Summary: Classifier in Machine Learning involves categorizing data into predefined classes using algorithms like Logistic Regression and Decision Trees. It’s crucial for applications like spam detection, disease diagnosis, and customer segmentation, improving decision-making and operational efficiency across various sectors.
Introduction
Machine Learning has revolutionized how we process and analyse data, enabling systems to learn patterns and make predictions. One of the most fundamental tasks in Machine Learning is classification, which involves categorizing data into predefined classes.
Think of it as sorting mail into different bins—letters, packages, and junk mail. Classifiers are algorithms designed to perform this task efficiently, helping industries solve problems like spam detection, fraud prevention, and medical diagnosis.
Classification is a subset of supervised learning, where labelled data guides the algorithm to make predictions. For example, a classifier trained on labelled emails (spam or not spam) can predict whether a new email belongs to the spam category.
This blog explores types of classification tasks, popular algorithms, methods for evaluating performance, real-world applications, and why classifiers are indispensable in Machine Learning.
Key Takeaways
- Binary Classification Simplifies Decisions: Effective for spam detection and fraud prevention.
- Multi-Class Classification Enhances Accuracy: Ideal for image recognition and species identification.
- Multi-Label Classification Handles Complexity: Useful for movie genre and image tagging tasks.
- Imbalanced Classification Requires Special Techniques: Oversampling and ensemble methods improve accuracy.
Importance of Classification
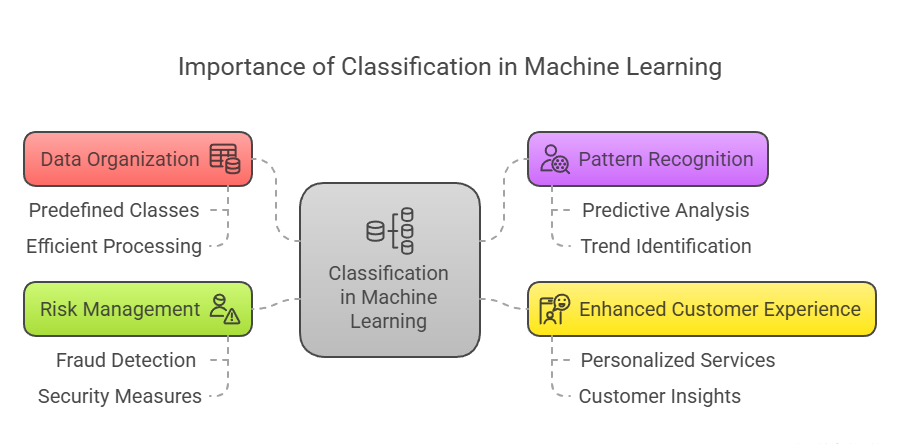
Classification is a fundamental concept in Machine Learning that plays a crucial role in various industries and applications. Its importance stems from its ability to categorize data into predefined classes, enabling more efficient decision-making processes and insights extraction. Here’s a detailed exploration of the importance of classification in Machine Learning:
Data Organization and Decision Making
Classification algorithms help organize vast amounts of data into meaningful categories. This organization is essential for:
- Streamlined Decision Making: By categorizing data, businesses can make faster and more accurate decisions. For example, in customer segmentation, classification can help identify which customers are likely to churn, allowing companies to take proactive retention measures.
- Automation of Complex Tasks: Classification enables the automation of tasks that would be time-consuming or impossible to do manually. For instance, email services use classification to automatically filter spam, saving users significant time and effort.
Pattern Recognition and Prediction
Classification algorithms excel at recognizing patterns in data, which is crucial for:
- Predictive Analytics: By learning from historical data, classification models can predict future outcomes. This is particularly valuable in fields like finance for fraud detection or in healthcare for disease diagnosis.
- Anomaly Detection: Classification can identify unusual patterns or outliers in data, which is essential for detecting fraudulent activities in banking or identifying manufacturing defects.
Enhanced Customer Experience
Classification algorithms contribute significantly to improving customer experiences:
- Personalization: By classifying customer preferences and behaviours, businesses can offer personalized recommendations, enhancing customer satisfaction and potentially increasing sales.
- Customer Support: Classification can be used in chatbots and support systems to categorize customer queries and route them to the appropriate department or provide instant responses.
Risk Management and Security
In the realm of risk assessment and security, classification plays a vital role:
- Credit Risk Assessment: Financial institutions use classification to categorize loan applicants based on their creditworthiness, helping to minimize the risk of defaults.
- Cybersecurity: Classification algorithms can identify potential security threats by categorizing network traffic or user behaviours, enhancing overall system security.
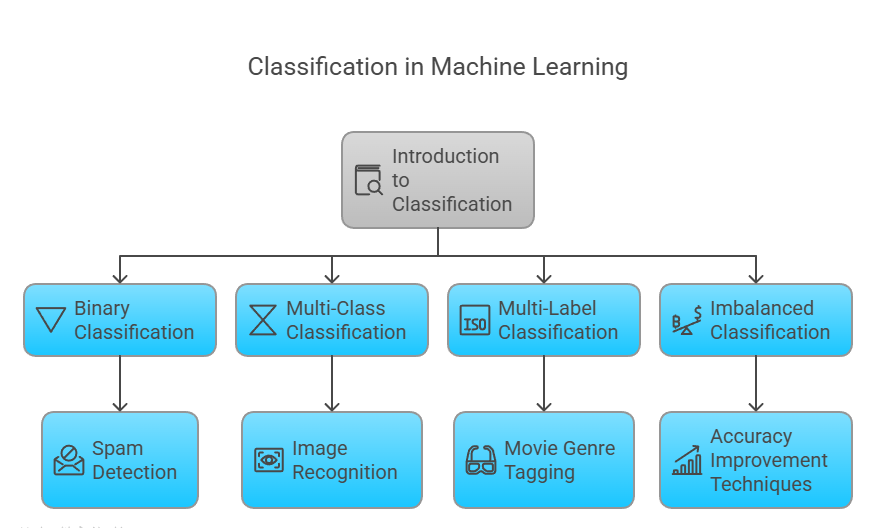
Types of Classification in Machine Learning
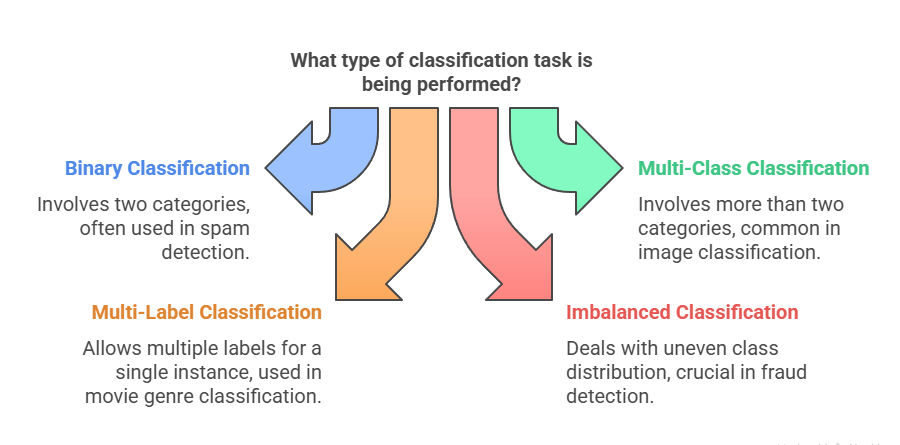
Classification is a fundamental task in Machine Learning where algorithms learn to assign predefined categories or labels to input data. There are several types of classification tasks in Machine Learning, each with its own characteristics and applications. Here are the main types of classification:
Binary Classification
Binary classification involves categorizing data into two mutually exclusive classes. Examples include:
- Spam vs. Not Spam
- Disease Positive vs. Negative
- Fraudulent Transaction vs. Legitimate Transaction
Popular algorithms for binary classification include Logistic Regression, Support Vector Machines (SVM), and Decision Trees.
Example: Spam Detection
In email services, binary classification is used to filter out spam emails. The model is trained on labeled data (spam or not spam) and predicts whether a new email is spam based on features like keywords and sender reputation.
Multi-Class Classification
Multi-class classification deals with problems involving more than two classes. Each instance is assigned to one of several predefined categories. Examples include:
- Classifying species of plants
- Categorizing images into animals, vehicles, or landscapes
Algorithms like Random Forests, Naive Bayes, and K-Nearest Neighbors (KNN) are commonly used for multi-class classification.
Example: Image Classification
In image recognition tasks, multi-class classification is used to categorize images into different classes like animals, vehicles, or buildings. This is crucial for applications like self-driving cars and surveillance systems.
Multi-Label Classification
In multi-label classification, data points can belong to multiple categories simultaneously. Examples include:
- Tagging a movie with multiple genres (action, comedy)
- Identifying multiple objects in an image (car, pedestrian)
Algorithms such as Multi-label Decision Trees and Gradient Boosting are suitable for this task.
Example: Movie Genre Classification
A movie might belong to both action and comedy genres. Multi-label classification helps in assigning multiple genres to a movie based on its content.
Imbalanced Classification
Imbalanced classification occurs when one class significantly outweighs others in terms of frequency. This imbalance can lead to biased predictions if not handled properly. Examples include:
- Rare disease detection
- Fraud detection in transactions
Techniques like oversampling minority classes or using ensemble methods help address this challenge.
Example: Fraud Detection
In credit card transactions, fraudulent transactions are much less common than legitimate ones. To improve detection accuracy, techniques like oversampling or cost-sensitive learning are used.
Popular Classifier Algorithms in Machine Learning
Classifier algorithms are at the heart of Machine Learning models. Here are some widely used ones:
Logistic Regression
A simple yet effective algorithm for binary classification that predicts probabilities using a logistic function.
Example: Predicting Customer Churn
Logistic Regression is often used to predict whether a customer will churn based on historical data like usage patterns and billing information.
Decision Trees
Decision Trees split data into subsets based on feature values, creating a tree-like structure for classification.
Example: Credit Risk Assessment
Decision Trees are used in credit scoring to assess the risk of lending based on factors like income, credit history, and loan amount.
Random Forest
An ensemble method that combines multiple decision trees to improve accuracy and reduce overfitting.
Example: Medical Diagnosis
Random Forests are used in medical diagnosis to predict diseases based on symptoms and patient history, combining multiple decision trees for better accuracy.
Support Vector Machines (SVM)
SVM finds the optimal hyperplane that separates classes with maximum margin.
Example: Text Classification
SVM is effective in text classification tasks like spam detection due to its ability to handle high-dimensional data.
K-Nearest Neighbors (KNN)
KNN assigns class labels based on the majority vote of nearest neighbors in the dataset.
Example: Product Recommendation
KNN is used in product recommendation systems to suggest products based on the preferences of similar customers.
Naive Bayes
Naive Bayes assumes independence between features and calculates probabilities based on Bayes’ theorem.
Example: Spam Filtering
Naive Bayes widely used for spam filtering due to its simplicity and effectiveness with text data.
Neural Networks
Artificial Neural Networks use layers of interconnected nodes to learn complex patterns for classification tasks like image recognition.
Example: Image Recognition
Neural Networks are crucial in image recognition tasks, such as identifying objects in images for self-driving cars.
Evaluating Classifier Performance
Evaluating a classifier’s performance is crucial to ensure its effectiveness in solving real-world problems. Common metrics include:
- Accuracy: Measures the percentage of correctly classified instances out of all predictions.
- Precision: Indicates how many positive predictions were correct out of all predicted positives.
- Recall: Measures how many actual positives were correctly identified by the model.
- F1 Score: A harmonic mean of precision and recall that balances both metrics.
- ROC-AUC Curve: Shows the trade-off between true positive rate and false positive rate across different thresholds.
Applications of Classification in Real Life
Classification algorithms have indeed found widespread applications across various industries, revolutionizing decision-making processes and improving efficiency. Let’s explore these applications in detail:
Healthcare
In the healthcare sector, classification algorithms play a crucial role in disease diagnosis and patient outcome prediction. Classification models extensively used to analyze medical imaging data for cancer detection. For instance:
- MRI Scan Analysis: Deep learning models, particularly Convolutional Neural Networks (CNNs), are trained on large datasets of MRI scans to classify images as cancerous or non-cancerous. These models can detect subtle patterns that might be missed by human radiologists.
- Biopsy Sample Classification: Machine Learning algorithms like Support Vector Machines (SVMs) and Random Forests are used to analyze biopsy samples, classifying cells as malignant or benign based on features such as cell shape, size, and texture.
Finance
In the financial sector, classification algorithms primarily used for fraud detection and risk assessment. Banks and financial institutions use classification algorithms to detect fraudulent transactions. For example:
- Anomaly Detection: Machine Learning models, such as Isolation Forests or One-Class SVMs, are trained on historical transaction data to identify unusual patterns that may indicate fraud.
- Real-time Classification: As transactions occur, these models classify them as legitimate or potentially fraudulent based on factors like transaction amount, location, and time.
Marketing
In marketing, classification algorithms are extensively use for customer segmentation and personalization. Retailers use classification to segment customers based on purchase history and demographics to offer targeted promotions. For instance:
- K-Means Clustering: This algorithm often used to group customers into distinct segments based on their buying behavior, age, income, and other relevant factors.
- Decision Trees: These are used to classify customers into predefined segments, such as “high-value,” “medium-value,” or “low-value” customers, based on their historical data
Conclusion: Why Classifier are Essential in Machine Learning
Classifiers play a pivotal role in transforming raw data into actionable insights across industries like healthcare, finance, and marketing. By automating decision-making processes and improving accuracy, they enable businesses to optimize operations and enhance customer experiences effectively.
For industry-specific applications, choosing tailored classifier machine learning algorithms ensures better results—for instance, using neural networks for image-heavy tasks or decision trees for simpler datasets. Whether it’s detecting spam emails or diagnosing diseases, classifier are indispensable tools in the Machine Learning toolkit.
Frequently Asked Questions
What Is The Difference Between Binary And Multi-Class Classification?
Binary classification involves two categories (e.g., spam/not spam), while multi-class handles more than two categories (e.g., animal types).
How Can Imbalanced Datasets Affect Classifier Performance?
Imbalanced datasets can bias predictions toward majority classes; techniques like oversampling or ensemble methods address this issue effectively.
Which Classifier Is Best for Text-Based Tasks Like Sentiment Analysis?
Naive Bayes or Logistic Regression are ideal for text-based tasks due to their simplicity and efficiency with word frequencies or probabilities.
Authors
-

Written by:
Neha SinghReviewed by: