each hidden state has its own probability distribution over the possible observations.
Initial State Distribution: This is a probability distribution that defines the likelihood of the system starting in each of the hidden states.
Mathematical Foundation
Probability theory forms the mathematical foundation of HMMs. The model relies on the following key concepts:
Markov Property
The Markov property states that the future state of a process depends only on the current state and not on the sequence of events that preceded it. We can express this mathematically as:

where ZtZt represents the hidden state at time tt.
Joint Probability Distribution
We can express the joint probability of a sequence of hidden states ZZ and observations OO as:
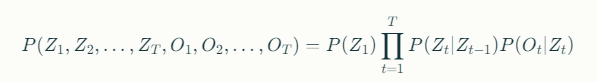
This equation captures the relationship between the hidden states and the observations, allowing us to compute probabilities based on the model parameters.
Inference Problems
Inference problems in Hidden Markov Models involve computing the probability of observations given a model, determining the most likely sequence of hidden states, and learning the model parameters from observed data. We solve these problems using algorithms such as Forward, Viterbi, and Baum-Welch. HMMs are associated with three fundamental problems:
Evaluation Problem: Given a model and a sequence of observations, compute the probability of the observations. We typically solve this problem using the Forward algorithm.
Decoding Problem: Given a sequence of observations, determine the most likely sequence of hidden states. The Viterbi algorithm is commonly used for this purpose.
Learning Problem: Given a set of observations, learn the model parameters (transition and emission probabilities). We use the Baum-Welch algorithm, a special case of the Expectation-Maximization (EM) algorithm, for this purpose.
Applications of Hidden Markov Model

HMMs have found applications across various domains due to their flexibility and effectiveness in modeling sequential data. Some notable applications include:
Speech Recognition
HMMs are widely used in automatic speech recognition systems. They model the relationship between phonemes (hidden states) and the audio signals (observations) produced during speech. By training HMMs on large datasets of spoken language, systems can accurately transcribe spoken words into text.
Natural Language Processing
In Natural Language Processing (NLP), HMMs are employed for tasks such as part-of-speech tagging and named entity recognition. The hidden states represent grammatical categories or entities, while the observations correspond to words in a sentence.
Bioinformatics
HMMs are extensively used in bioinformatics for tasks like gene prediction and protein structure prediction. They can model the hidden states representing biological sequences, such as genes, and the observations as the corresponding nucleotide or amino acid sequences.
Financial Modelling
In finance, we can apply HMMs to model stock price movements and market regimes. The hidden states can represent different market conditions (e.g., bull or bear markets), while the observations correspond to observed stock prices or returns.
Gesture Recognition
We use HMMs in gesture recognition systems to model the sequence of movements a user makes. The hidden states represent different gestures, while the observations correspond to sensor readings or motion data.
Implementing HMM
Implementing a Hidden Markov Model involves several steps, including data preparation, model training, and evaluation. Below is a general outline of the implementation process:
Data Preparation
The first step is to collect and preprocess the data. This may involve cleaning the data, handling missing values, and transforming the observations into a suitable format for analysis.
Model Initialisation
Next, we need to initialize the model parameters, including the initial state distribution, transition probabilities, and emission probabilities. We can do this randomly or based on prior knowledge.
Training the Model

We commonly use the Baum-Welch algorithm to train HMMs. This algorithm iteratively updates the model parameters to maximize the likelihood of the observed data. The process involves two steps:
Expectation Step: Calculate the expected counts of transitions and emissions based on the current model parameters.
Maximization Step: Update the model parameters based on the expected counts.
Evaluating the Model
Once we train the model, we must evaluate its performance. We do this by computing the likelihood of the observed data through the evaluation problem. Additionally, the model can be tested on a separate validation dataset to assess its generalization capabilities.
Decoding and Prediction
Finally, we use the Viterbi algorithm to decode the most likely sequence of hidden states given the observations. This step is crucial for applications such as speech recognition and part-of-speech tagging.
Challenges and Considerations
While HMMs are powerful tools, they come with several challenges and considerations that researchers and practitioners should be aware of:
Model Complexity
HMMs can become complex when dealing with large state spaces or numerous observations. This complexity can lead to increased computational requirements and difficulties in parameter estimation.
Overfitting
Overfitting occurs when the model learns the noise in the training data rather than the underlying patterns. This can lead to poor performance on unseen data. Techniques such as regularization and cross-validation can help mitigate this issue.
Assumptions of Independence
HMMs rely on the assumption that the observations are conditionally independent given the hidden states. Violations of this assumption can lead to inaccurate model predictions.
Initialisation Sensitivity
The performance of HMMs can be sensitive to the initial parameter values. Poor initialization can lead to suboptimal solutions. Using multiple random initialisations and selecting the best-performing model can help address this issue.
Advanced Topics in HMM
As research in HMMs continues to evolve, several advanced topics have emerged that enhance the capabilities of traditional HMMs:
Non-Stationary HMMs
Non-stationary HMMs allow for time-varying transition probabilities, which can be useful in applications where the underlying process changes over time. These models incorporate additional parameters to capture the temporal dynamics.
Deep Learning and HMMs
The integration of Deep Learning techniques with HMMs has gained popularity in recent years. By combining the strengths of neural networks with HMMs, researchers can develop more robust models for complex tasks such as speech recognition and natural language processing.
Hierarchical HMMs
Hierarchical HMMs extend traditional HMMs by incorporating multiple levels of hidden states. This allows for modeling more complex processes with varying levels of abstraction, making them suitable for applications in areas like video analysis and gesture recognition.
Best Practices
To effectively implement and utilize Hidden Markov Models, researchers and practitioners should consider the following best practices:
Data Quality
Ensure that the data used for training is of high quality and representative of the problem domain. Preprocessing steps, such as normalization and outlier removal, can improve model performance.
Model Selection
Carefully select the number of hidden states and the structure of the HMM based on the specific application. Using techniques like cross-validation can help determine the optimal model configuration.
Parameter Tuning
Experiment with different initialization strategies and hyperparameters to enhance model performance. Techniques such as grid search or Bayesian optimization can be employed for effective parameter tuning.
Regularization
Implement regularization techniques to prevent overfitting, especially when working with complex models or limited training data.
Evaluation Metrics
Use appropriate evaluation metrics to assess model performance. Metrics such as accuracy, precision, recall, and F1-score can provide valuable insights into the model’s effectiveness.
Conclusion
Hidden Markov Models are powerful statistical tools that have found widespread applications across various domains. Their ability to model systems with hidden states and observable outputs makes them particularly useful for tasks involving sequential data.
By understanding the mathematical foundations, implementation strategies, and challenges associated with HMMs, researchers can harness their potential to solve complex problems in fields such as speech recognition, natural language processing, and bioinformatics.
As the field continues to evolve, advancements in HMMs, including integration with Deep Learning techniques and the development of non-stationary models, promise to enhance their capabilities further. By following best practices and staying informed about emerging trends, practitioners can effectively leverage HMMs to drive innovation and improve decision-making in data-driven research.
Frequently Asked Questions
What is a Hidden Markov Model?
A Hidden Markov Model (HMM) is a statistical model that represents systems with hidden states, where the observations depend on these hidden states. HMMs are widely used for tasks involving sequential data, such as speech recognition and bioinformatics.
What are the Key Applications of HMMs?
HMMs are applied in various fields, including speech recognition, natural language processing, bioinformatics, financial modeling, and gesture recognition. Their ability to model hidden processes makes them suitable for tasks involving sequential data.
How are HMMs Implemented?
HMMs are implemented through several steps, including data preparation, model initialization, training using the Baum-Welch algorithm, evaluation of model performance, and decoding the most likely sequence of hidden states using the Viterbi algorithm.
Authors
-

Written by:
Karan SharmaReviewed by:



