Summary: AWS Lambda enables serverless computing, letting developers run code without managing servers. It offers benefits like automatic scaling and pay-as-you-go pricing, and integration with AWS services enhances its functionality.
Introduction
AWS Lambda is a powerful serverless computing service that Amazon Web Services (AWS) provides. It allows developers to run code without provisioning or managing servers, enabling efficient and scalable application development. Serverless architecture’s importance lies in its ability to handle infrastructure tasks, automatically reducing operational complexity and cost.
This article aims to explore AWS Lambda by exploring its functions and how to code with it. By understanding Functions and Code with AWS Lambda, developers can easily harness their full potential to build robust, responsive applications.
What is AWS Lambda?
AWS Lambda is a serverless computing service provided by Amazon Web Services (AWS), enabling you to run code without provisioning or managing servers. With Lambda, you can execute your code in response to various events such as HTTP requests, file uploads to S3, or changes in a DynamoDB table.
This service allows developers to focus on writing code while AWS automatically handles the infrastructure, scaling, and availability.
Key Features of AWS Lambda
- Event-Driven Execution: AWS Lambda triggers your code in response to events, making it ideal for building event-driven applications.
- Automatic Scaling: Lambda automatically scales your application by running the code responding to each trigger. Whether you have one request or thousands, Lambda scales seamlessly to meet demand.
- Pay-As-You-Go Pricing: With AWS Lambda, you only pay for the computing time you consume, billed in increments of 1 millisecond. This makes it a cost-effective solution, especially for applications with sporadic workloads.
- Support for Multiple Languages: Lambda supports many programming languages, including Python, JavaScript (Node.js), Java, C#, Ruby, and Go. Thus, you can choose the language that best suits your project.
Benefits of Using AWS Lambda
AWS Lambda offers several benefits, including cost-effectiveness and scalability. With its pay-as-you-go pricing model, you avoid the costs of maintaining idle servers. Lambda’s automatic scaling ensures your application can handle varying traffic levels without manual intervention.
Additionally, AWS Lambda’s serverless nature eliminates the need for server management, allowing developers to focus more on code and less on infrastructure.
Read: Serverless Computing: An In-depth Analysis.
Comparison with Traditional Server-Based Computing
Unlike traditional server-based computing, where you need to provision and manage physical or virtual servers, AWS Lambda abstracts away the underlying infrastructure. In a traditional setup, you often have to estimate and pay for server capacity, even if it goes unused.
In contrast, Lambda automatically scales based on demand and charges you only for the execution time, offering cost efficiency and operational simplicity. AWS Lambda is a compelling choice for modern applications requiring agility, scalability, and cost management.
Understanding AWS Lambda Functions
AWS Lambda is a serverless computing service that lets you run code without provisioning or managing servers. It allows you to execute code responding to specific events and automatically scales the infrastructure to handle incoming requests.
How AWS Lambda Functions Work
AWS Lambda functions are small, self-contained pieces of code that execute in response to an event. You write the function code and define the triggers, and AWS Lambda takes care of the rest.
The function runs in a stateless environment, meaning each invocation is independent of others. When an event occurs, such as an HTTP request or a file upload to S3, AWS Lambda triggers the function, which then processes the event and returns a response. The function only runs when needed, making it cost-effective and efficient.
Triggers and Events in AWS Lambda
Triggers and events are central to how AWS Lambda operates. A trigger is a source that initiates the execution of a Lambda function, while an event is the specific data passed to the function when it is triggered. Common triggers include Amazon S3 bucket changes, API Gateway requests, and DynamoDB table updates.
For instance, when a new object is uploaded to an S3 bucket, it can trigger a Lambda function to process it or store information in a database. You can configure multiple triggers for a single function, allowing it to respond to various events.
Use Cases for Lambda Functions
AWS Lambda functions are versatile and can be used in numerous scenarios. Some common use cases include:
- Real-time data processing: Analysing and transforming data streams in real-time.
- Automated backups: Triggering functions to back up data whenever files are modified.
- Web APIs: Serving web requests without managing servers.
- IoT applications: Processing data from IoT devices and responding instantly.
Explore: How to Use ChatGPT APIs in Python: A Comprehensive Guide.
Setting Up AWS Lambda
Getting started with AWS Lambda involves a few key steps to ensure your serverless functions run smoothly. Following this guide, you can create and configure your own Lambda functions efficiently.
Prerequisites for Using AWS Lambda
Before diving into AWS Lambda, ensure you have an AWS account. You should also have basic knowledge of AWS services and a development environment set-up, including an IDE or text editor.
Familiarity with Lambda-supporting programming languages, such as Python, Node.js, or Java, is beneficial. Finally, the AWS Command Line Interface (CLI) will be installed to manage Lambda functions from the terminal.
Step-by-Step Guide to Creating a Lambda Function
Step 1: Log in to the AWS Management Console: Search for “Lambda” in the AWS console to access the Lambda service.
Step 2: Create a New Function: Click on “Create function.” You can start from scratch, use a blueprint, or deploy a container image. For simplicity, select “Author from scratch.”
Step 3: Configure Basic Settings:
- Function Name: Enter a unique name for your Lambda function.
- Runtime: Choose the runtime environment (e.g., Python 3.8, Node.js 14.x).
- Permissions: Create a new role with basic Lambda permissions or use an existing role.
Step 4: Write or Upload Code: You can write your code directly in the inline editor or upload a .zip file containing your code and dependencies. Lambda supports various languages and environments.
Step 5: Set Up Triggers and Event Sources: Configure how your Lambda function will be triggered. This could be via HTTP requests through API Gateway, changes in S3 buckets, or other AWS services.
Check: What is Data Management? A Complete Guide with Examples & Benefits.
Configuring the Runtime Environment
Adjust the runtime settings according to your function’s needs. Set memory allocation, timeout duration, and environment variables to optimise performance. The default memory is 128 MB, but you can increase it based on the complexity of your function.
Following these steps, you’ll have a functional Lambda setup ready to effectively handle your serverless computing tasks.
Writing Code for AWS Lambda
Writing code for AWS Lambda is straightforward and flexible, thanks to its support for various programming languages. By leveraging Lambda, developers can focus on writing code without managing servers, accelerating development and reducing operational overhead.
This section delves into the supported programming languages, and best practices for writing efficient Lambda functions and provides example code snippets in popular languages such as Python and Node.js.
Supported Programming Languages
AWS Lambda supports various programming languages, including Python, Node.js, Java, C#, Go, Ruby, and custom runtimes. This versatility allows developers to use the most comfortable language or best suited for their application needs. Each language has its own library and tools, which can be integrated into Lambda functions to streamline development and deployment processes.
Best Practices for Writing Efficient Lambda Code
Writing efficient code for serverless functions is key to ensuring optimal performance and cost-effectiveness. This section explores best practices for developing Lambda functions, including code organisation, performance optimisation, and error handling. By following these guidelines, developers can enhance the reliability and scalability of their serverless applications.
Keep Functions Small and Focused
Design Lambda functions to perform a single task. This approach simplifies debugging, improves code maintainability, and ensures the function executes quickly. Small, focused functions also minimise cold start times and resource consumption.
Optimise Code for Performance
Write efficient code to reduce execution time and costs. Avoid unnecessary operations and leverage built-in libraries and services. For example, use efficient data structures and algorithms suited to your specific use case.
Manage Dependencies Wisely
Only include necessary dependencies in your deployment package. Large deployment packages increase initialisation times and impact performance. Use AWS Lambda layers to manage shared code or libraries.
Handle Errors Gracefully
Implement proper error handling and logging within your Lambda functions. Use AWS CloudWatch Logs to monitor execution and troubleshoot issues. Implement retry mechanisms and failover strategies to handle transient errors.
Test Locally and Use Environment Variables
Test Lambda functions locally using tools like AWS SAM CLI or AWS Lambda Local. Environment variables should be used to manage configuration settings, which helps keep the codebase clean and adaptable to different environments.
Example Code Snippets
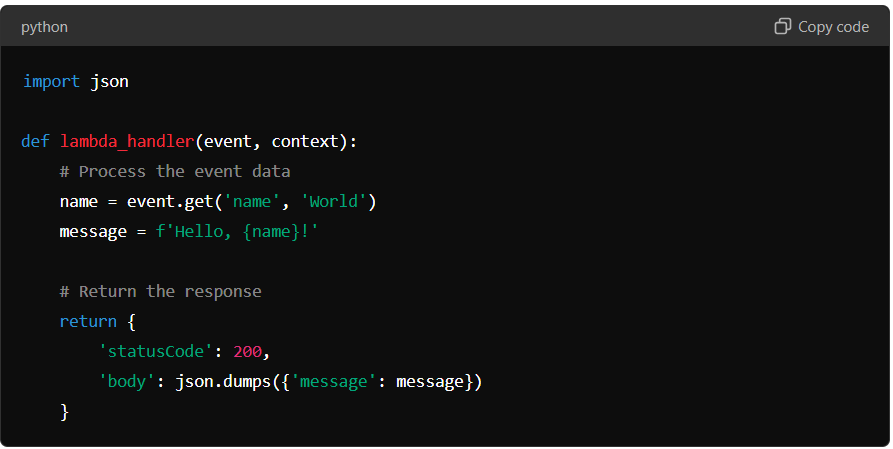
Python Example:
Node.js Example:
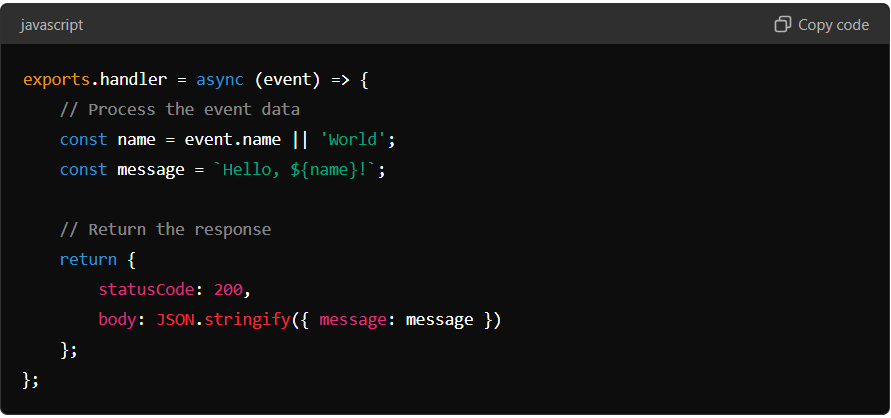
In both examples, the Lambda function processes an event, performs a simple operation, and returns a response. These examples illustrate the simplicity of writing Lambda functions while adhering to best practices. Following these guidelines, developers can create efficient, reliable, scalable serverless applications using AWS Lambda.
Further Read:
Python Developer Framework: A Comprehensive Guide.
Who is a BI Developer: Role, Responsibilities & Skills.
Deploying and Testing AWS Lambda Functions
Deploying and testing AWS Lambda functions involves several key steps to ensure your serverless applications run smoothly. Here’s a concise guide to help you through the process.
How to Deploy a Lambda Function
Deploying a Lambda function starts with creating the function in the AWS Management Console or using AWS CLI/SDKs. Begin by writing your code, which can be in languages like Python, Node.js, or Java. If necessary, package your code and its dependencies into a ZIP file.
Upload this package to AWS Lambda through the console, or automate deployment using AWS CLI with the aws lambda create-function command.
Configure your function’s settings, such as memory allocation, execution timeout, and IAM role permissions. Specify a trigger (like an S3 event or an API Gateway) invoking your Lambda function. Once deployed, AWS Lambda manages scaling and infrastructure, allowing you to focus on your application logic.
Testing and Debugging Lambda Functions
Testing Lambda functions is crucial to ensure they perform as expected. Use the built-in testing capabilities in the AWS Management Console to create test events and simulate invocations. For more advanced debugging, integrate Lambda with your development environment using tools like AWS SAM (Serverless Application Model) or the AWS Toolkit for IDEs.
The AWS Lambda console also provides a testing section where you can invoke functions with sample events and examine their output. Pay close attention to error messages and logs to identify and address issues.
Monitoring and Logging with AWS CloudWatch
Monitoring and logging are essential for maintaining Lambda functions. AWS CloudWatch automatically captures logs from Lambda executions, providing real-time insights into function performance and errors. Use CloudWatch Logs to review detailed execution logs and CloudWatch Metrics to track performance metrics like invocation count, duration, and error rates.
Set up CloudWatch Alarms to alert you to performance issues or errors, enabling prompt action to resolve potential problems. By leveraging these monitoring tools, you ensure your Lambda functions remain reliable and efficient.
Integrating AWS Lambda with Other AWS Services

Integrating serverless functions with other AWS services enhances its functionality and allows you to build complex applications with minimal operational overhead. AWS Lambda is designed to seamlessly interact with various AWS services, enabling you to efficiently automate tasks, process data, and build event-driven applications.
Connecting Lambda with AWS S3, DynamoDB, API Gateway, etc.
AWS Lambda integrates smoothly with several AWS services. For instance, you can configure Lambda functions to trigger automatically in response to events from Amazon S3, such as file uploads. This allows you to process or transform files in real time as they are added to S3 buckets.
Similarly, Lambda can work with Amazon DynamoDB to respond to data changes. Using DynamoDB Streams, Lambda functions can react to changes in your database tables, enabling real-time data processing and updates without manual intervention.
It also integrates with API Gateway to create scalable APIs. API Gateway handles incoming HTTP requests and routes them to your Lambda functions, processing the requests and returning responses. This setup is ideal for building serverless web applications and microservices.
Automating tasks using AWS Lambda
Lambda’s ability to automate tasks is a powerful feature. You can use Lambda functions to automate routine administrative tasks, such as backing up data, updating resources, or managing configurations. For example, Lambda can be set up to automatically clean up expired resources or handle alerts triggered by AWS CloudWatch.
Real-world examples of Lambda integrations
In practical scenarios, companies use Lambda for a variety of tasks. A common example is processing uploaded images in S3, where Lambda functions automatically resize or optimise images for web use.
Another example is a real-time analytics pipeline, where Lambda processes and analyses streaming data from IoT devices or user interactions, enabling businesses to make informed decisions quickly.
Scaling and Managing AWS Lambda Functions
Scaling and managing it functions is crucial for optimising performance and controlling costs. AWS Lambda’s design inherently supports automatic scaling, but effective management can further enhance efficiency and reduce expenses.
Automatic Scaling of Lambda Functions
AWS Lambda automatically scales your applications in response to incoming traffic. When an event triggers a Lambda function, AWS creates an instance of the function to handle it. If the event volume increases, Lambda automatically creates additional instances to process requests concurrently. This ensures that your application can handle variable loads without requiring manual intervention.
Managing Lambda Function Performance
To maintain optimal performance, monitor your Lambda functions using AWS CloudWatch. Set up alarms for metrics such as execution duration, error rates, and invocation counts. Analyse these metrics to identify performance bottlenecks and adjust resources accordingly. Implementing best practices like optimising code, minimising cold start times, and using provisioned concurrency can also improve performance.
For instance, keeping dependencies lightweight and avoiding heavy initialisations in your function code can significantly reduce execution times.
Cost Management Tips for AWS Lambda
Managing costs effectively is key to maximising the benefits of AWS Lambda. Start by understanding the pricing model, which charges based on the number of requests and execution duration. To control costs, regularly review your Lambda usage and performance metrics. Utilise Lambda’s built-in cost management tools to set budget alerts and limits.
Additionally, optimising function code and reducing execution time can lower expenses. Consider using reserved concurrency for functions with predictable traffic patterns, which can help manage costs and ensure consistent performance.
Focusing on these aspects can help you effectively scale and manage AWS Lambda functions, ensuring they deliver reliable performance while keeping costs under control.
Security Considerations for AWS Lambda
When deploying applications with AWS Lambda, ensuring the security of your functions is paramount. Lambda’s serverless nature introduces unique security considerations that need to be addressed to protect your data and operations.
This section explores essential security best practices for Lambda functions, the role of IAM (Identity and Access Management), and the handling of sensitive data effectively.
Security Best Practices for Lambda Functions
To secure Lambda functions, follow best practices such as least privilege and network isolation. Grant only the permissions necessary for your function to operate, which minimises potential damage if an attacker compromises it.
Use environment variables to securely manage configuration settings and employ AWS Key Management Service (KMS) to encrypt sensitive information. Additionally, regularly update your Lambda runtime and dependencies to patch vulnerabilities.
Role of IAM in Lambda
IAM is crucial in securing Lambda functions by managing permissions and roles. Assign IAM roles to your Lambda functions with the principle of least privilege, ensuring each function has only the permissions it needs.
Use IAM policies to define granular access controls and restrict actions based on specific conditions. Review and audit IAM roles and policies to ensure they align with your security posture.
Handling Sensitive Data in Lambda Functions
Handling sensitive data requires extra caution. Encryption protects data both at rest and in transit. Serverless functions integrate with AWS Secrets Manager and AWS Systems Manager Parameter Store, enabling secure storage and retrieval of sensitive information such as API keys and database credentials.
Additionally, avoid logging sensitive data and consider using custom logging solutions to ensure sensitive information does not appear in logs.
By implementing these security practices, you can safeguard your AWS Lambda functions and maintain a robust security posture in your serverless architecture.
Closing Statements
It revolutionises serverless computing by allowing developers to run code responding to events without managing servers. Its key features, such as automatic scaling and pay-as-you-go pricing, make it a powerful tool for modern application development. By integrating Lambda with other AWS services, developers can build scalable, efficient, cost-effective applications with minimal operational overhead.
Frequently Asked Questions
What is AWS Lambda?
It is a serverless computing service that allows you to run code without managing servers. It automatically handles infrastructure tasks such as scaling and availability. Lambda triggers your code in response to events like HTTP requests or file uploads, providing a scalable, cost-effective solution.
How do AWS Lambda Functions Work?
These functions are small code units that execute in response to events, such as HTTP requests or file uploads. They run in a stateless environment, meaning each invocation is independent. Lambda handles scaling and infrastructure, allowing you to focus solely on writing code for specific tasks.
What are the Key Benefits of Using AWS Lambda?
It offers automatic scaling, which adjusts resources based on demand without manual intervention. Its pay-as-you-go pricing model ensures you only pay for the computing time used. Additionally, it eliminates server management tasks, making it a cost-effective and efficient choice for event-driven applications.
Authors
-

Written by:
Julie BowieReviewed by: