
Summary: Depth First Search (DFS) is a fundamental algorithm used for traversing tree and graph structures. It explores as far down each branch as possible before backtracking. DFS is widely applied in pathfinding, puzzle-solving, cycle detection, and network analysis, making it a versatile tool in Artificial Intelligence and computer science.
Introduction
Depth First Search (DFS) is a fundamental algorithm in Artificial Intelligence and computer science, primarily used for traversing or searching tree and graph data structures. It explores as far as possible along each branch before backtracking, making it particularly useful in various applications, including pathfinding, puzzle-solving, and network analysis.
This blog will delve into the workings of DFS, its properties, applications, and best practices for implementation.
What is Depth First Search?
Depth First Search (DFS) is a fundamental algorithm use in Artificial Intelligence and computer science for traversing or searching tree and graph data structures.
This algorithm explores as far down a branch as possible before backtracking, making it particularly useful for various applications such as pathfinding, puzzle-solving, and network analysis. Here’s a detailed breakdown of how DFS operates.
Basic Principles of DFS
- Starting Point: DFS begins at a root node (or any arbitrary node in the case of a graph).
- Exploration: The algorithm explores as far as possible along each branch before backtracking. This means it will follow one path until it can go no further.
- Backtracking: When a dead end reached (i.e., a node with no unvisited adjacent nodes), the algorithm backtracks to the most recent node that has unexplored neighbours.
- Termination: The process continues until all nodes visited or a specific condition is met (such as finding a target node).
Explore More: Local Search Algorithms in Artificial Intelligence
How DFS Works
Step 1: Initialization: Start at the root node (or any arbitrary node in the case of a graph).
Step 2: Visit Node: Mark the current node as visited.
Step 3: Explore Neighbours: For each unvisited neighbour of the current node:
Step 4: Recursively apply DFS on that neighbour.
Step 5: Backtrack: If all neighbours are visited, backtrack to the previous node.
Step 6: Termination: The process continues until all nodes are visited or a specific condition is met (e.g., finding a target node).
Pseudocode for DFS
Here’s a simple pseudocode representation of the DFS algorithm:

Example Walkthrough
Consider a simple graph represented as follows:

- Start at node A, mark it as visited.
- Move to B, mark it as visited.
- Move to D, mark it as visited. D has no unvisited neighbours; backtrack to B.
- From B, move to E, mark it as visited. E has no unvisited neighbours; backtrack to B, then backtrack to A.
- From A, move to C, mark it as visited.
- Move to F, mark it as visited.
The traversal order would be A → B → D → E → C → F.
Key Characteristics of Distributed File Systems (DFS)

Distributed File Systems (DFS) are design to provide a unified file storage solution across multiple machines or nodes in a network. Here are the primary characteristics that define DFS:
Location Transparency
Users access files as if they are store locally, regardless of their actual physical location. This achieved through a namespace that abstracts the underlying structure of the file system, allowing clients to interact with files without needing to know where they reside.
Redundancy and Replication
DFS often replicates files across multiple servers to enhance data availability and fault tolerance. This means that even if one server fails, copies of the data remain accessible from other nodes, ensuring continuous access.
Scalability
Organisations can easily scale their DFS by adding more storage nodes or servers without disrupting existing services. This characteristic allows businesses to expand their storage capabilities in line with growing data needs.
High Availability
DFS systems designed to maintain functionality even during partial system failures. The replication of data ensures that users can still access files even if some nodes are down, thus improving overall system reliability.
Access Transparency
Users experience seamless access to files, as the system hides the complexities of how data distributed across various servers. This includes features like coherent access, where changes made to files are instantly visible across the network.
Metadata Management
Many DFS architectures include dedicated metadata servers that manage information about file attributes, access controls, and the mapping between logical names and physical locations. This centralization aids in efficient file management and coordination.
Caching Mechanisms
To improve performance, DFS often employs caching strategies that store frequently accessed files closer to users, reducing latency and network load during file retrieval operations.
Support for Multiple Protocols
DFS can utilise various file-sharing protocols such as SMB (Server Message Block) and NFS (Network File System), allowing diverse operating systems and applications to interact with the file system seamlessly.
Security Features
Security is a critical aspect of DFS, with mechanisms in place for encryption of data both at rest and in transit, ensuring protection against unauthorised access and data breaches24.
File Locking Mechanisms
To prevent conflicts during concurrent access by multiple users, DFS implements file locking mechanisms that ensure only one user can modify a file at any given time, maintaining data integrity.
Applications of DFS in Artificial Intelligence
Distributed File Systems (DFS) play a significant role in enhancing the capabilities of Artificial Intelligence (AI) applications. Here are some key applications:
Data Management and Storage
AI models require vast amounts of data for training and inference. DFS provides a scalable and efficient way to manage unstructured data across multiple nodes, ensuring that AI applications can access and process large datasets without bottlenecks.
This is crucial for tasks such as Natural Language Processing and image recognition, where data diversity and volume are essential.
High Availability and Redundancy
In AI applications, especially those deployed in production environments, high availability is critical. DFS ensures that data remains accessible even if some nodes fail, allowing AI systems to continue functioning without interruptions.
This redundancy is vital for real-time AI applications, such as autonomous vehicles or healthcare monitoring systems.
Collaborative AI Development
DFS facilitates collaboration among teams working on AI projects by providing a unified namespace for data storage. Multiple users can access and modify datasets simultaneously without conflicts, streamlining the development process of AI models.
This is particularly useful in environments where data scientists and engineers need to share large datasets or model outputs.
Efficient Data Retrieval
AI algorithms often require quick access to data for training and inference. DFS optimises data retrieval through caching mechanisms and load balancing across nodes, ensuring that AI applications can quickly access the latest information. This efficiency is crucial for applications like real-time analytics or recommendation systems.
Support for Big Data Frameworks
Many modern AI applications leverage big data frameworks like Apache Hadoop or Spark, which can be integrated with DFS. This integration allows for distributed processing of large datasets, making it easier to train complex models on massive amounts of data while maintaining performance.:
Implementing DFS
Let’s look at how you might implement the DFS algorithm in Python:
In this example, we define a simple graph using an adjacency list and perform a depth-first traversal starting from node ‘A’.
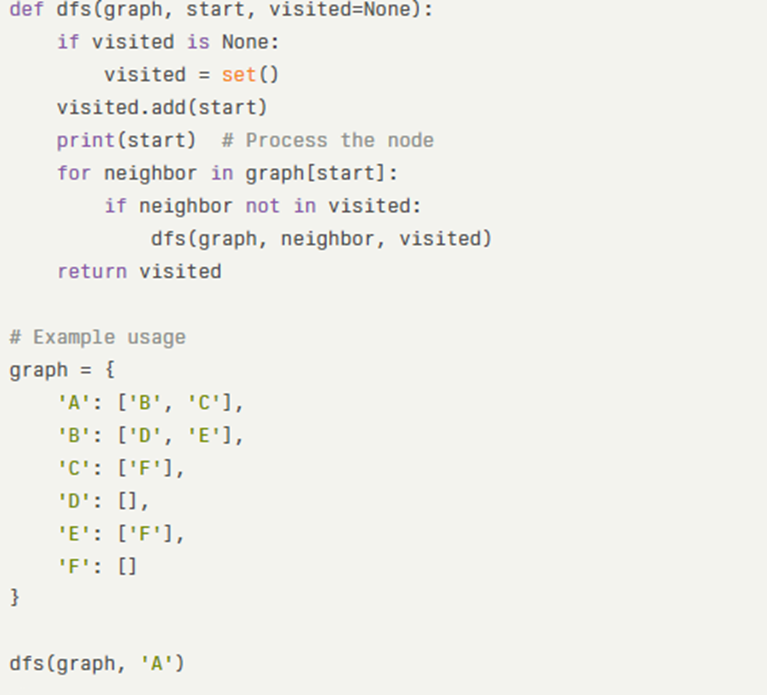
In this example, we define a simple graph using an adjacency list and perform a depth-first traversal starting from node ‘A’.
Best Practices for Implementing DFS
Implementing a Distributed File System (DFS) effectively requires careful planning and adherence to best practices. By following these best practices, organisations can implement a robust DFS that meets their operational needs while ensuring security, performance, and scalability.
- Track Visited Nodes: Always maintain a record of visited nodes to prevent infinite loops and redundant processing.
- Use Iterative Approach When Necessary: For very deep trees or graphs, consider using an iterative approach with an explicit stack instead of recursion to avoid stack overflow errors.
- Optimise Data Structures: Choose appropriate data structures for your graph representation (e.g., adjacency lists vs. matrices) based on your specific use case.
- Consider Edge Cases: Be mindful of edge cases such as disconnected graphs or empty graphs during implementation.
- Test Thoroughly: Validate your implementation with various test cases to ensure correctness and efficiency.
Conclusion
Depth First Search (DFS) is an essential algorithm in Artificial Intelligence and computer science that provides powerful capabilities for exploring tree and graph structures deeply before backtracking.
Its versatility allows it to applied across various domains—from pathfinding and puzzle-solving to network analysis and maze generation. Understanding its mechanics, advantages, disadvantages, and best practices can help developers effectively utilize this algorithm in their projects.
Frequently Asked Questions
What is Depth First Search (DFS)?
Depth First Search (DFS) is an algorithm used for traversing or searching tree or graph data structures by exploring as far down each branch as possible before backtracking to explore other branches.
What are the Main Applications Of DFS?
DFS has applications in pathfinding, puzzle solving (like Sudoku), topological sorting in directed acyclic graphs (DAGs), cycle detection in graphs, maze generation, and network analysis for exploring connectivity.
How Does DFS Differ from Breadth First Search (BFS)?
DFS explores nodes deeply along one branch before backtracking, while BFS explores all neighbours at the present depth prior to moving on to nodes at the next depth level—making BFS generally more suitable for finding shortest paths.
Authors
-

Written by:
Aashi VermaReviewed by:


