
Summary: Gated Recurrent Units (GRUs) enhance Deep Learning by effectively managing long-term dependencies in sequential data. Using simplified gating mechanisms, GRUs outperform traditional RNNs and are computationally efficient compared to LSTMs. Their applications span various fields, including natural language processing, time series forecasting, and speech recognition, making them a vital tool in modern AI.
Introduction
Recurrent Neural Networks (RNNs) are a cornerstone of Deep Learning. However, traditional RNNs struggle with long-term dependencies. The Gated Recurrent Unit (GRU) in Deep Learning addresses these challenges by introducing a simplified yet effective gating mechanism.
This blog aims to explore GRU’s architecture, advantages, and applications. With the global Deep Learning market projected to grow from USD 49.6 billion in 2022 to over USD 249 billion by 2030, understanding GRU’s role is crucial.
Key Takeaways
- GRUs use fewer parameters than LSTMs, leading to faster training and lower computational costs.
- They effectively address the vanishing gradient problem, making them suitable for long sequences.
- GRUs excel in natural language processing, time series forecasting, and speech recognition.
- With two gates (update and reset), GRUs streamline information flow compared to traditional RNNs.
- While efficient, GRUs may struggle with very long sequences compared to LSTMs, depending on the task complexity.
Understanding Recurrent Neural Networks (RNNs)
Recurrent Neural Networks (RNNs) are a class of neural networks designed to handle sequential data, where the output depends on both the current input and previous inputs.
Unlike traditional feedforward networks, RNNs have loops in their architecture, allowing information to persist across time steps. This ability makes RNNs ideal for tasks like time series forecasting, speech recognition, and Natural Language Processing, where the order of inputs is crucial.
Basic Structure and Function of RNNs
An RNN processes data sequentially, taking one input at a time while maintaining a hidden state containing information about previous inputs. The RNN computes the output at each time step based on the current input and the hidden state.
The hidden state is updated by passing it through a function, typically a sigmoid or tanh activation, to capture relevant features from the past.
Challenges with Traditional RNNs
Traditional RNNs face several challenges, the most significant of which is the vanishing gradient problem. When training RNNs using Backpropagation Through Time (BPTT), gradients can shrink exponentially as they are propagated back through many time steps.
This leads to difficulty learning long-range dependencies, as the network struggles to adjust weights effectively. Consequently, RNNs may fail to capture essential patterns in long sequences, limiting their effectiveness for complex tasks.
What is a Gated Recurrent Unit (GRU)?
The Gated Recurrent Unit (GRU) is a Recurrent Neural Network (RNN) architecture designed to address the limitations of traditional RNNs, particularly the vanishing gradient problem.
Introduced in 2014 by Cho et al., GRU is a simplified version of the more complex Long Short-Term Memory (LSTM) model. It uses gating mechanisms to control the flow of information, making it efficient in learning from sequential data over long periods.
GRU vs. Long Short-Term Memory (LSTM)
While GRU and LSTM are designed to capture long-term dependencies in sequential data, their architecture differs. LSTM uses three gates: the input gate, forget gate, and output gate, along with a memory cell, to store information over time.
In contrast, GRU combines the forget and input gates into a single update gate and uses a reset gate. This simplification makes GRU computationally more efficient and faster to train, especially for smaller datasets or real-time applications.
Advantages of GRU Over Traditional RNNs and LSTMs
Compared to traditional RNNs, GRUs solve the vanishing gradient problem using gating mechanisms that allow them to retain information for longer periods. This makes them more effective for tasks that require learning from long data sequences, such as language modelling or time series prediction.
GRUs offer several advantages over LSTMs. First, their simpler architecture means fewer parameters, which leads to faster training and less memory usage. This is particularly beneficial when working with limited computational resources. Additionally, GRUs often perform as well as LSTMs on many tasks, making them attractive when efficiency and performance are key considerations.
Architecture of GRU
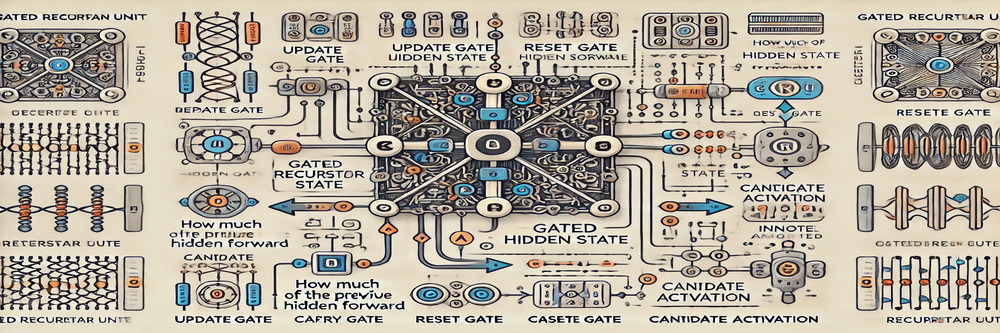
The Gated Recurrent Unit (GRU) cell is designed to address the limitations of traditional RNNs, particularly in handling long-term dependencies.
It combines gating mechanisms that control the flow of information, making it more efficient and less prone to the vanishing gradient problem. The GRU cell consists of critical components, each serving a specific purpose to manage the information flow effectively.
Key components of GRU are:
Update Gate
The update gate determines how much of the previous hidden state should be carried forward to the current state. It balances keeping the past information and incorporating new input, enabling the model to preserve relevant features over time. This gate is essential for deciding whether to retain or discard historical data.
Reset Gate
The reset gate controls how much of the previous hidden state should be ignored when calculating the candidate activation.
By deciding whether to forget the past information, the reset gate allows the GRU cell to focus on the most relevant features for the current time step. It helps the network reset its memory when necessary, ensuring the model isn’t overwhelmed by irrelevant past data.
Candidate Activation
The candidate activation is a potential new memory content for the current time step, computed from the input and the previous hidden state. The reset gate influences the candidate activation by controlling how much of the previous state is used to compute the candidate.
Mathematical Formulation of GRU Operations
The mathematical operations of GRU are defined as follows:
- Update Gate:
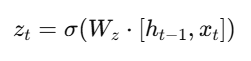
Alt Text: Formula for update gate.
The update gate determines the proportion of the previous state to retain.
- Reset Gate:
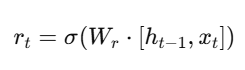
Alt Text: Formula for reset gate.
The reset gate decides how much of the previous state to forget.
- Candidate Activation Gate:
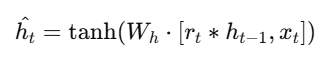
Alt Text: Formula for candidate activation gate.
The candidate activation provides the new potential state influenced by the reset gate.
- Final Hidden State:
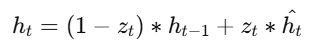
Alt Text: Formula for the final hidden gate.
The final hidden state combines the previous state and candidate activation, weighted by the update gate.
Information Flow Control with Gating Mechanisms
The gating mechanisms in GRU work together to selectively update the hidden state, allowing the network to maintain relevant information while ignoring noise. By regulating the flow of information through the update and reset gates, the GRU cell adapts its memory over time, making it well-suited for tasks that require learning long-term dependencies.
Advantages of GRU
Gated Recurrent Unit (GRU) has gained significant attention in Deep Learning for its ability to improve the performance of Recurrent Neural Networks (RNNs). While GRU shares some similarities with Long Short-Term Memory (LSTM) networks, it offers unique advantages that make it a powerful alternative for sequence modelling tasks.
Below, we explore GRU’s key benefits, including its simplicity, faster training, and enhanced performance in specific applications.
Comparison with LSTM and Traditional RNN
GRU is often compared to LSTM because both are designed to tackle the limitations of traditional RNNs, particularly the vanishing gradient problem. However, GRUs are more streamlined and computationally efficient.
Unlike LSTMs, which use three gates (input, forget, and output) to manage memory, GRUs combine these into the update and reset gates. This simplified architecture allows GRUs to perform similarly to LSTMs but with fewer parameters and less complexity, making them more efficient in training and computation.
Traditional RNNs, while effective for short sequences, struggle with long-term dependencies due to their simpler structure. GRUs overcome this by regulating the flow of information, enabling them to capture long-range dependencies more effectively than basic RNNs.
Fewer Parameters Leading to Faster Training
One of the standout features of GRUs is their efficiency in terms of model parameters. GRUs use fewer parameters than LSTMs because they have a simplified structure—just two gates instead of three.
As a result, GRUs tend to require less memory and computational power. This leads to faster training times, making them ideal for large datasets or real-time applications where computational efficiency is crucial.
Better Performance in Certain Tasks
GRUs excel in tasks involving sequence prediction, especially when the dataset is not excessively large. Their reduced complexity and faster training make them highly effective in Natural Language Processing (NLP), speech recognition, and time series forecasting.
In many cases, GRUs outperform LSTMs, mainly when dealing with simpler tasks or when computational resources are limited.
Applications of GRU in Deep Learning
Gated Recurrent Units (GRUs) have become essential tools in various Deep Learning applications due to their efficiency and ability to handle sequential data.
Their simplicity of architecture, combined with their ability to retain important information across time steps, makes them suitable for various tasks, including time series forecasting, Natural Language Processing (NLP), speech recognition, and video analysis.
Time Series Forecasting
GRUs excel in predicting future values in time series data, such as stock prices, weather patterns, and demand forecasting. The model’s ability to capture dependencies over time while maintaining a manageable number of parameters allows for more accurate predictions than traditional models.
GRUs can handle both short-term fluctuations and long-term trends, making them ideal for precision-requiring real-world forecasting tasks.
Natural Language Processing (NLP)
GRUs are widely used in NLP for tasks like sentiment analysis, machine translation, and text summarisation. Unlike simpler models, GRUs can learn contextual relationships in text sequences, which is crucial for understanding language structure and meaning.
Their gating mechanisms allow them to retain relevant context while discarding irrelevant information, making them highly effective for processing and interpreting natural language data.
Speech Recognition
GRUs are also powerful speech recognition systems tools that help convert spoken language into text. By processing audio signals sequentially, GRUs can capture the temporal patterns and nuances in speech, such as tone, cadence, and rhythm.
This capability enhances the accuracy of speech recognition models, making them more robust in noisy environments or for speakers with varying accents.
Video Analysis
Video analysis tasks, such as action recognition and object tracking, benefit from GRUs’ ability to handle sequences of frames. GRUs can track movements and detect patterns over time by processing the video frames in order, enabling more effective dynamic content analysis.
This is especially useful in applications like surveillance, autonomous vehicles, and sports analytics, where real-time processing of video streams is crucial.
Implementing GRU in Deep Learning Models
Implementing a Gated Recurrent Unit (GRU) in Deep Learning models is straightforward, especially with frameworks like Keras or TensorFlow.
GRUs are widely used in time series prediction, natural language processing (NLP), and other sequential data tasks because they are more efficient and simple than traditional RNNs. Below is an example of how to implement a GRU in a Deep Learning model using Keras.
Example: GRU for Sequence Prediction
To demonstrate the power of GRUs, let’s create a simple sequence prediction model using Keras. We’ll build a neural network with a GRU layer and a Dense layer for output.

Code Explanation
- Data Generation and Reshaping: We create a simple sine wave dataset and reshape it into a 3D format (samples, timesteps, features) as required by the GRU layer.
- Model Building: The model begins with a GRU layer with 50 units and ReLU activation. This layer processes the input sequence and captures temporal dependencies. We follow it with a Dense layer to output a single value, representing the predicted next value in the sequence.
- Model Compilation and Training: The model is compiled using the Adam optimiser and mean squared error loss function, then trained for 50 epochs.
Following this structure, you can implement GRU in various Deep Learning applications and tailor it for sequence prediction tasks.
Challenges and Limitations
While Gated Recurrent Units (GRUs) offer several advantages over traditional RNNs and even Long Short-Term Memory (LSTM) networks, they are not without challenges. Understanding these limitations is crucial for determining when GRUs are the best choice for a given problem.
Data Dependency
One of the primary challenges with GRUs is their sensitivity to data characteristics. Like other RNN-based models, GRUs require large and well-structured datasets to train effectively.
GRUs may struggle to produce accurate results in cases where the data is sparse, noisy, or unbalanced. Their performance significantly deteriorates when working with small datasets or when the data lacks sufficient temporal patterns.
Difficulty with Very Long Sequences
While GRUs mitigate the vanishing gradient problem better than traditional RNNs, they still face limitations when dealing with long sequences. GRUs can struggle to maintain relevant information over time, even with their gating mechanism in tasks involving lengthy time-series data or long sequences.
While the GRU is more efficient than an LSTM in terms of fewer parameters, it can still fail to capture long-range dependencies in sequences longer than a few hundred steps.
Comparison with LSTM
GRUs are often considered a simpler, more efficient alternative to LSTM networks, but they do not always outperform LSTMs. LSTMs have three gates (input, forget, and output) that provide more control over the information flow, allowing them to handle more complex relationships within the data.
In contrast, the simpler GRU has only two gates (update and reset), which can sometimes be less effective for tasks requiring deeper memory and finer control, such as language modelling or machine translation.
While GRUs offer faster training times and lower computational costs, LSTMs are preferred for more complex, long-range dependencies. Thus, choosing between GRU and LSTM depends on the specific task.
In The End
The blog on Gated Recurrent Units (GRU) in Deep Learning provides a comprehensive overview of GRUs, highlighting their architecture, advantages, and applications in handling sequential data. GRUs improve upon traditional RNNs by addressing the vanishing gradient problem through efficient gating mechanisms.
Their simpler structure allows for faster training and less computational power, making them suitable for various tasks such as natural language processing and time series forecasting. Understanding GRUs is essential for leveraging their capabilities in real-world applications as the Deep Learning landscape evolves.
Frequently Asked Questions
What is a Gated Recurrent Unit (GRU)?
A Gated Recurrent Unit (GRU) is a recurrent neural network that manages long-term dependencies in sequential data. It features gating mechanisms that control information flow, making it more efficient than traditional RNNs and simpler than Long Short-Term Memory (LSTM) networks.
How do GRUs Compare to LSTMs?
GRUs are often more efficient than LSTMs due to their simpler architecture, which uses two gates instead of three. This reduction in complexity leads to faster training times while still performing comparably well in tasks requiring long-term memory retention.
What are the Primary Applications of GRUs?
GRUs are widely used in various applications, including natural language processing (NLP), time series forecasting, speech recognition, and video analysis. Their ability to handle sequential data efficiently makes them ideal for tasks that require understanding temporal patterns.
Authors
-

Written by:
Karan SharmaReviewed by:



