
Summary: The Rectified Linear Unit (ReLU) is a crucial activation function in Deep Learning. It enables faster training, prevents the vanishing gradient problem, and improves the AI model’s efficiency. While it has limitations like the dying ReLU issue, variants like Leaky ReLU and PReLU help maintain neuron activity for optimal learning.
Introduction
When we build a neural network, we need a way to decide which information is essential and which is not. This is where activation functions come in. They help the network make decisions by passing valid data forward and blocking unnecessary details.
ReLU (Rectified Linear Unit) is a popular activation function. It plays a big role in Deep Learning because it makes neural networks faster and more efficient.
In this blog, we will briefly break down ReLU, explore how it works, and understand why it is widely used.
Key Takeaways
- ReLU accelerates Deep Learning by allowing positive values and setting negative values to zero.
- It prevents the vanishing gradient problem, ensuring efficient neural network training.
- ReLU outperforms Sigmoid and Tanh, making it the preferred activation function in AI.
- Variants like Leaky ReLU and PReLU address the dying ReLU problem by allowing small negative values.
- ReLU is widely used in AI applications, including image recognition, NLP, and self-driving cars.
Understanding Rectified Linear Unit (ReLU)
Artificial Intelligence has revolutionised industries, and one of its most powerful tools is neural networks. These networks are inspired by the way the human brain processes information. They consist of interconnected units, or neurons, that work together to recognise patterns, make predictions, and solve complex problems.
To function effectively, neural networks rely on activation functions—mathematical rules that decide whether a neuron should pass information forward. Think of them as traffic signals controlling the flow of data. The Rectified Linear Unit (ReLU) is widely used among these activation functions.
Why Is ReLU Popular in Neural Networks?
ReLU has gained massive popularity because it helps neural networks learn faster and perform better. Unlike older activation functions, such as sigmoid or tanh, which can slow down learning, ReLU allows networks to train efficiently by avoiding complex calculations.
Additionally, ReLU helps solve the vanishing gradient problem, a common issue in Deep Learning where information gets lost as it moves through layers. Using ReLU, neural networks can handle deep and complex structures while improving accuracy in tasks like image recognition, language processing, and self-driving cars.
Mathematical Representation of ReLU
Even though ReLU plays a crucial role in Deep Learning, its mathematical formula is surprisingly simple:
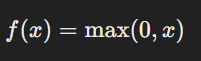
This means that:
- If the input (xxx) is positive, ReLU keeps it the same.
- If the input (xxx) is negative, ReLU sets it to zero.
For example:
- If x=5, then f(x)=5
- If x=−3, then f(x)=0
This straightforward rule allows neural networks to ignore negative values, making computations faster and more efficient.
Now that we understand the basics of ReLU, let’s explore how it works and its variants.
Mechanism of ReLU: How It Works
The Rectified Linear Unit (ReLU) is a simple mathematical function used in Artificial Intelligence to help computers learn from data. The ReLU function takes a number as input and decides whether to keep or change it. If the number is positive, ReLU keeps it as it is. If the number is negative, ReLU changes it to zero.
For example:
- If the input is 5, the output remains 5.
- If the input is -3, the output becomes 0.
This simple rule helps computers quickly process large amounts of information without getting stuck on unnecessary details.
Graphical Representation of ReLU
Imagine a simple graph where the horizontal axis represents input numbers and the vertical axis represents output numbers. The ReLU function creates an L-shaped curve:
- The line moves straight for positive numbers.
- The line flattens at zero for negative numbers.
This shape allows ReLU to pass useful information (positive numbers) while ignoring unnecessary data (negative numbers).
Comparison with Sigmoid and Tanh
Older activation functions like Sigmoid and Tanh work differently. The Sigmoid function turns all inputs into values between 0 and 1, while Tanh converts them between -1 and 1. These functions make learning slower because they reduce the impact of large numbers.
ReLU is faster and more efficient because it keeps large values unchanged and does not shrink them like Sigmoid or Tanh. Modern Deep Learning models prefer ReLU for solving complex problems like image recognition and language processing.
The Role of Activation Functions in Neural Networks
Activation functions act as decision-makers inside a neural network. They take the input data, process it, and decide whether to pass it forward. Think of them like a switch determining whether a signal is strong enough to continue. Without activation functions, neural networks would only recognise simple, straight-line patterns, making them ineffective for real-world problems.
Why Are Activation Functions Important?
Most real-world data is complex and does not follow simple rules. For example, how your expenses change when you have one child is different from how they change when you go from three to four children.
Activation functions help neural networks understand these non-linear relationships, allowing them to make better predictions in tasks like speech recognition, image processing, and financial forecasting.
Types of Activation Functions
- Linear Activation: This function is simple but limited. It can only capture direct relationships, such as how a pay raise affects savings.
- Sigmoid Function: Like a probability scale, it’s used in older networks and maps values between 0 and 1.
- Tanh Function: Similar to Sigmoid but ranges between -1 and 1, making it better for balanced data.
- ReLU (Rectified Linear Unit): The most widely used function activates only positive values, making learning faster and more efficient.
By using activation functions, neural networks can make sense of complex patterns, just like how the human brain processes different types of information.
Different Variants of ReLU
ReLU is one of the most widely used activation functions in Deep Learning. However, it doesn’t always work perfectly for every problem. To address its limitations, researchers have developed several improved versions of ReLU. Let’s explore the most popular ones.
Leaky ReLU: Solving the “Dying ReLU” Problem
ReLU has a significant drawback: it outputs zero for all negative inputs. This can cause some neurons to become inactive and stop learning, a problem known as the dying ReLU issue.
Leaky ReLU offers a simple fix. Instead of setting negative values to zero, it allows them to have a small negative slope. The function is defined as:
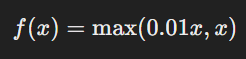
This means that the output is not entirely zero for negative inputs but a small fraction of the input. This helps keep neurons active and learning.
Parametric ReLU (PReLU): A More Flexible Approach
Leaky ReLU uses a fixed small value for negative inputs, but Parametric ReLU (PReLU) takes it further by making this value a learnable parameter. The function is:
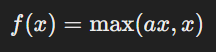
Here, “a” is a parameter that the model learns during training, making PReLU more adaptable to complex patterns in data. It is beneficial in areas like computer vision and speech recognition. However, the added flexibility comes with increased computational cost, requiring extra tuning and careful optimisation.
Exponential Linear Unit (ELU): Improving Learning Speed
Unlike ReLU, which outputs zero for negative values, Exponential Linear Unit (ELU) allows small negative values to help the model learn better. The function is:
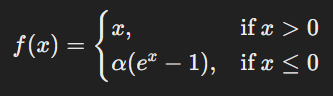
Here, α (alpha) is a hyperparameter that controls the curve of negative values. The advantage of ELU is that it helps the model learn faster and avoids the vanishing gradient problem by keeping activations closer to zero.
Scaled Exponential Linear Unit (SELU): Automatic Normalization
SELU is an advanced version of ELU that automatically normalises activations, ensuring the data flowing through a neural network remains stable. The function is similar to ELU but includes a scaling factor λ (lambda):
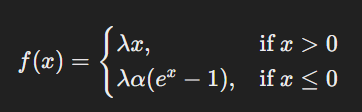
SELU works well with self-normalising networks, allowing Deep Learning models to train efficiently without batch normalisation.
Comparing ReLU and Its Variants
For your clear understanding, here is a table comparing ReLU and its variants.
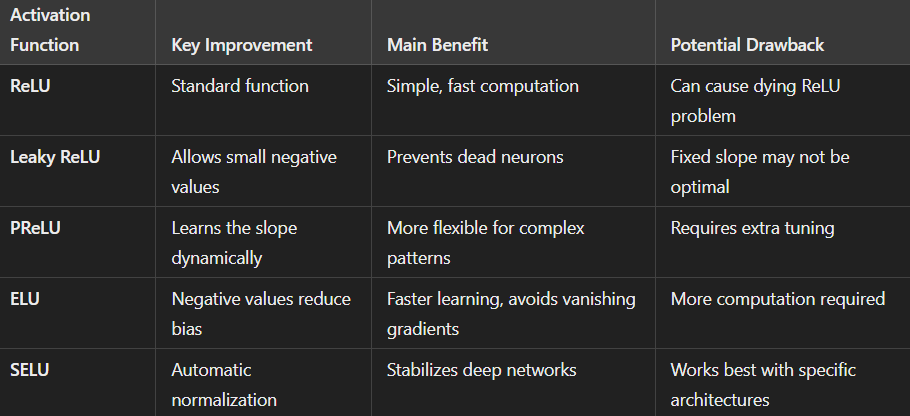
Each ReLU variant offers unique benefits. Choosing the right one depends on your problem and the complexity of your Deep Learning model.
Benefits of Using ReLU
The Rectified Linear Unit (ReLU) is one of the most widely used activation functions in Deep Learning. It is popular because it makes neural networks learn faster and work efficiently. Unlike some complex functions, ReLU is simple and helps solve common problems in training Deep Learning models. Here’s why ReLU is beneficial:
Easy to Use and Fast to Compute
ReLU performs a simple operation—if the input is positive, it remains the same; if it is negative, it becomes zero. This makes ReLU easy to implement and much faster than functions like Sigmoid or Tanh, which involve complex calculations.
Speeds Up Learning
Neural networks using ReLU train faster. Since it doesn’t involve heavy computations, it allows models to process large amounts of data, leading to shorter training times.
Prevents the Vanishing Gradient Problem
In deep networks, some activation functions cause minimal updates, slowing down learning. ReLU avoids this issue by ensuring that the gradients (which help adjust the model’s learning) stay large enough for efficient updates. This keeps the training process smooth and effective.
Efficient Use of Neurons
ReLU naturally “turns off” some neurons by setting negative values to zero. This helps in making the model more efficient because only important neurons remain active during training, reducing unnecessary computations.
Scales Well for Large Networks
Since ReLU is simple, it works well even in deep neural networks with many layers. It doesn’t add extra computational burden, making it ideal for complex AI models.
Because of these advantages, ReLU is often the first choice for activation functions in Deep Learning.
Challenges and Limitations of ReLU
ReLU is a powerful activation function in Deep Learning but is imperfect. It faces particular challenges that can impact the performance of neural networks. Below are two common problems and their possible solutions.
The Dying ReLU Problem
ReLU turns all negative inputs into zero. Sometimes, the weights adjust during training so that a neuron only receives negative values. If this happens, the neuron gets “stuck” and always outputs zero, meaning it never activates again. This is called the dying ReLU problem.
A neuron that stops learning can weaken the model’s ability to make accurate predictions.
Solution: Variants like Leaky ReLU and PReLU allow small nonzero values for negative inputs, preventing neurons from dying.
Sensitivity to Large Gradient Updates
During training, very large gradient values can cause sudden and extreme changes in model weights. This is known as the exploding gradient problem. It can make training unstable, slow down learning, and lead to poor results.
Solution: Methods like gradient clipping and batch normalisation help control gradient values, making training smoother and more effective.
Ending Thoughts
The Rectified Linear Unit (ReLU) is a game-changer in Deep Learning, enabling faster training and improved accuracy. Its simplicity and efficiency make it the preferred activation function in neural networks. However, challenges like the dying ReLU problem have led to advanced variants like Leaky ReLU and PReLU.
By mastering ReLU and its alternatives, you can build powerful AI models for tasks like image recognition, NLP, and self-driving technology. To dive deeper into Machine Learning, Deep Learning, and other vital Data Science concepts, join Pickl.AI’s free Data Science course and enhance your expertise in AI-driven technologies.
Frequently Asked Questions
What is the Rectified Linear Unit (ReLU) Activation Function?
The Rectified Linear Unit (ReLU) is an activation function in Deep Learning that allows positive values to pass unchanged while converting negative values to zero. This simple yet effective mechanism speeds up training and helps deep neural networks perform efficiently in tasks like image recognition and speech processing.
Why is ReLU Preferred Over Sigmoid and Tanh Activation Functions?
ReLU is faster and more efficient than Sigmoid and Tanh because it avoids complex calculations and mitigates the vanishing gradient problem. It allows deep neural networks to train quickly while maintaining performance, making it ideal for large-scale AI applications like natural language processing and autonomous systems.
What are the Limitations of ReLU, and How Can They be Addressed?
ReLU suffers from the dying ReLU problem, where neurons become inactive when receiving only negative values. This issue can be resolved using Leaky ReLU or Parametric ReLU (PReLU), which allow small negative values to pass through, keeping neurons active and improving learning stability in Deep Learning models.
Authors
-

Written by:
Versha RawatReviewed by:



