
Summary: Gradient descent is a fundamental optimisation technique in Deep Learning crucial for minimising loss functions and enhancing model accuracy. It operates by iteratively adjusting model parameters based on the gradient of the loss function. Understanding its types—Batch, Stochastic, and Mini-batch Gradient Descent—enables effective training of complex neural networks.
Introduction
In Machine Learning, optimisation is critical in improving model accuracy by adjusting parameters to minimise errors. Gradient descent in Deep Learning is one of the most widely used optimisation techniques, enabling models to learn from data efficiently.
This blog will explain gradient descent, its types, and its significance in training Deep Learning models. The global Deep Learning market, valued at USD 69.9 billion in 2023, is projected to reach USD 1,185.53 billion by 2033, growing at a CAGR of 32.57%.
Understanding gradient descent is key to harnessing the full potential of Deep Learning models in this rapidly expanding field.
Key Takeaways
- Gradient Descent minimises loss functions in Deep Learning models.
- Types include Batch, Stochastic, and Mini-batch Gradient Descent.
- The learning rate significantly influences convergence speed and stability.
- Techniques like momentum and adaptive methods improve optimisation efficiency.
- Addressing challenges such as local minima enhances model training outcomes.
What is Gradient Descent?
Gradient descent is a fundamental optimisation technique used to minimise a function. In Deep Learning, this function is typically a loss or cost function, which measures how well a model’s predictions match the actual results.
The goal is to find the model’s parameters (weights) that minimise the value of this function, thus improving the model’s performance.
At a high level, It works by iteratively adjusting the model’s parameters in the direction that reduces the loss. The term gradient refers to the derivative of the loss function concerning the model’s parameters, which indicates how much the loss changes with small changes in those parameters.
How it Works: The Process of Finding the Minimum
To understand how gradient descent works, imagine a hiker standing on a mountainous terrain trying to reach the lowest point (the minimum). The hiker can’t see the entire terrain but can feel the slope beneath their feet.
The hiker moves downhill, taking steps based on the direction and steepness of the slope, in hopes of reaching the lowest point.
In mathematical terms, this process involves calculating the loss function’s gradient (the slope) at the current point and then taking a step proportional to that gradient. The step size is determined by the learning rate, which controls how big or small the adjustments are.
A higher learning rate results in larger steps, while a smaller one makes finer adjustments.
By repeatedly taking these steps, It eventually converges to a point where the loss is minimised. This process is essential for training Machine Learning models, especially deep neural networks, where manually optimising parameters is impractical due to their high complexity. We can efficiently train these models and improve their predictive capabilities.
The Mathematics Behind Gradient Descent

It is an optimisation technique in Machine Learning and Deep Learning to minimise a model’s loss function or error. The mathematics behind can be understood by exploring two key concepts: the gradient and the update rule.
The Gradient and Steepest Descent
In mathematics, a function’s gradient refers to the vector of partial derivatives that points in the direction of the greatest rate of increase. In the optimisation context, the gradient tells us the direction in which the function increases the most.
To minimise the function, we need to move in the opposite direction of the gradient—this is where the term “steepest descent” comes in. The algorithm moves toward the steepest decline to find the minimum point.
The Update Rule for Weights
The core of gradient descent is the update rule used to adjust the model’s parameters (weights). In simple terms, it tells us how to update the weights based on the gradient of the loss function concerning each parameter. The formula for this update rule is:
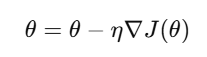
Alt Text: Formula for update rule.
Here:
- θ represents the model’s parameters (weights).
- η is the learning rate, which determines how big a step to take in the direction of the gradient.
- ∇J(θ) is the gradient of the loss function
- J(θ) concerning the parameters.
At each step, the model parameters are adjusted to reduce the loss, gradually getting closer to the optimal values.
Intuitive Explanation of the Concepts
Think of a hiker on a mountain looking to find the lowest point in a valley. The gradient represents the steepness and direction of the slope. The hiker needs to move in the opposite direction of the steepest slope to descend to the valley floor, much like how gradient descent adjusts the model’s parameters.
The learning rate controls how far the hiker moves with each step, balancing speed and accuracy in finding the minimum.
Types of Gradient Descent
In Deep Learning and Machine Learning, gradient descent is the algorithm used to minimise the loss function by updating the model’s parameters. The efficiency and accuracy of the model’s training depend largely on the type of gradient descent employed.
There are three primary variants: Batch Gradient Descent, Stochastic Gradient Descent (SGD), and Mini-batch Gradient Descent. Each has its strengths and weaknesses, making them suitable for different scenarios.
Batch Gradient Descent
It is the most straightforward method for training a model. In this approach, the gradient of the loss function is computed using the entire dataset. The model’s parameters are updated after each complete pass through the dataset.
How It Works
In Batch Gradient, the algorithm takes all the training examples and computes the gradient of the loss function concerning the parameters. It then updates the parameters by subtracting the product of the learning rate and the gradient. This process is repeated until the loss converges or a predefined number of iterations is reached.
Advantages
- Stable Convergence: Since Batch Gradient Descent uses the entire dataset, the gradient calculated is more stable and leads to smoother updates.
- Optimal for Small Datasets: Batch gradient descent is highly effective for small datasets that can fit into memory because it ensures that the parameters converge to the global minimum in a predictable manner.
- Precise Updates: Each update is based on all available data, making its approach to minimising errors highly precise.
Disadvantages
- Slow Computation: Computing the gradient for the entire dataset can be computationally expensive and time-consuming when dealing with large datasets.
- Memory-Intensive: Batch Gradient Descent requires loading the entire dataset into memory, which can be impractical for very large datasets.
- Local Minima: Sometimes, They may get stuck in local minima, especially in complex loss surfaces like deep neural networks.
Stochastic Gradient Descent (SGD)
Stochastic Gradient Descent (SGD) simplifies the optimisation process by computing the gradient and updating the model parameters using only one training example at a time.
How It Works
Instead of using the whole dataset to compute the gradient, SGD randomly selects a single data point from the dataset, computes the gradient for that single point, and updates the parameters. This process is repeated for each training example, often leading to many updates per epoch.
Advantages
- Faster Updates: Since only one example is used for each update, SGD can be much faster than Batch Gradient Descent, particularly for large datasets.
- Lower Memory Usage: Unlike Batch Gradient Descent, SGD does not require loading the entire dataset into memory, making it more memory-efficient.
- Escaping Local Minima: SGD’s noisy updates allow it to potentially escape local minima and explore the loss surface more effectively.
Disadvantages
- Noisy Convergence: The frequent updates based on individual data points make the optimisation path noisy. As a result, it can take longer to converge and may oscillate around the minimum.
- Less Accurate Convergence: Since each update is based on a single example, the updates are more erratic, and SGD may not converge to the exact global minimum.
- Requires More Iterations: Due to the noisy updates, SGD often requires more epochs (passes through the data) to reach convergence compared to Batch Gradient Descent.
Mini-batch Gradient Descent
Mini-batch Gradient Descent is a hybrid approach that combines the advantages of Batch and Stochastic Gradient Descent. Instead of using the entire dataset or a single data point, It uses small, random subsets of the data, known as “mini-batches,” to compute the gradient and update the model parameters.
How It Works
In Mini-batch Gradient Descent, the dataset is divided into small batches (e.g., 32 or 64 examples). The algorithm computes the gradient for each mini-batch and updates the model parameters after every mini-batch. This method balances the computational efficiency of Batch Gradient Descent with the faster updates of SGD.
Advantages
- Faster Convergence: Mini-batch Gradient Descent typically converges faster than Batch Gradient Descent while retaining more stable updates than SGD.
- Improved Memory Efficiency: Like SGD, Mini-batch Gradient Descent uses less memory because it works with small batches of data at a time.
- Better Generalisation: Mini-batch Gradient Descent’s stochastic nature helps it generalise unseen data better than Batch Gradient Descent.
Disadvantages
- Mini-batch Size Selection: The choice of mini-batch size can significantly affect performance. A small batch size may lead to noisy updates, while a large batch size may slow down computation.
- Complexity in Tuning: Finding the optimal learning rate and mini-batch size can be challenging, requiring experimentation and adjustments.
- Still Prone to Local Minima: While the updates are smoother than in SGD, Mini-batch Gradient Descent can still get stuck in local minima, especially when dealing with complex models.
Learning Rate and Its Impact
The learning rate is a crucial hyperparameter in the gradient descent optimisation algorithm. It controls how much a model’s weights are adjusted during training after each iteration. A well-chosen learning rate ensures that the model converges to an optimal solution efficiently, while a poor choice can hinder learning or even prevent convergence.
Role of the Learning Rate in Gradient Descent
The algorithm computes the gradient of the loss function and updates the model’s parameters (weights) to minimise the error. The learning rate dictates the size of these updates. If the learning rate is too small, the model may take a long time to converge, making the training process slow and inefficient.
Conversely, if the model is too large, it might overshoot the optimal solution, leading to unstable training or divergence.
Effects of a High vs. Low Learning Rate
A high learning rate can cause the model to make large jumps in weight adjustments, potentially skipping over optimal solutions or even diverging. The model might fail to find the minimum loss function and never reach a stable state.
On the other hand, a low learning rate results in smaller weight updates, which might make the training more stable but can also significantly slow down the convergence. The model may take a long time to reach the optimal weights, and in some cases, it might get stuck in local minima.
Learning Rate Schedules and Decay
Learning rate schedules or decay strategies are often employed to optimise training. These techniques gradually reduce the learning rate during training to fine-tune the model more precisely.
A common approach is to decrease the learning rate after a certain number of epochs, allowing the model to make large updates initially and then smaller, more refined adjustments as it gets closer to the optimal solution.
Incorporating learning rate schedules can prevent overshooting while speeding up convergence. Popular methods include step decay, exponential decay, and adaptive learning rates, such as those used in optimisers like Adam.
Challenges and Solutions in Gradient Descent
It is a powerful optimisation technique used in Deep Learning, but challenges can hinder the model’s performance. Understanding these challenges is key to improving model training and ensuring better convergence. Let’s explore some common issues faced and the solutions that address them.
Local Minima
One significant challenge is the problem of local minima. In high-dimensional spaces, the optimisation landscape is complex, and it may converge to a local minimum rather than the global minimum. This is especially true in non-convex functions, common in Deep Learning models.
Solution: To avoid getting stuck in local minima, techniques like random restarts or stochastic gradient descent (SGD) can be employed. By adding noise or using random initialisations, SGD can explore a broader region of the parameter space and increase the likelihood of finding the global minimum.
Vanishing and Exploding Gradients
Another challenge is the vanishing and exploding gradients problem during backpropagation. In deep neural networks, gradients can shrink to almost zero (vanishing) or grow uncontrollably (exploding) as they propagate through the layers. This can lead to very slow learning or unstable updates, respectively.
Solution: To mitigate these issues, several techniques are used:
- Weight initialisation: Proper initialisation methods like Xavier or He initialisation help maintain a reasonable gradient size.
- Gradient clipping: This technique involves limiting the gradient’s value to a certain threshold to prevent it from exploding.
- Activation functions: Using activation functions like ReLU helps alleviate the vanishing gradient problem by maintaining positive gradients.
Momentum and Adaptive Gradient Methods
Momentum and adaptive gradient methods like Adam are commonly used to improve convergence and avoid issues like slow learning or erratic updates.
- Momentum helps accelerate gradient descent by adding a fraction of the previous update to the current update. This enables the algorithm to escape local minima and smoothens the path toward convergence.
- Adam (Adaptive Moment Estimation) combines momentum and adaptive learning rates, dynamically adjusting the learning rate based on the estimates of the gradients’ first and second moments. It is widely used because it generally converges faster and requires less manual tuning of hyperparameters.
Addressing these challenges with the right techniques can significantly improve gradient descent, ensuring more efficient and stable model training.
Applications of Gradient Descent in Deep Learning

It plays a crucial role in training neural networks, including Deep Neural Networks (DNNs) and Convolutional Neural Networks (CNNs). It is the backbone of optimising models to make accurate predictions by minimising the error between predicted and actual values.
Training Neural Networks
In Deep Learning, neural networks consist of multiple layers with weights and biases. Gradient descent is employed to adjust these parameters during the training process. Through the iterative process, the algorithm adjusts the weights by calculating the gradient of the loss function concerning the parameters, guiding the network toward the optimal configuration.
For deep neural networks with many hidden layers, It helps by making small adjustments to weights in each layer, improving the model’s performance progressively. This process enables the model to learn complex patterns in the data, which is essential for tasks like image recognition, natural language processing, and more.
Training Convolutional Neural Networks (CNNs)
It’s also widely used in training CNNs, which are particularly effective for image-related tasks. CNNs consist of convolutional layers that detect features like edges, textures, and image patterns.
It optimises the weights of the filters applied to the input data, allowing CNN to learn hierarchical features as it processes the image through its layers.
In CNNs, the backpropagation algorithm, driven by gradient descent, efficiently computes the gradient of the loss function concerning the network’s weights. This allows CNNs to reduce prediction errors, improving accuracy over time.
Minimising the Error
The primary goal of using gradient descent in Deep Learning is to minimise the error or loss function. The difference between the predicted outputs and actual values (error) decreases as the algorithm adjusts the weights.
This process ensures that the model’s predictions become increasingly accurate, leading to a highly optimised neural network capable of making reliable predictions.
Bottom Line
This blog explored gradient descent in Deep Learning, a critical optimisation technique that enhances model accuracy by minimising errors through iterative parameter adjustments. Understanding its types—Batch, Stochastic, and Mini-batch Gradient Descent—enables practitioners to choose the most effective approach for their specific datasets and applications.
By mastering gradient descent, one can harness the full potential of Deep Learning models, ensuring efficient training and improved predictive capabilities in an ever-evolving technological landscape.
Frequently Asked Questions
What is Gradient Descent in Deep Learning?
Gradient descent is an optimisation algorithm that minimises the loss function in Deep Learning models. Iteratively adjusting model parameters based on the gradient of the loss function helps improve the model’s accuracy and performance.
What are the Types of Gradient Descent?
The main types of gradient descent are Batch Gradient Descent, Stochastic Gradient Descent (SGD), and Mini-batch Gradient Descent. Each type has strengths and weaknesses, making them suitable for different scenarios and dataset sizes.
How Does the Learning Rate Affect Gradient Descent?
The learning rate determines the size of weight updates during training. A high learning rate can lead to overshooting optimal solutions, while a low rate may slow convergence. Proper tuning is essential for effective training.
Authors
-

Written by:
Julie BowieReviewed by:



