
Summary: Attention mechanism in Deep Learning enhance AI models by focusing on relevant data, improving efficiency and accuracy. Key types include soft, hard, and self-attention, which are widely applied in NLP, computer vision, and more. Despite challenges like computational costs, innovations like sparse attention expand applications across industries, shaping AI’s future.
Introduction
Deep Learning has revolutionised artificial intelligence, driving advancements in natural language processing, computer vision, and more. Its global market size, valued at USD 17.60 billion in 2023, is projected to surge to USD 298.38 billion by 2032, growing at a CAGR of 36.7% from 2024 to 2032.
Central to this growth is the attention mechanism in Deep Learning, a transformative innovation that mimics human focus to process complex data efficiently. This blog explores the evolution of Deep Learning, the significance of attention mechanisms, and their role in advancing AI applications, offering insights into their theory, applications, and future potential.
Key Takeaways
- Attention mechanisms revolutionise NLP, computer vision, and speech processing by enabling selective focus.
- Includes soft attention, hard attention, self-attention, and global vs. local attention.
- Attention handles long-range dependencies and parallelises computations, boosting AI performance.
- High computational costs and scalability remain hurdles, requiring ongoing innovations.
- Sparse and dynamic attention models promise scalability, expanding applications to healthcare and beyond.
What is an Attention Mechanism?
An attention mechanism in Deep Learning is a technique that enables models to focus on specific parts of input data, selectively emphasising important features while ignoring irrelevant ones. This concept mimics human attention, where we concentrate on certain details and overlook others based on context and importance.
Attention mechanisms have become a cornerstone in tasks like Natural Language Processing (NLP), computer vision, and speech recognition, significantly improving the efficiency and effectiveness of neural networks.
Key Intuition Behind Attention
The core intuition behind attention is to provide models with the ability to weigh different pieces of information dynamically. Instead of processing all input data uniformly, the attention mechanism learns to assign varying levels of importance (often called “attention weights”) to different input elements.
For example, in a machine translation task, the model might focus more on certain words in the source sentence crucial for generating the correct translation. This selective focus helps the model make better predictions by capturing complex relationships and dependencies in the data.
The mechanism allows the model to learn context-dependent importance, enhancing its ability to deal with long-range dependencies and complex structures, which traditional models struggle with. This flexibility makes attention a powerful tool in improving the performance of Deep Learning systems.
Types of Attention Mechanisms

In Deep Learning, attention mechanisms have revolutionised how models process sequential data, helping them focus on relevant parts of input sequences. Attention mechanisms can vary based on their structure and application. This section explores different types of attention mechanisms and their significance in modern neural network architectures.
Soft Attention vs. Hard Attention
Hard and soft attention are the two primary types of attention mechanisms, differentiated by how they focus on different input parts.
Soft attention is a differentiable mechanism, meaning the attention weights are assigned probabilistically. These weights indicate the importance of each input token in the context of the entire sequence.
The model smoothly attends to various input parts, allowing gradients to flow through the attention mechanism during backpropagation. This makes it suitable for end-to-end training and is often used in models like Transformers and RNNs.
In contrast, hard attention selects a discrete subset of input tokens by making a “hard” decision on which tokens to attend to, essentially using sampling or gating mechanisms.
Since hard attention is non-differentiable, it is often trained using reinforcement learning techniques or Monte Carlo methods. Although harder to train, hard attention can be more efficient sometimes, particularly when focusing on only a few crucial tokens.
Self-Attention
Self-attention is a mechanism where the model attends to different parts of the same input sequence. Unlike traditional attention mechanisms that rely on an encoder-decoder structure, self-attention allows each token to consider all other tokens in the sequence to determine its relevance.
This mechanism is widely used in Transformer models, where each word or token interacts with all other tokens, capturing dependencies regardless of distance.
Self-attention is highly parallelisable, which speeds up training and inference, making it particularly effective for tasks like language translation, document summarisation, and other NLP applications. This mechanism enables the model to capture long-range dependencies without being constrained by the sequential nature of RNNs.
Global vs. Local Attention
Global and local attention refers to the scope of the input the model attends to at any given time.
In global attention, the model can attend to the entire input sequence for each token. This approach allows the model to capture long-range dependencies, as each output element is connected to all input tokens. However, it can be computationally expensive, especially for long sequences.
Local attention restricts the model’s focus to a smaller window of the input sequence. It only attends to a subset of the sequence, reducing the computational cost significantly. Local attention is useful when the important context is likely within a localised sequence region, such as speech or image processing tasks.
While it reduces the computational burden, local attention may miss global dependencies, making it more suitable for tasks where localised features dominate.
Mathematics Behind Attention
Attention mechanisms are based on mathematical principles that enable models to focus on important parts of the input data. These functions calculate attention weights, determining how much focus should placed on each input element. Let’s break down the key components: scoring functions and calculating attention weights.
Scoring Functions
The core of attention mechanisms lies in scoring functions, which assign a relevance score to the relationship between different input sequence elements. Two common types of scoring functions are:
- Dot-Product Scoring: In this approach, the attention score computed by taking the dot product of the query vector (Q) and the key vector (K). The dot product measures how similar the two vectors are. The formula can written as:
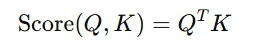
The higher the score, the more attention the model will give to the corresponding element.
- Additive Scoring: In additive attention, the score computed by applying a learnable weight matrix to concatenate the query and key vectors. This scoring function is expressed as:
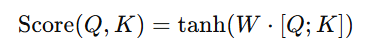
- W is a weight matrix, and [Q;K] is the query and key vectors concatenation. This function introduces a non-linearity, allowing the model to learn more complex relationships between the inputs.
Calculation of Attention Weights
Once the scores are computed, they must be converted into attention weights. This is done using the softmax function, which normalises the scores into a probability distribution. The attention weight for a given element is calculated as:
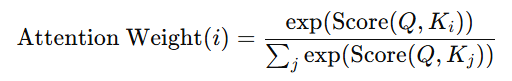
These weights determine how much each input contributes to the output. Higher weights indicate more relevance, guiding the model’s attention to the most important parts of the input sequence.
By calculating these attention weights dynamically, the model can selectively focus on the most relevant information, improving its performance on tasks like translation, summarisation, and more.
Applications of Attention Mechanisms
Attention mechanism have significantly improved the performance of various Deep Learning tasks. Attention has revolutionised fields like Natural Language Processing, Computer Vision, and Speech Processing by enabling models to focus on relevant input parts.
Natural Language Processing (NLP)
In NLP, attention mechanisms help models focus on important words in a sentence, enhancing tasks like machine translation, text summarisation, and question answering. It allows for better context understanding across long sequences.
Computer Vision
In Computer Vision, attention mechanisms highlight critical areas of an image, improving object detection, image captioning, and segmentation tasks.
Speech Processing
Attention mechanisms focus on crucial audio segments for speech recognition and synthesis, improving accuracy in transcribing speech and generating natural-sounding speech.
Attention Mechanisms in Transformers

In Deep Learning, Transformer models have revolutionised natural language processing (NLP) tasks and beyond. A core component driving their success is the attention mechanism, which allows the model to weigh different parts of the input data based on their relevance.
This mechanism enables Transformer models to process input sequences in parallel and capture long-range dependencies, making them highly efficient and effective for tasks like language translation, text generation, and image processing.
The Role of Attention in Transformer Models
In Transformer models, attention mechanisms allow each token (word or element) in the input sequence to focus on other tokens when generating the output. Unlike traditional models like Recurrent Neural Networks (RNNs), which process data sequentially, attention-based models can process all tokens simultaneously, making them faster and more scalable.
The attention mechanism computes a weighted sum of all tokens in the sequence based on their relevance to the current token, allowing the model to focus on important contexts while ignoring less relevant information. This process repeated for each token in the input, producing a richer and more context-aware representation.
Multi-Head Attention
One of the key innovations in Transformers is multi-head attention. Instead of using a single attention mechanism, the model employs multiple attention heads that work in parallel. Each attention head learns a different representation of the input data by focusing on various sequence parts.
The outputs from all the attention heads are then concatenated and transformed to generate a final, comprehensive representation of the sequence. This approach allows the model to capture a wider range of dependencies and learn complex relationships within the data.
Multi-head attention enables the Transformer to capture local patterns and understand more abstract, global dependencies, making it a potent tool for complex tasks like language understanding, machine translation, and even image captioning.
Advantages and Limitations
Attention mechanism have revolutionised Deep Learning, especially in Natural Language Processing (NLP) and Computer Vision. However, as with any technology, they come with their own set of advantages and limitations.
Benefits of Using Attention Mechanisms
One of the key benefits of attention mechanisms is their ability to focus on the most relevant parts of the input data. This selective focus allows models to process large inputs more efficiently by prioritising important features.
In NLP, attention enables models to handle long-range dependencies within sentences, improving translation accuracy and text generation. In Computer Vision, attention mechanisms enhance the model’s ability to concentrate on key areas in an image, leading to better object recognition and segmentation.
Additionally, the ability to parallelise computations is another advantage, particularly in Transformer-based models, where attention allows for faster training times by processing all inputs simultaneously.
Challenges and Computational Costs
Despite their benefits, attention mechanisms come with computational overhead. Calculating attention scores for each input token involves matrix multiplications, which increases both time and space complexity, especially for large datasets. This can result in slower model training and inference times.
Moreover, handling very long sequences or high-dimensional data can lead to memory bottlenecks. The need for extensive data and powerful hardware resources makes scaling attention-based models a significant challenge in real-world applications.
Future Directions
The field of attention mechanisms continues to evolve rapidly, with ongoing research introducing innovative approaches and new applications across various domains. As Deep Learning models grow in complexity, attention mechanisms expected to further enhance model performance and efficiency.
Innovations in Attention Mechanisms
Recent advancements in attention mechanisms include the development of sparse attention models, which aim to reduce the computational burden by focusing on the most relevant parts of the input.
Techniques like Linformer and Longformer have emerged, utilising low-rank approximations to efficiently handle long sequences in NLP tasks. Additionally, researchers are exploring dynamic attention, where attention weights are not fixed but adapt during training, allowing for more flexible and context-sensitive interactions.
Potential Areas for Application and Improvement
The application of attention mechanisms is expanding beyond NLP and computer vision. Healthcare is a promising area where attention mechanisms can applied to analyse medical images, predict patient outcomes, and personalise treatment plans. Moreover, attention is making strides in reinforcement learning, which can help focus on relevant environmental features to improve decision-making.
While attention models have made significant progress, further research needed to address issues like scalability and interpretability, especially when dealing with large-scale datasets and complex real-world problems. Optimising these areas will unlock new capabilities for AI systems across industries.
In The End
The attention mechanism in Deep Learning has transformed how AI models process complex data, driving advancements in NLP, computer vision, and more. Attention mechanisms enabling selective focus improve model efficiency, scalability, and accuracy.
Despite challenges like computational costs, innovations like sparse and dynamic attention offer promising solutions. As applications expand into areas like healthcare and reinforcement learning, attention mechanisms will play a pivotal role in shaping the future of AI.
Their ability to handle long-range dependencies and parallel processing ensures their continued relevance in tackling real-world challenges and advancing AI’s potential across industries.
Frequently Asked Questions
What is an Attention Mechanism in Deep Learning?
An attention mechanism allows models to focus on important input features while ignoring irrelevant ones. It dynamically assigns attention weights, improving tasks like machine translation, summarisation, and image processing by capturing context-dependent relationships.
Why are Attention Mechanisms Important in Deep Learning?
Attention mechanisms enhance model performance by enabling selective focus, handling long-range dependencies, and improving efficiency. They are crucial for NLP, computer vision, and speech processing tasks, allowing models to prioritise contextually relevant input data.
What are the Types of Attention Mechanisms?
Types include soft attention (differentiable and end-to-end trainable), hard attention (non-differentiable, using reinforcement learning), self-attention (used in Transformers), and global vs. local attention, depending on the scope of focus.
Authors
-

Written by:
Sam WaterstonReviewed by:



