Summary: Cursors in SQL allow row-by-row data processing, essential for tasks requiring sequential logic. This guide covers cursor types in SQL Server, their lifecycle, practical examples, and performance optimization tips. Understand when to use cursors and how to minimize their resource overhead.
Introduction
Row-by-row processing is a fundamental requirement in many database applications, and the primary tool for this in SQL is the cursor. This comprehensive guide explores what a cursor in SQL is, how it works, its use in SQL Server, best practices, and performance considerations. Whether you are a beginner or an experienced developer, this post will help you understand when and how to use cursors effectively.
Key Takeaways
- Cursors enable sequential row processing for complex logic not feasible with set-based operations.
- SQL Server offers multiple cursor types (static, dynamic, keyset) for different use cases.
- Cursors have a six-step lifecycle: declare, open, fetch, process, close, deallocate.
- Minimize cursor use to avoid performance issues; prefer set-based operations.
- Optimize cursor performance by selecting efficient types and limiting loop operations.
What is a Cursor in SQL?
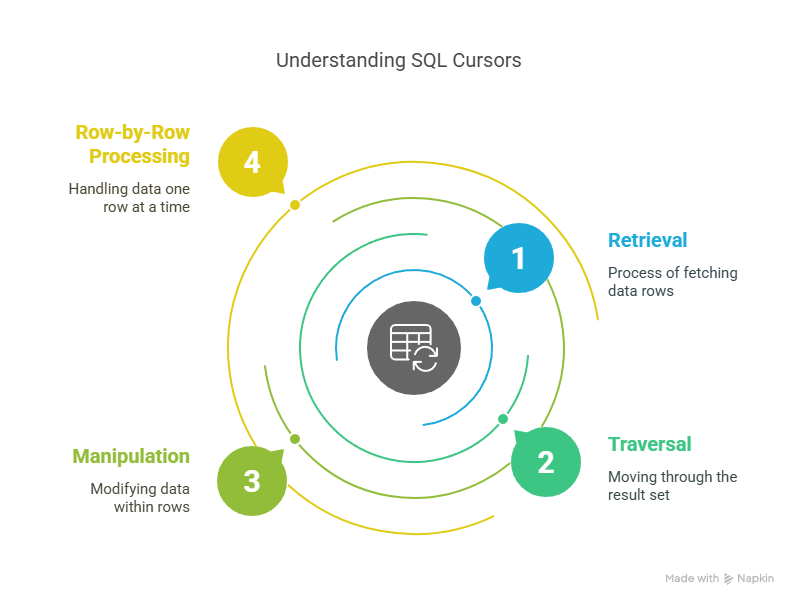
A cursor in SQL is a database object that enables you to retrieve, traverse, and manipulate rows in a result set one at a time. Unlike set-based operations, which handle entire collections of data at once, a cursor processes each row individually, making it ideal for scenarios where sequential, row-by-row logic is necessary.
Lifecycle of a Cursor in SQL

The typical lifecycle of a cursor in SQL consists of several key steps. Understanding these steps is crucial for writing robust and efficient cursor-based code.
1. Declare the Cursor
You define the cursor and associate it with a SELECT statement. This statement determines which rows the cursor will process.
Syntax (SQL Server)

2. Open the Cursor
Opening the cursor initializes it and populates the result set.

3. Fetch Data from the Cursor
You fetch rows one by one from the cursor, processing each row as needed.

4. Process the Data
Within a loop, you perform the required operations on each fetched row.

5. Close the Cursor
Closing the cursor releases the result set and any locks held.

6. Deallocate the Cursor
Deallocating the cursor frees up the resources associated with it.

Cursor in SQL Server: An In-Depth Look

A cursor in SQL Server is implemented using Transact-SQL (T-SQL) and follows the same lifecycle as described above. SQL Server provides several types of cursors, each with different characteristics and use cases.
SQL Server Cursor Example
A cursor in SQL Server is used to process query results row by row, which is useful when you need to apply logic or operations to each record individually.
Below is a step-by-step example demonstrating how to use a cursor in SQL Server to iterate through all user databases and perform an operation (such as backing up each database).
1: Declare Variables
First, declare the necessary variables to hold data from each row and for any processing logic.

2: Initialize Variables
Set values for variables that will be used in the process.

3: Declare the Cursor
Define the cursor with a SELECT statement to specify the data to iterate over. Here, we select all user databases except system databases.

4: Open the Cursor
5: Fetch the First Row

6: Loop Through the Result Set
Use a WHILE loop to process each row until all rows are handled.

7: Close and Deallocate the Cursor
Always close and deallocate the cursor to release resources.

Types of Cursors in SQL Server

SQL Server provides several types of cursors to handle row-by-row processing, each designed for specific scenarios and performance considerations. Understanding these cursor types helps you choose the best approach for your data manipulation needs.
Static Cursor
A static cursor takes a snapshot of the result set at the time the cursor is opened. This snapshot is cached and remains unchanged for the cursor’s lifetime, regardless of any modifications (INSERT, UPDATE, DELETE) made to the underlying data after the cursor is created.
Static cursors can move both forward and backward through the result set but are always read-only and typically slower due to higher memory usage.
Use static cursors when you need a stable, scrollable view of your data without reflecting real-time changes.
Dynamic Cursor
Dynamic cursors are the most flexible, reflecting all changes (inserts, updates, deletes) made to the underlying data while the cursor is open. As you scroll through the result set, it updates in real time.
Dynamic cursors support all types of data modifications and are useful when you need to work with the latest data. However, they can be resource-intensive due to the overhead of tracking changes.
Forward-Only Cursor
Forward-only cursors allow you to move only in one direction—from the first row to the last. They are the fastest and least resource-intensive cursor type, making them ideal for simple, one-way data processing tasks.
Forward-only cursors can reflect changes to the underlying data and support updates and deletes as you move through the result set. Variants like FAST_FORWARD offer even better performance for read-only, forward-only operations.
Keyset-Driven Cursor
Keyset-driven cursors use a set of unique keys (keyset) to identify rows in the result set. The keyset is determined when the cursor is opened.
Updates and deletes made by other users to the rows in the keyset are visible, but new rows added after the cursor is opened are not.
Keyset-driven cursors support scrolling and allow updates and deletes, but not inserts from other users
Conclusion
A cursor in SQL is a powerful tool for row-by-row processing, especially when set-based operations are insufficient. In SQL Server, cursors are widely used for administrative tasks and complex business logic that cannot be achieved with standard SQL statements.
However, given their performance impact, it is crucial to use them judiciously and optimize their implementation. By following best practices and understanding their lifecycle, you can harness the full potential of cursors while maintaining efficient database operations.
Frequently Asked Questions
What is a Cursor in SQL and When Should I Use It?
A cursor in SQL is a database object that enables row-by-row processing of query results. Use a cursor when you need to perform complex operations on each row individually and set-based SQL queries are insufficient12.
How do I Optimize Cursor Performance in SQL Server?
To optimize cursor performance, fetch only necessary data, use the most efficient cursor type (like FAST_FORWARD), minimize operations inside the loop, and always close and deallocate cursors after use.
Are There Alternatives to Using Cursors in SQL?
Yes, set-based operations like joins, subqueries, and window functions are often more efficient alternatives. Use cursors only when such approaches cannot meet your requirements.
Authors
-

Written by:
Neha SinghReviewed by: