
Summary: Batch Normalization in Deep Learning improves training stability, reduces sensitivity to hyperparameters, and speeds up convergence by normalising layer inputs. It’s a crucial technique in modern neural networks, enhancing performance and generalisation.
Introduction
Deep Learning has revolutionised technology, powering advancements in AI-driven applications like speech recognition, image processing, and autonomous systems. However, training deep neural networks often encounters challenges such as slow convergence, vanishing gradients, and sensitivity to initialisation. Batch Normalization (BN) in Deep Learning addresses these issues by stabilising and accelerating training, enabling efficient learning in complex models.
The global Deep Learning market, valued at $17.60 billion in 2023, is expected to surge to $298.38 billion by 2032, growing at a CAGR of 36.7%. This article explores Batch Normalization’s concept, benefits, and implementation, offering practical insights for improved model performance.
Key Takeaways
- Batch Normalization stabilises training and accelerates convergence.
- It mitigates internal covariate shift and gradient issues.
- It reduces the sensitivity to weight initialisation.
- Batch Normalization acts as a mild regulariser.
- It has limitations in small batches and RNNs.
What is Batch Normalization?
BN is a Deep Learning technique that standardises the inputs to a layer for each mini-batch during training. This involves normalising the inputs to have a mean of zero and a variance of one, followed by scaling and shifting using learnable parameters.
It helps make training more efficient and reduces sensitivity to hyperparameter choices like learning rates.
The primary purpose of BN is to address the issue of internal covariate shift. This occurs when the distribution of inputs to a layer changes during training, making it harder for the network to converge. By normalising the inputs, Batch Normalization stabilises and accelerates training.
Why is Batch Normalization Important in Deep Learning?
BN improves the performance and stability of deep neural networks. It allows networks to train faster by smoothing the loss landscape, making gradient updates more consistent. This technique also reduces the dependence on careful weight initialisation and enables the use of higher learning rates, which speeds up convergence.
Moreover, Batch Normalization acts as a form of regularisation, reducing the need for dropout in some cases. It has become a key component in modern Deep Learning architectures by stabilising training and improving generalisation.
How Batch Normalization Works
Batch Normalization improves the training of deep neural networks by standardising intermediate layer outputs. It stabilises learning and allows the model to converge faster. Let’s break it down step by step to understand its operation.
Normalising Inputs
In Batch Normalization, the input values for each neuron in a layer are normalised across a mini-batch. For each feature in the batch, the mean (μ) and variance (![]() ) are calculated:
) are calculated:

Alt Tet: Formula for mean and variance in Batch Normalization.
Each input xi is then normalised to have zero mean and unit variance:
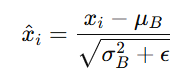
Alt Text: Formula for normalising inputs in Batch Normalization.
Here, ϵ is a small constant added for numerical stability.
Introducing Learnable Parameters
While Normalization ensures stable input distribution, it can constrain the network’s representational power. To counter this, Batch Normalization introduces two trainable parameters:
- Scale (γ): Scaling the variance adjusts the normalised output’s range.
- Shift (β): Shifts the normalised output to adjust the mean.
The normalised input is transformed using these parameters:
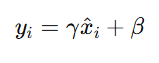
Alt Text: Formula for introducing learnable parameters in Batch Normalization.
Computing the Final Normalised Output
The normalised input ![]() is transformed using the learnable parameters:
is transformed using the learnable parameters:
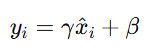
Alt Text: Formula for output after Batch Normalization transformation.
This final output yi is then passed to the next layer in the neural network. By introducing γ and β, the model gains the flexibility to undo Normalization if necessary.
Formula and Mathematical Representation
The complete mathematical formula for Batch Normalization can be expressed as:
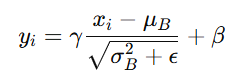
Alt Text: Complete mathematical formula for Batch Normalization.
This compact representation encapsulates all the steps from Normalization to transformation.
Diagram or Pseudocode
Pseudocode for clarity:
- Calculate batch mean (μB) and variance (
 ).
). - Normalise inputs:
 .
.
Alt Text: Pseucode for normalising inputs.
- Apply learnable parameters:
 .
.
Alt Text: Pseucode for applying learning parameters.
This sequence ensures efficient training while maintaining the model’s adaptability. Batch Normalization’s simplicity and effectiveness make it a cornerstone of modern Deep Learning architectures.
Benefits Batch Normalization

BN has become a fundamental technique in Deep Learning, offering several advantages that significantly enhance model performance. Batch Normalization addresses key challenges in training deep neural networks by normalising the inputs to each layer during training. Below are the primary benefits it provides:
Improved Training Speed
Batch Normalization stabilises the learning process, allowing faster convergence. This enables models to reach optimal performance in fewer epochs, reducing the need to tune the learning rate carefully.
Mitigation of Internal Covariate Shift
Batch Normalization helps mitigate internal covariate shift, where the distribution of inputs to each layer changes during training. This leads to more stable gradients, reducing the likelihood of exploding or vanishing gradients.
Reduced Sensitivity to Weight Initialisation
With Batch Normalization, the model becomes less dependent on the initial weights. This allows for more flexibility in choosing weight initialisation strategies, reducing the risks of poor convergence.
Acts as a Regulariser
BN introduces a slight noise to the training process using batch statistics, which acts as a form of regularisation. This reduces overfitting, often lessening the need for other techniques like dropout.
Together, these benefits make Batch Normalization a powerful tool in enhancing the efficiency and robustness of Deep Learning models.
Challenges and Limitations of Batch Normalization
While Batch Normalization has significantly improved the training of Deep Learning models, it has several challenges and limitations that can impact performance in certain scenarios. These issues often arise due to the technique’s inherent nature and can affect its efficiency and applicability in specific use cases.
Performance Issues with Small Batch Sizes
Batch Normalization relies on computing the mean and variance of a batch, which can be unstable with small batch sizes. When batches are too small, the statistics may not be representative, leading to noisy estimates and reduced model stability during training.
Dependence on Batch Statistics During Training
BN heavily relies on each batch’s statistics (mean and variance), which can cause problems when training data is highly variable. The reliance on batch statistics can slow down training and may affect the model’s generalisation ability if the batch sizes are not consistent or if the distribution of data shifts.
Challenges in Recurrent Neural Networks (RNNs)
Recurrent neural networks, which process sequential data, face difficulties applying Batch Normalization due to their temporal dependencies. The statistics calculated across a batch of sequences can vary significantly across time steps, making BN less effective in RNNs than feedforward architectures.
These limitations suggest that while Batch Normalization is powerful, careful consideration of the model type and dataset is essential.
Variants and Alternatives to Batch Normalization
Batch Normalization has revolutionised Deep Learning by improving training stability and performance. However, it isn’t always the best choice, especially in scenarios with small batch sizes or specific neural network architectures like RNNs.
Researchers have developed alternative Normalization techniques to address these challenges, each with unique benefits and applications. Below, we explore some popular variants:
Layer Normalization
Layer Normalization operates on the features within a single data sample, normalising across all neurons in a given layer. Unlike Batch Normalization, it doesn’t rely on batch statistics, making it particularly effective in tasks involving RNN or Natural Language Processing.
This method stabilises training in sequence models, ensuring consistent Normalization even with small batch sizes.
Key Use Case: Layer Normalization can be used in RNNs or transformer-based architectures like GPT and BERT, where sequences are processed one sample at a time.
Instance Normalization
Instance Normalization normalises each channel of a single data sample independently. This method is especially useful in style transfer tasks, where batch-level statistics can lead to inconsistent outputs. By focusing on individual samples, instance Normalization helps preserve style-specific features while normalising content.
Key Use Case: Instance Normalization can be used for tasks like artistic style transfer or image-to-image translation, where spatial consistency in feature maps is critical.
Group Normalization
Group Normalization divides feature channels into smaller groups and normalises within each group. This method balances the granularity of instance Normalization and the generalisation of Batch Normalization. It works well with small batch sizes, as it doesn’t depend on batch statistics.
Key Use Case: Use group Normalization in computer vision tasks with small mini-batches, such as object detection or medical imaging.
Weight Normalization
Weight Normalization reparameterises the weight vectors in a neural network to decouple their magnitude and direction. Unlike other methods, it doesn’t normalise the activations but simplifies optimisation by reducing dependencies on weight scales.
Key Use Case: Weight Normalization can be used in scenarios requiring faster convergence without relying on batch-level statistics, such as reinforcement learning or generative modelling.
Practical Implementation
Most popular Deep Learning frameworks, such as TensorFlow/Keras and PyTorch, offer built-in support for Batch Normalization, making it easy to incorporate into your models. This section will explore how to implement Batch Normalization in these frameworks, including code snippets and best practices.
Batch Normalization in TensorFlow/Keras
In TensorFlow/Keras, you can add Batch Normalization using the BatchNormalization layer. Typically, this layer is placed after the linear transformations (dense or convolutional layers) and before the activation function.
Here’s an example of using Batch Normalization in a simple Convolutional Neural Network (CNN):

Best practices:
- Place Batch Normalization before the activation function for better numerical stability.
- If you need to fine-tune how quickly batch statistics adapt during training, adjust the momentum parameter in the BatchNormalization layer.
Batch Normalization in PyTorch
In PyTorch, Batch Normalization is implemented using the torch.nn.BatchNorm1d, torch.nn.BatchNorm2d, or torch.nn.BatchNorm3d layers, depending on the input dimensionality.
Below is an example of applying Batch Normalization in a CNN:
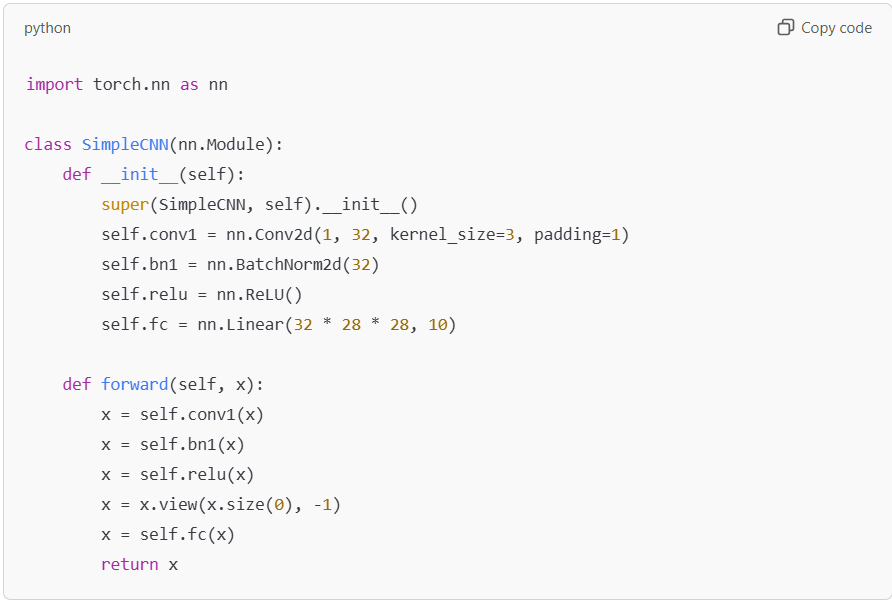
Best practices:
- Based on the input dimensions, use the appropriate BatchNorm layer: 1D for fully connected layers, 2D for images, and 3D for volumetric data.
- Track running statistics carefully during evaluation to ensure consistent results.
Common Questions and Misconceptions
While Batch Normalization has transformed Deep Learning by improving training stability and speed, many misconceptions surround its use. Let’s address some common questions to clarify its role and limitations.
Does Batch Normalization Eliminate the Need for Learning Rate Tuning?
No, Batch Normalization does not remove the need for learning rate tuning. While it stabilises training by reducing the network’s sensitivity to initialisation and scaling, the learning rate remains a crucial hyperparameter.
Choosing an optimal learning rate still significantly impacts how fast and effectively your model converges. However, Batch Normalization often allows for higher learning rates without the risk of gradients exploding, which can speed up training.
Does Batch Normalization Replace Other Regularisation Techniques?
Batch Normalization does not replace regularisation methods like dropout or weight decay. It has a mild regularising effect because it introduces noise due to batch statistics, but this effect is often insufficient for preventing overfitting in complex models. Combining Batch Normalization with dropout or weight decay can enhance model generalisation.
How Does Batch Normalization Impact Inference Time?
At inference time, Batch Normalization introduces a negligible overhead. Since the model uses precomputed mean and variance moving averages, no batch-specific calculations are needed. However, in resource-constrained environments, this slight additional computation may still matter.
Closing Statements
Batch Normalization in Deep Learning is essential for stabilising training, accelerating convergence, and reducing sensitivity to hyperparameters like learning rates. Normalising the inputs to each layer mitigates internal covariate shift, improves performance, and enhances generalisation.
Despite some challenges, such as small batch sizes and RNN applications, its benefits make it a key component in modern Deep Learning architectures.
Frequently Asked Questions
What is the Purpose of Batch Normalization in Deep Learning?
Batch Normalization in Deep Learning stabilises training by normalising layer inputs, improving convergence speed and model performance. It reduces the impact of internal covariate shifts and allows for higher learning rates.
How Does Batch Normalization Affect Model Training?
Batch Normalization speeds up model training by ensuring more consistent gradients. It reduces sensitivity to initialisation, mitigates vanishing/exploding gradients, and enables higher learning rates for faster convergence.
Can Batch Normalization Replace Dropout?
While Batch Normalization provides a regularising effect, it doesn’t completely replace dropout. Both techniques can be combined for better model generalisation, especially in complex Deep Learning models.
Authors
-

Written by:
Karan ThaparReviewed by:



