
Summary: Abstract Data Type (ADTs) are crucial in computer science, defining data types by their operations rather than implementation. This abstraction simplifies programming, promotes modularity, and enhances code maintainability. Common examples include lists, stacks, queues, maps, and sets, each providing specific functionalities while hiding underlying complexities from users.
Introduction
Abstract Data Types (ADTs) are a fundamental concept in computer science that provide a way to define data structures based on the operations that can be performed on them, rather than their implementation details.
This abstraction allows programmers to focus on what operations are available, without needing to understand how those operations are implemented.
In this blog post, we will explore the definition of ADTs, their characteristics, common examples, and their significance in programming.
Key Takeaways
- ADTs define data types by operations rather than implementation details.
- They promote modularity and encapsulation in software design.
- Common ADTs include lists, stacks, queues, maps, and sets.
- ADTs enhance code maintainability and flexibility for developers.
- Understanding ADTs simplifies complex programming tasks significantly.
What are Abstract Data Types?
An Abstract Data Type is a mathematical model that defines a data type purely by its behaviour from the point of view of a user, specifying the operations that can be performed on it and the semantics of those operations.
The actual implementation of these operations is hidden, which means users do not need to know how these operations are executed internally. This separation of interface and implementation is what makes ADTs powerful and flexible.
For instance, consider a List ADT. Users can perform operations like adding an element, removing an element, or accessing an element at a specific index. However, the underlying structure (whether it is an array or a linked list) is abstracted away from the user.
Characteristics of ADTs
Abstract Data Types (ADTs) are a crucial concept in computer science, providing a framework for defining data structures based on their behaviour rather than their implementation. Understanding the characteristics of ADTs is essential for effective programming and software design. Here are the key characteristics of Abstract Data Types:
Abstraction
ADTs provide a level of abstraction that separates the definition of operations from their implementation. Users interact with the data type through a defined interface, which specifies what operations can be performed, such as adding or removing elements, without needing to understand how these operations are executed internally.
Encapsulation
Encapsulation is a fundamental principle of ADTs that involves hiding the internal details of the data structure. This means that users cannot access or modify the data directly; instead, they must use the provided operations.
This not only protects the integrity of the data but also allows for easier maintenance and modification of the data structure as changes can be made without affecting users.
Data Structure Independence
ADTs are designed to be independent of any specific data structure. This means that an ADT can be implemented using various underlying structures (e.g., arrays, linked lists) without altering its functionality.
For example, a stack can be implemented using either an array or a linked list, but it will still provide the same interface and behaviour to users.
Modularity
ADTs promote modularity in programming by allowing developers to create complex data structures from simpler ones. Different ADTs can be combined to form more intricate structures, enabling greater flexibility in software design. This modularity facilitates code reuse and makes it easier to manage large codebases.
Information Hiding
Information hiding is closely related to encapsulation and refers to restricting access to certain details of the implementation while exposing only what is necessary for users to interact with the ADT. This characteristic helps prevent unintended interference with the data structure and reduces the likelihood of errors during usage.
Robustness
ADTs contribute to robustness in programming by providing clear interfaces and well-defined operations. This structure allows for better error handling and validation within the operations, making programs less prone to bugs and unexpected behaviours.
Better Conceptualisation
By abstracting away implementation details, ADTs allow for better conceptualisation of real-world entities within a program. Developers can model complex systems more intuitively, aligning their code with real-world processes and objects.
Flexibility
Since ADTs define only what operations are available without dictating how they should be implemented, they offer significant flexibility in terms of implementation choices. Developers can choose different algorithms or data structures based on performance needs or other criteria while maintaining the same interface for users
Common Examples of Abstract Data Types

Abstract Data Types (ADTs) are essential constructs in computer science that define a data type purely by the operations that can be performed on it, rather than by its implementation. Here are some common examples of ADTs, along with their characteristics and typical operations.
List
A list is an ordered collection of elements, where each element can be accessed by its position (index).
Operations:
- insert(index, value): Inserts a value at a specified index.
- remove(index): Removes the element at the specified index.
- get(index): Retrieves the value at the specified index.
- size(): Returns the number of elements in the list.
Implementations: Lists can implemented using arrays or linked lists.
Stack
A stack is a collection that follows the Last In, First Out (LIFO) principle, meaning the last element added is the first one to removed.
Operations
- push(value): Adds a value to the top of the stack.
- pop(): Removes and returns the top value from the stack.
- peek(): Returns the top value without removing it.
- isEmpty(): Checks if the stack is empty.
Implementations: Stacks commonly implemented using arrays or linked lists.
Queue
A queue is a collection that follows the First In, First Out (FIFO) principle, meaning the first element added is the first one to removed.
Operations:
- enqueue(value): Adds a value to the end of the queue.
- dequeue(): Removes and returns the front value from the queue.
- front(): Returns the front value without removing it.
- isEmpty(): Checks if the queue is empty.
Implementations: Queues can implemented using arrays or linked lists.
Priority Queue
A priority queue is a collection where each element has a priority associated with it. Elements are remove based on priority rather than order of insertion.
Operations
- enqueue(value, priority): Adds a value with an associated priority.
- dequeue(): Removes and returns the element with the highest priority.
- peek(): Returns the highest priority element without removing it.
Implementations: Priority queues are often implemented using heaps or balanced trees.
Map (or Dictionary)
A map is a collection of key-value pairs where each key is unique and used to retrieve its corresponding value.
Operations
- put(key, value): Adds or updates a key-value pair in the map.
- get(key): Retrieves the value associated with a given key.
- remove(key): Removes the key-value pair associated with a given key.
Implementations: Maps can implemented using hash tables or balanced tree
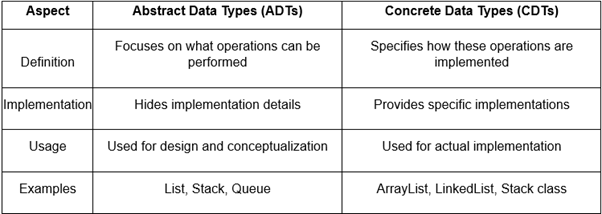
Differences Between ADTs and Concrete Data Types
While ADTs define what operations can performed on data types, Concrete Data Types (CDTs) specify how these operations are implement. For example:
Importance of Abstract Data Types
Abstract Data Types (ADTs) are crucial in computer science and programming for several reasons. They provide a way to define data structures in a manner that abstracts away the implementation details, allowing developers to focus on the behaviour and properties of the data rather than how it implemented. Here are some key points highlighting their importance:
Encapsulation and Modularity
ADTs promote encapsulation by hiding the internal workings of data structures. This modularity allows developers to change the implementation without affecting other parts of the program that rely on the ADT. As a result, code becomes easier to maintain and extend.
Improved Code Reusability
By defining operations on data independently from their implementation, ADTs facilitate code reuse. Developers can use existing ADTs across different projects without needing to rewrite code, which enhances productivity and reduces errors.
Enhanced Abstraction
ADTs provide a higher level of abstraction, allowing programmers to work with complex data structures without needing to understand their underlying complexities. This abstraction simplifies problem-solving and enables developers to focus on algorithm design.
Clearer Interface Design
ADTs define clear interfaces for interacting with data structures, which helps in creating well-defined contracts between different components of a system. This clarity improves collaboration among teams and makes the codebase easier to understand.
Flexibility in Implementation
Different implementations of an ADT can be created based on performance needs or resource constraints. For instance, a list can be implemented as an array or a linked list depending on the specific requirements of an application. This flexibility allows for optimizing performance while maintaining a consistent interface.
Real-World Analogy
To understand ADTs better, consider using an ATM machine as an analogy. When you use an ATM, you interact with it through buttons and screens without needing to know how it processes your request or retrieves your money from the bank’s database.
The ATM represents an abstract interface; you know what actions you can perform (withdraw money, check balance), but not how those actions executed behind the scenes.
Conclusion
Abstract Data Type provide a powerful way to manage data structures by focusing on what operations can performed rather than how they are implemented. This abstraction allows developers to create flexible and reusable components in their software systems.
Understanding these common examples of ADTs—such as lists, stacks, queues, maps, and sets—enables programmers to choose appropriate data structures for their specific needs while maintaining clean and efficient code.
Frequently Asked Questions
What Is an Abstract Data Type (ADT)?
An Abstract Data Type (ADT) is a conceptual model that defines a data type based on the operations that can performed on it, without specifying how these operations are implemented. This abstraction allows developers to focus on functionality rather than implementation details.
What are the Benefits of Using ADTs?
Using ADTs promotes modularity, encapsulation, and flexibility in programming. They allow for easier maintenance and modification of code since the implementation can change without affecting how users interact with the data type, leading to more robust and reusable software components.
Can You Give Examples of Common ADTs
Common examples of ADTs include Lists, Stacks, Queues, Maps (Dictionaries), and Sets. Each of these types provides specific operations for managing data while abstracting away the underlying implementation details, allowing for various implementations such as arrays or linked lists.
Authors
-

Written by:
Julie BowieReviewed by:



