
Summary: Backpropagation in neural network optimises models by adjusting weights to reduce errors. Despite challenges like vanishing gradients, innovations like advanced optimisers and batch normalisation have improved their efficiency, enabling neural networks to solve complex problems.
Introduction
Inspired by the human brain, neural networks are at the core of modern Artificial Intelligence, driving breakthroughs in image recognition, natural language processing, and more. Backpropagation in Neural Networks is vital in training these systems by efficiently updating weights to minimise errors. This process ensures that networks learn from data and improve over time.
As the neural network software market grows from USD 23.10 billion in 2023 to an estimated USD 311.13 billion by 2032 (CAGR of 33.5%), mastering backpropagation is more critical than ever. This article explores its mechanics, challenges, and significance in AI’s evolution.
Key Takeaways
- Backpropagation is essential for training neural networks by minimising errors.
- It uses gradients and the chain rule to optimise network weights.
- Challenges include vanishing and exploding gradients, especially in Deep Networks.
- Advanced techniques like Adam and batch normalisation enhance backpropagation’s efficiency.
- Backpropagation powers applications in image recognition, NLP, and autonomous systems.
Understanding Backpropagation
Backpropagation, short for “backward propagation of errors,” is a core algorithm for training artificial neural networks. It efficiently calculates the gradient of the loss function concerning the network’s weights.
Introduced in the 1980s, it marked a breakthrough in Machine Learning by enabling Deep Networks to learn complex patterns from data. Backpropagation relies on the calculus chain rule to propagate errors backward through the network, layer by layer.
The Role of Backpropagation in Supervised Learning
Supervised learning aims to train a model to map inputs to desired outputs by minimising errors between predictions and actual results. Backpropagation plays a crucial role in this process. During training, the algorithm calculates the error for a given input-output pair and then adjusts the neural network’s weights to reduce this error. This iterative process ensures the network learns from its mistakes, improving accuracy over time.
Backpropagation operates in two main phases:
- Forward Pass: The algorithm computes the predicted output using current weights and calculates the loss based on the difference between the expected and actual outputs.
- Backward Pass: The algorithm propagates the error backward through the network, updating the weights using the gradient of the loss function.
How Backpropagation Optimises the Model
Backpropagation optimises a model by fine-tuning its weights to minimise the loss function. It uses gradient descent, an optimisation technique, to iteratively adjust weights in the direction of the steepest descent. By computing gradients for each weight, backpropagation ensures that the network learns more effectively from the data.
This optimisation process allows neural networks to model complex, nonlinear relationships, making backpropagation a cornerstone of modern deep learning.
Mathematical Foundation of Backpropagation
Backpropagation is grounded in calculus and linear algebra. It enables a neural network to learn by iteratively adjusting its weights to minimise errors. Let’s explore its key components and the step-by-step process.
Key Components of Backpropagation
The key mathematical elements of backpropagation help explain how neural networks learn. These components work together to update the model’s parameters and reduce the loss during training.
Loss Function
The loss function quantifies how far the model’s predictions are from the true values. Common loss functions include Mean Squared Error (MSE) for regression and Cross-Entropy Loss for classification tasks. The aim is to minimise this loss during training.
Gradients
Gradients measure the rate of change of the loss function concerning the model’s parameters (weights and biases). They guide the weight updates, ensuring the network moves toward decreasing error.
Chain Rule
The chain rule from calculus is the backbone of backpropagation. It breaks down the derivative of a composite function into a product of simpler derivatives. The chain rule calculates how weight changes affect the loss in neural networks through multiple layers.
Step-by-Step Explanation of Backpropagation
The backpropagation process involves distinct phases that optimise the neural network. Understanding each step is essential to grasp how learning happens.
Forward Pass
The forward pass computes the network’s output by propagating input data through the layers. Each neuron applies a weighted sum of its inputs, adds a bias, and passes the result through an activation function. The final output is compared to the target value to calculate the loss.
Computing the Loss
The loss function evaluates the difference between the predicted output and the target. For example, using MSE:
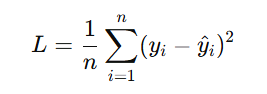
Alt Text: Mean squared error loss function formula.
Where yi is the actual value, and y^i is the predicted value.
Backward Pass (Gradient Computation)
Using the chain rule, backpropagation calculates the gradient of the loss function concerning each weight. This involves moving backward through the network, layer by layer, and computing partial derivatives of the loss.
Weight Update (Gradient Descent)
The weights are updated using the gradients and a learning rate (η):
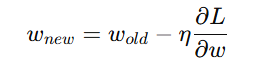
Alt Text: Weight update rule using gradient descent.
This adjustment minimises the loss in subsequent iterations.
Example: Single-Layer Network
A simple example helps clarify the process. In a single-layer network, the computations are straightforward and highlight the essence of backpropagation. This basic scenario illustrates how gradients are computed, and weights are updated, offering a foundation for understanding more complex networks.
Consider a network with one input (x), one weight (w), and a linear activation function.
- Forward Pass:
 (where t is the target).
(where t is the target).
Alt Text: Linear regression equation with loss function.
- Gradient:
 .
.
Alt Text: Gradient of the loss function with respect to weights.
- Update: Adjust w using the gradient.
This iterative process forms the essence of backpropagation, driving the learning process.
Algorithm for Backpropagation
Backpropagation is the cornerstone of training Deep Neural Networks. It is an iterative process that helps adjust the model’s weights and biases to minimise errors. This section will break down the algorithm and highlight the computational complexity and challenges that arise during the process.
Pseudocode for Backpropagation
Pseudocode provides a simple, high-level view of the backpropagation algorithm. It outlines the sequence of steps followed during a neural network’s training. Understanding the pseudocode helps visualise the flow of operations and how the network learns by adjusting its parameters.
- Initialise Parameters: Set weights and biases to small random values.
- Repeat Until Convergence:
- Perform a forward pass through the network to compute activations.
- Calculate the loss function based on predictions and actual targets.
- Perform a backward pass to compute gradients for all weights and biases.
- Update weights and biases using an optimisation algorithm (e.g., gradient descent).
This cycle repeats until the network’s weights are optimised for minimal error, ensuring the model learns to make accurate predictions.
Computational Complexity and Challenges
Backpropagation is an efficient method for training neural networks, but it comes with computational challenges that can hinder its performance in certain situations. Understanding time complexity and common obstacles is crucial for optimising the process.
Complexity
The computational complexity of backpropagation is proportional to the number of weights and the network size. For each forward and backward pass, the operations scale with the total number of parameters, O(W), where W is the total number of weights in the network. As the network depth and size increase, so does the computational cost.
Challenges
Understanding these challenges is crucial for improving training and developing solutions to make backpropagation more effective. Let’s explore some of the most common issues faced during backpropagation.
Vanishing Gradients
In Deep Networks, gradients can become extremely small, leading to very slow updates in the early layers. This problem hampers the learning process, especially when using sigmoid or tanh activation functions.
Exploding Gradients
In contrast, gradients can grow excessively large in specific networks, causing instability and preventing convergence. This is often seen in Deep Networks with many layers or high learning rates.
Computational Expense
Training large networks requires significant computational resources regarding memory and processing power. This makes training deep models on large datasets resource-intensive.
Sensitivity to Hyperparameters
The success of backpropagation relies heavily on the learning rate, batch size, and weight initialisation. Poor choices can lead to slow convergence or poor model performance.
Advantages and Disadvantages of Backpropagation
Addressing these challenges with better initialisation techniques, advanced optimisers, and network architecture modifications can make backpropagation more efficient, ensuring the successful training of Deep Neural Networks.
In this section, we explore the key advantages that make backpropagation an essential tool for neural network training and the limitations that can impact its effectiveness in certain scenarios. Understanding both sides is crucial for optimising model performance and addressing potential pitfalls during training.
Advantages of Backpropagation
Backpropagation has revolutionised neural network training, making it a foundational technique for modern Machine Learning. It allows neural networks to learn from data effectively, enabling them to make accurate predictions. Here are some key advantages of backpropagation in neural network training.
Efficiency in Training Deep Networks
Backpropagation enables efficient learning by updating weights based on error gradients. This efficiency accelerates the training process, even for Deep Neural Networks with multiple layers.
Versatility Across Different Architectures
For feedforward networks, convolutional networks, or recurrent models, backpropagation adapts seamlessly to various neural network architectures, enhancing its utility in diverse applications.
Scalability with Large Datasets
Backpropagation’s ability to handle vast amounts of data makes it scalable, allowing models to learn effectively from large datasets while maintaining computational efficiency.
Disadvantages of Backpropagation
Despite its effectiveness, backpropagation faces several challenges and limitations that can hinder neural network performance. These issues must be addressed to ensure efficient training and optimal model performance.
Vanishing and Exploding Gradients
In Deep Networks, gradients may become too small (vanishing) or excessively large (exploding), making it difficult for the network to learn effectively. This leads to slow convergence or unstable updates during training.
Computational Expense
Training large neural networks requires significant computational resources, especially when dealing with high-dimensional data, which increases training time and costs.
Sensitivity to Learning Rate and Initialisation
Improper initialisation or an inappropriate learning rate can result in poor convergence, causing either slow learning or overshooting the optimal solution.
Enhancements to Backpropagation
Backpropagation has been the backbone of neural network training, but its limitations have prompted the development of several modern techniques that improve efficiency, stability, and performance. Below are some of the key enhancements:
Optimisers: Adam and RMSprop
Traditional gradient descent can struggle to find optimal weights, especially in Deep Networks. Modern optimisers like Adam and RMSprop address this by adapting the learning rate for each parameter during training.
Adam, which combines the benefits of Momentum and RMSprop, adjusts the learning rate using the gradients’ first moment (mean) and second moment (variance).
This results in faster convergence and more stable updates. Similarly, RMSprop adapts the learning rate based on recent gradient information, preventing large weight updates and mitigating the effects of noisy data.
Batch Normalization
Batch Normalization (BN) is a technique that normalises the input to each network layer during training. By standardising each layer’s output to have zero mean and unit variance, BN reduces the internal covariate shift and helps mitigate the vanishing gradient problem.
This speeds up convergence, allows higher learning rates, and can even act as a form of regularisation, reducing overfitting in some cases.
Residual Connections (ResNets)
In very Deep Networks, backpropagation can suffer from the vanishing gradient problem, where gradients diminish as they propagate backward through the network. Residual connections, as used in ResNets, help by creating shortcut pathways that skip one or more layers.
These connections allow gradients to flow more easily during backpropagation, making it feasible to train intense networks without losing information.
Use of Frameworks: TensorFlow and PyTorch
Frameworks like TensorFlow and PyTorch have made the implementation of backpropagation easier and more efficient. These libraries automatically handle the complex mathematics of gradient computation, optimise performance, and provide built-in support for advanced features like distributed computing and GPU acceleration, making it easier to scale up experiments and production-level models.
These advancements have significantly enhanced backpropagation, making it more efficient, scalable, and effective in training Deep Neural Networks.
Practical Applications of Backpropagation
Backpropagation, the backbone of training neural networks, is pivotal in powering various cutting-edge technologies. Its ability to optimise and fine-tune models makes it essential in solving complex real-world problems. Here are some key areas where backpropagation plays a critical role:
Image Recognition
In image recognition tasks, backpropagation helps Deep Neural Networks, such as Convolutional Neural Networks (CNNs), classify images with remarkable accuracy. By adjusting weights based on errors between predicted and actual labels, backpropagation allows the network to learn complex patterns, such as recognising objects, faces, or medical images.
This technique is widely used in fields like security, healthcare (for detecting diseases in medical scans), and autonomous vehicles for object detection.
Natural Language Processing (NLP)
Backpropagation is essential in NLP, which powers models to understand, generate, and translate text. It helps deep learning models like Recurrent Neural Networks (RNNs) and Transformers learn contextual relationships between words and sentences. Applications such as language translation, sentiment analysis, and chatbot development rely on backpropagation to refine their predictions, improving accuracy and fluency.
Autonomous Systems
In autonomous systems, such as self-driving cars or drones, backpropagation enables the model to continuously learn from sensory data, adjusting its actions to navigate complex environments. By minimising prediction errors in real time, backpropagation optimises decision-making algorithms, allowing autonomous systems to adapt to dynamic surroundings safely and efficiently.
Backpropagation remains foundational in making these advanced technologies work effectively.
Bottom Line
Backpropagation in neural networks is a vital algorithm for training models. It enables them to learn from data by adjusting weights based on error gradients. It optimises networks through iterative updates, helping them model complex patterns effectively.
Despite challenges like vanishing gradients, innovations such as advanced optimisers and batch normalisation have enhanced their efficiency, making them indispensable in modern AI applications.
Frequently Asked Questions
What is Backpropagation in Neural Networks?
Backpropagation in neural networks is an algorithm that adjusts weights to minimise errors during training. It calculates gradients using the chain rule and updates weights to improve predictions.
How does Backpropagation Optimise Neural Networks?
Backpropagation optimises neural networks by updating weights based on error gradients, utilising gradient descent to minimise the loss function. This iterative process improves the model’s accuracy over time.
What Challenges Does Backpropagation Face?
Backpropagation faces challenges like vanishing gradients, exploding gradients, and computational expenses, especially in Deep Networks. Techniques like advanced optimisers and batch normalisation help mitigate these issues.
Authors
-

Written by:
Smith AlexReviewed by:


